![]() Intel is taking the whole Software Defined Networking paradigm seriously with the release of two new platforms today. As of now, there are two official Open Networking Platform (ONP) reference designs, one for switches and one for networking servers, plus a SDK to use with it.
Intel is taking the whole Software Defined Networking paradigm seriously with the release of two new platforms today. As of now, there are two official Open Networking Platform (ONP) reference designs, one for switches and one for networking servers, plus a SDK to use with it.
Using x86 servers for network plumbing and control seems a little out-of-place in a world of bespoke hardware, but there is a point to it. The underlying idea is simple enough, generic x86 compute power is cheap, has a widespread developer knowledge base, and can be quite flexible. Bespoke hardware on the other hand is tough to write for, few have any experience with it, and can be very expensive. That said given equal software/firmware, bespoke hardware is usually faster and more efficient, performance per dollar performance is a bit murky though.
This is the balance of power Intel is trying to change with their two reference designs, they are basically splitting the control plane from the data plane and putting them into two different boxes more suited to one task or the other. If you think about it, the idea of using differing amounts of commodity parts in a box makes a lot of sense. A single controller or two can have a global view of the network and make decisions based on what works for everything, not just the node. You also don’t have to have many distributed small controllers that are good enough for the job at hand, you can use far fewer big ones to, theoretically, do a better job.
The data plane is similar to the control plane, a single purpose box that can be scaled without regard to its need for control. It’s view is only local, the control plane does that heavy lifting elsewhere. In essence you go from a many-tiered smart switch/device array to a much flatter layer of switches and a control plane above them. Some of these are more networking heavy, others are more compute heavy, and the mix is up to the customer. In theory it is a good idea and looks kind of like this.
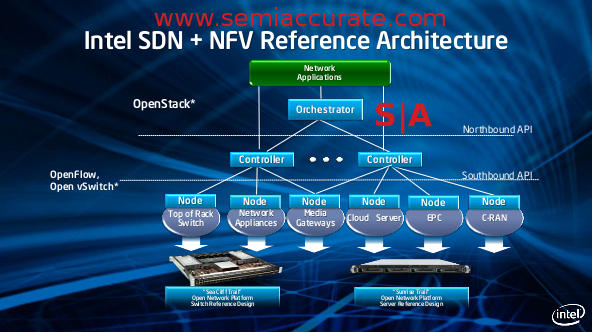
The diagram of the network of the near future
On the down side you have a few problems. First is that you want local control of your switches, it is hard to make wire speed decisions on 40+Gbps links if you have to push packets to a remote server connected with a 10Gbps link then back. For some services this is just fine, others like Deep Packet Inspection (DPI) are a bit more latency sensitive. What this means is that if the Intel vision is a hammer, not every problem is a nail. Do your homework and more importantly know your workloads well before you spend millions of dollars on hardware. In the markets the ONP designs are aimed at, that is not just assumed, it is guaranteed to happen.
If you are trying to make a standard x86 server shuffle network packets around at wire speeds, you may have noticed that they fall really flat. All the little things that make an OS work well and not have massive errors or bubbles in data fetching and saving mean that there is a lot of work going on in the background to cache, buffer, and queue. If you are trying to blast packets around at tens of Gbps with minimal latency, this is the last thing you want to happen, it is tantamount to death.
Enter that SDK we mentioned earlier, it is called the Data Plane Development Kit (DPDK) and it supposedly fixes these little problems. Officially it is an SDK and related software for network plumbing aimed at improving small packet throughput. The official information on it says that it is a user space implementation of memory management, queues/rings, flow classification, and NIC poll mode drivers, but that is a bit dry. It is available for Linux, possibly other OSes too, and costs all of nothing. Best of all it is source available but we aren’t sure if that means open source free as in freedom or just there to look at. Either way it is better than expensive and proprietary, but as you can gather from Windows’ market share in this space, these markets don’t tolerate those kinds of games.
How does the DPDK work its magic? That is actually pretty easy to explain, it essentially doesn’t do all those things that an OS does to maintain state and boost heavy compute oriented performance. This may sound counter-intuitive to a market that is extremely performance sensitive but it does make sense. If you think about it from a switching perspective, a packet comes in, maybe gets checked for consistency, and then gets shoved out the correct pipe as quickly as possible. In an OS, it might come in, get shoved to memory, copied to cache, and then a few other low-level tasks might also be performed.
From the OS perspective this doesn’t just make sense, all those background tasks are all very necessary. From a switching perspective, they are not just a massive waste of time, these tasks also add latency to do things that have no chance of actual use. If you don’t do them you not just save time, but you save energy by not doing pointless work. And that is the point of the DPDK, it is very low-level and knows what parts of the plumbing can be turned off and which can’t. The least technical way of describing what it does is that DPDK allows the user to turn off the things that you don’t need and optimizes the things that are left on for packet throughput, not for general purpose computing. SemiAccurate hasn’t seen any independent benchmarks about DPDK’s effectiveness but it does make a lot of sense from when looking at low-level networking in modern OSes.
That brings us back to the Open Networking Platform reference platforms, server and switch. Intel uses two acronyms to define them, Software Defined Networking (SDN) and Network Function Virtualization (NFV). SDN is the aforementioned splitting of the networking and control planes, NFV is using commodity server hardware to stuff a whole lot of functions that were separate boxes on to one. If this sounds like the same dirt standard server consolidation pitch that has been going on for years though virtualization, you got it.
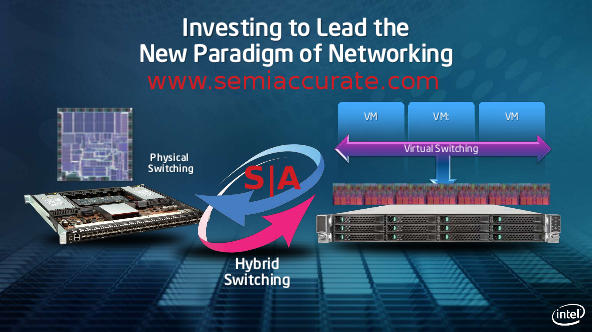
Intel switching types, real or not?
The two reference platforms were code-named Sea Cliff Trail and Sunrise Trail for switch and server respectively. They both try to accomplish much the same thing though very different means. Sea Cliff is a physical switch with a lot of smarts on it, Sunrise Trail is a common old folks home name that Intel sees fit for a platform that does the switching virtually. For some odd reason both use lots of x86 horsepower to do the necessary work.
Sea Cliff is by far the more interesting of the two, and is the first attempt that SemiAccurate has heard of to use the technology Intel acquired when they bought Fulcrum. If you start with an Intel FM6764 switch supporting up to 48 10GbE ports and four 40GbE ports, you have the basis for a pretty dandy little packet pushing box. Connect this to an Intel Sandy Bridge CPU with 1-4 cores, 4GB of DDR3, 8GB of flash for storage, the Cave Creek chipset for some added hardware encryption, compression, and packet acceleration duties, and throw in a couple of FPGAs so you can roll your own management engine, you are ready to party. It looks like this.
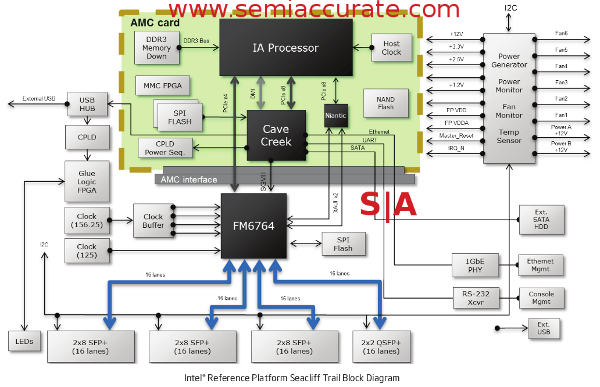
Sea Cliff Trail platform block diagram
The idea is pretty basic, take a switch and throw in enough x86 based packet processing power to do some of the tasks that dedicated hardware used to do. One example that Intel gives is to take a firewall box, VPN appliance, and IDS (Intrusion Detection System) and run those tasks as VMs on the x86 core. The switch can probably categorize packets well enough to send only those that need programmatic love to the x86 side, the rest get shoved out another port at wire speed. This is what Sea Cliff is made for, a network heavy but relatively compute light workload.
Sunrise Trail is just the opposite, aimed at compute heavy but network light workloads. Network light is a bit misleading thought, it has at least two 10GbE ports and most single servers can’t utilize the data that these can push for anything but fairly trivial tasks. Intel calls this virtual switching because it tries to consolidate a bunch of compute heavy network tasks on one box. Data is passed among them with the standard VMWare vSwitch or other virtual not physical networking protocols. If Sunrise Trail sounds like standard 2S x86 server with some 10GbE ports and task specific firmware, once again you get the point.
Both of these paradigms would fall flat on their face if you used a vanilla 2U 2S server, the latency they have when packet pushing is just too high. Some of the problem is hardware/firmware based, some of it is the OS, and some is plain old physics. For the hardware/firmware you have the two platforms aimed at networking that are tuned as far as is practical for the task at hand. For the OS Intel has the DPDK that minimizes this latency through tuned drivers and whatever OS and software tricks it can accomplish in user space. It also can help with lowering latency when communicating between boxes through compression and other unspecified tricks. Physics is still a problem though with no end in sight no matter how much your CEO screams at things.
In the end, these two boxes and the accompanying software are what Intel sees as the solution to most if not all networking problems of the near future. It brings packet pushing, packet twiddling, or both in user selectable ratios. They are both based on commodity x86 hardware, have a large industry knowledge pool, and are relatively cheap compared to bespoke silicon. How well it performs compared to task specific boxes is an open question as is industry acceptance. On paper anyway, Intel’s offering looks more than capable, but this market is based on testing and delivered results not promises. Until those numbers are publicly available, the questions of acceptance and uptake are still up in the air. No matter how it ends up, it is going to be fun to watch.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024