![]() On Tuesday Intel (NASDAQ:INTC) briefed me, and about forty other people, on some fresh silicon they’d recently gotten back from their fabs. What Intel’s Rajeeb Hazra held up in the air was one of the largest chips I’ve ever seen. This chip is codenamed Knights Corner and is manufactured on Intel’s new 22nm process with 3D tri-gate transistors. (oooh, ahhh) It offers performance of about a teraflop of sustained performance in double precision workloads and is the first real product to be derived from Intel’s MIC architecture. For those of you trying to remember where this chip fits into the roadmap for Intel’s Larrabee project, Knights Corner is what our own Charlie Demerjian calls Larrabee 3.
On Tuesday Intel (NASDAQ:INTC) briefed me, and about forty other people, on some fresh silicon they’d recently gotten back from their fabs. What Intel’s Rajeeb Hazra held up in the air was one of the largest chips I’ve ever seen. This chip is codenamed Knights Corner and is manufactured on Intel’s new 22nm process with 3D tri-gate transistors. (oooh, ahhh) It offers performance of about a teraflop of sustained performance in double precision workloads and is the first real product to be derived from Intel’s MIC architecture. For those of you trying to remember where this chip fits into the roadmap for Intel’s Larrabee project, Knights Corner is what our own Charlie Demerjian calls Larrabee 3.
So in practice what is Knights Corner? At a high level it’s a coprocessor, and at a low level it’s a lot of little x86 cores run at a GHz that are connected through a ring bus. Intel isn’t giving out too many specifics at the moment but based on what they are telling us it’s not that hard to fill in some of the gaps. The thing that makes these little cores different from Intel’s Atom or Xeon architecture is that each of these cores has a very large 512 bit vector floating point unit. Additionally Intel is leveraging its silicon interposer technology to embed GDDR on the package of the chip with full ECC memory support.

So what you end up with is a co-processor with an extreme level of parallelism and a lot of beefy number crunching hardware to back it up. Does this sound vaguely familiar to anyone? Well it should, and for two reasons. The first of which is the similarity of this idea to the way Nvidia’s Fermi is architect-ed. Fermi much like Knights Corner is a co-processor, the major difference between the two being that while both chips are designed to be vector co-processors first and foremost, Nvidia’s Fermi is also designed to be a GPU and Intel’s Knights Corner is not. In addition, both architectures are extremely parallel, but to very different degrees.
To illustrate this point let compare the core count of Nvidia’s Tesla M2090 to Intel’s Knights Corner. The M2090 has 512 CUDA cores, and Intel has publicly stated that Knights Corner has greater than 50 cores. So without speculating too much as to the real core count of Knights Corner cough*64*ahem we can see that there is a major difference between magnitudes of parallelism that each chip is targeting. This raises the question of why. Why would Intel create a Many Integrated Cores architecture that had fewer integrated cores than its competitor? Or conversely why would Nvidia create an architecture that used so many more cores than its quickly materializing competitor? Well that answer flows from the same design goal difference that separates the two architectures on a basic level. Fermi does double duty as a GPU while Knights Corner is purely a vector co-processor.
Editors note: Core count on GPUs is more of a PR effort than actual cores. If you wanted to count cores in CPU-like fashion, Nvidia’s Fermi would be an 8-core chip and DAAMIT’s Southern Islands/6900 would be a 24-core chip. Conversely, if you counted Knights Corner in GPU-like fashion, each of those 64 cores has a 512-bit vector engine. Each GPU ‘core’ can do a single precision flop, making a Knights vector pipe 16 cores, and Knights Corner 1024 cores. Completely coincidentally, that is half way between Nvidia’s and AMD’s current ‘core’ counts, and in the same performance ballpark. You have to love watching PR try to count or even define cores. Now we return you to the regularly scheduled program.
This is also why the middle ground that the Knights Corner design represents between a traditional CPU and a GPU makes it a poor choice as a GPU. Now some of you may be saying isn’t this just Larrabee 3? Well not really, the root of the difference between the two products is GPU functionally, and Knights Corner has none. Larrabee tried to do all of the things that Fermi currently does and keep x86 in tow. Intel wasn’t able to scale an x86 core down to the point where it could fit enough of them on a chip or clock them high enough to give the same level of graphics performance as a conventional GPU. It also wasn’t able to keep power consumption under control. Consequently this is why the version of Larrabee that has been floating around for the last year or so, codenamed Knights Ferry, never went into mass production and why Intel canned the idea of selling its MIC architecture as a GPU.
Instead Intel has presented us with a very fast, very large, and probably rather power hungry, vector co-processor to end all vector co-processors. Let look at the performance angle of this for a moment. The live demo that Intel showed in a secret hotel room hidden away from the rest of the SC11 conference was generally impressive. A single Knights Corner chip was loaded onto a debug board and attached via PCI-E to a dual socket Xeon E5 server motherboard. The Knights Corner chip was cooled by an average sized copper heat-sink with a single high-speed fan. The key point I want to make here is that the silicon was so fresh that Intel had to use a debug board to demo it to us. So think of the 1 TFlop number as a base line rather than an absolute performance level for Knights Corner.
Now let’s us look at the competitive landscape that Intel’s going to be launching Knights Corner into. If we assume that Intel is going to follow its usual product development schedule then we can expect Knights Corner to be launched about this time next year. Most current generation GPUs are made on TSMC’s 40nm process. This is about to change when AMD and Nvidia launch GPUs based off TSMC’s 28nm process in the first half of next year. Now GPU compute performance tends to double when the chips are shrunk to a new manufacturing process. So we can make a rough estimate of the kind of performance AMD and Nvidia will be offering with their single GPUs.
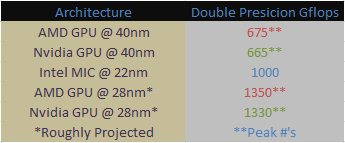
The take away here is that in applications that can effectively leverage the compute power that GPUs have to offer, said GPUs will still out shine Intel’s Knights Corner chip. Additionally Intel could be at a significant disadvantage compared to the GPUs in terms of raw peak Gigaflops. But this is where Intel is going to be pulling out its ace-in-the-hole to woo the HPC community, and that ace is the x86 instruction set.
Every single core in Knights Corner is x86 compatible, and that is something that GPUs cannot match. Using x86 allows Intel to ease the porting of code to Knights Corner by insuring basic compatibility. Conceivably you could run any application on Intel’s Knights Corner chip that you could run on your desktop. Although that would be impractical because chances are that your desktop applications won’t scale beyond 4 cores. But it is possible, and that’s what Intel is counting on to sell its MIC architecture to the HPC community.
Basically Intel is hoping to boil down the choice between its Knights Corner chip and Nvidia’s Kepler chip to a single question. What would you rather code for x86? Or CUDA? To this end Intel invited the Director of the Joint Institute for Computational Sciences, R. Glenn Brook, speak about his experiences with a few Knights Ferry chips and the ease of porting his scientific applications from conventional CPUs to Knights Ferry. The take away from his short talk was that porting existing HPC applications designed to run on CPU nodes to Knights Ferry is very easy because of the shared instruction set and the way that Knights Ferry presents itself to the system. You can configure Knights Ferry, and by association Knights Corner, to run natively as a fully networked Linux system or as an attached accelerator. What this does is allow you to use a message passing interface (MPI) to distribute a workload across both Knights Ferry chips and their system hosts (Xeons). Additionally he made the argument that many of the applications he ported to his Knights Ferry samples would never be ported to GPUs because of cost and complexity of doing so.
With that in mind let’s move back to the question at hand, x86 or CUDA. For those scientific applications that scale well with CPU cores but map poorly to GPUs then Intel’s Knights Corner is going to be your chip of choice. Also if your application is written in x86 and you don’t have the resources to port your code to CUDA then you’ll want to run it on a Knights Corner cluster. But if you need the highest level of performance possible or have an application that maps well to the architecture you’ll be choosing GPUs.
Knights Corner is no doubt an interesting product. It has a long linage inside Intel that can be traced back to 2006 and probably goes back even further. It also has the support it needs to make an impact on the HPC market. Is Intel going to be able to replace the role of GPUs in the Supercomputer with its MIC based chips? No, but for a lot of different applications Intel’s MIC architecture is going to be a good fit. GPUs will still continue to have a place in HPC. But will GPUs be marginalized by Knights Corner? To some extent, but that really depends upon how programmable Nvidia’s Kepler and AMD’s Graphics Core Next (GCN) turnout to be. However the chips end up performing, Intel looks to be well on its way toward building an Exascale Supercomputer by 2018 and to that end we wish them the best of luck.S|A
Thomas Ryan
Latest posts by Thomas Ryan (see all)
- Intel’s Core i7-8700K: A Review - Oct 5, 2017
- Raijintek’s Thetis Window: A Case Review - Sep 28, 2017
- Intel’s Core i9-7980XE: A Review - Sep 25, 2017
- AMD’s Ryzen Pro and Ryzen Threadripper 1900X Come to Market - Aug 31, 2017
- Intel’s Core i9-7900X: A Review - Aug 24, 2017