![]() Note: This is Part 3 of a series, Part 1 can be found here, and Part 2 can be found here.
Note: This is Part 3 of a series, Part 1 can be found here, and Part 2 can be found here.
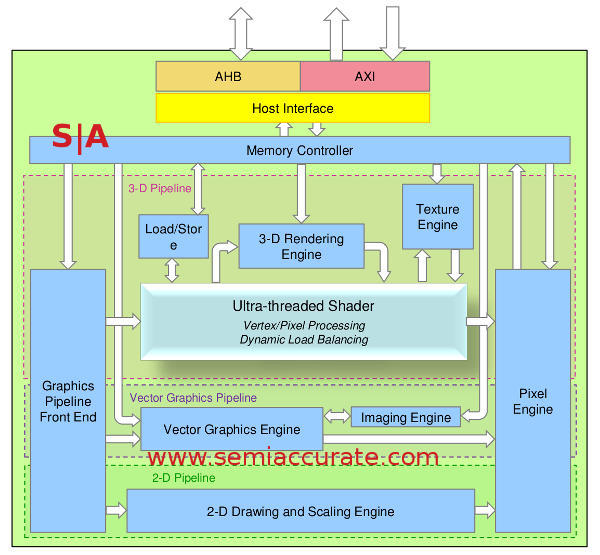
The Vivante GCCORE architecture diagram
3D Units and Threads:
Vivante calls their unified shader block the Ultra-threaded Shader and in this case it does live up to the name. As you would expect from a unified shader it combines pixel and vertex shaders in to a common unit that does both. The single unit does both geometry/lighting calculations and pixel/texel effects. There is no hardware tessellation unit mainly because that is simply a bad idea in a power constrained environment, not to mention there is no mobile API support for it yet. If anyone claims that this is a good idea in mobile, you know what they have to sell and decent battery life is not one of those check boxes.
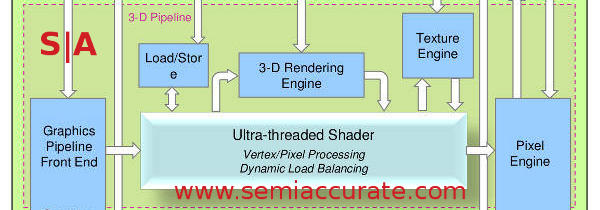
The GCCORE 3D Unit block diagram
Calling a unit Ultra-threaded is a pretty bold move in the GPU world where everything is threaded to an almost silly degree. In this case the Ultra-threaded name is not much of a stretch with each GPU core able to handle up to 256 threads. Switching between threads is round-robin unless there are dependencies for a thread. In that case the thread is skipped until the dependency is resolved which makes a lot of sense.
That many threads would hide an enormous amount of latency in a scalar CPU but in the GPU world with up to 16 Shader Cores that number can be consumed in a fairly small number of clock cycles. As you would expect the front end of the shader unit dynamically balances the loads, for GPUs that mostly means parsing tasks to whatever unit is free at the moment. The pool of 256 possible threads should mean there is a fair number of tasks that should be available to parse.
Each of those shader cores is made up of a Shader Unit Quantum, and the architecture will be familiar to anyone who follows GPUs. In the maximum configuration there are five units, two 64-bit wide ADDs, two 64-bit wide MULs, and one transcendental, it kind of looks like AMD/ATI’s older VLIW5 architecture with four of the pipes fairly limited. As you would expect from a vector architecture each of those 64-bit units can do 1*64, 2*32, and 4*16 making a SUQ capable of doing between 5 and 17 ops per cycle. With 16 SUQs per SC, that would be 80-272 ops depending on precision. That means a 4 GPU core device would have between 320-1088 ops per clock, not bad throughput for a mobile device.
Remember that part about configuration? The Ultra-threaded Shaders can have between 1-16 Shader Cores each so that part is pretty straightforward. Where Vivante’s architecture breaks from the expected is that the SUQ is also configurable. ADD and MUL are effectively 2 * 4 16-bit vectors wide, but if you only need one you can do that too. For the seriously masochistic SoC designers out there you can even configure the GPU with a 1-wide ADD unit but if that is all you need I can’t see why you would want a GPU in the first place. Lets just leave it at the Vivante architecture will scale to the numbers you need it to and that is what we mean by configurable.
The two last parts of the 3D unit do more or less what they are named with the 3-D Rendering Engine doing, wait for it, 3D rendering tasks. Those would be the higher level culling, depth culling, rasterization, and pixel pushing. This is fancy wording for things like taking a higher level primitive and subdividing it in to triangles that the shaders can better parse, computing slopes for coloring, texturing, and other related attributes, and then putting the pixels in the proper places. If you are not familiar with how a GPU works at a low-level, this is the same thing they all do, nothing really fancy here.
Working hand in hand with this is the Texture Engine(TE) that does, well you probably guessed texturing. The other units, most likely the 3-D Rendering Engine will request a texture from memory and that goes in to the TE. There it is oriented, interpolated, filtered, washed, conditioned, and blown dry before it is passed on to the shaders as data in the correct form. As you can see from the links, this unit works hand in hand with the memory controller and takes most of its data in from external sources.
For the technically inclined the TE can do displacement mapping, bump mapping/surface normals and has a patented LoD algorithms. If you recall we keep harping on about precision when we talk about Vivante and LoD is one area that precision really matters. The GCCORE can do LoD with the full 32-bits of precision and then the patented part transforms it in to log space with no loss of accuracy. This is a little on the basic side so if you don’t understand it already you can read up on it here. Yes that was a joke, at least the part about being basic the link is quite valid.
Vectors, GPUs, and Standards:
The next unit is an odd one at least by mainstream desktop standards, a full vector graphics engine. While I won’t ever complain about vector graphics and love my Tempest machine to death, there is little call for vector graphics support in mainstream GPUs outside of some specialty sectors. Those sectors that want OpenVG 1.1 support may be few but one of them is automotive and that is one heck of a lucrative niche. Better yet since the Vivante architecture is so configurable that if you don’t want hardware vector support you can just leave it out.

Vector images look a lot like the above diagram of the Vector Unit
The two parts of this pipe are the Vector Graphics Engine (VGE) and Imaging Engine (IE) and both do what they sound like. VGE puts up the vector graphics, basically lines, and the IE paints them with pixels and textures/fills. To go back to the arcade analogy the VGE is like the lines in Star Castle and the IE is the colored overlays to make it seem not monochrome. Actually that is a terrible analogy, think more coloring book and crayons. The IE can also do bilinear filtering and has a full hardware filtering engine should you need it. In any case you either need the Vector unit badly or you don’t want it, there is little case for a middle ground.S|A
Note: The next installment will cover the 2D and Composting Engine.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024