![]() A lot of people have a fundamental misunderstanding of AMD’s PowerTune 2.0 which is unfortunate because the tech is pretty simple. The biggest problem is that people don’t even try to understand what it does or why.
A lot of people have a fundamental misunderstanding of AMD’s PowerTune 2.0 which is unfortunate because the tech is pretty simple. The biggest problem is that people don’t even try to understand what it does or why.
The basic premise is that fixed clocks speeds are a thing of the past, if they are not pointless at the moment they will be soon. Almost no one out there actually understands why this is a necessity much less how it functions, then work themselves up in to a frothy lather debating misunderstandings. Much of the so called ‘debate’ around the subject is a volatile combination of pure ignorance tainted by borderline religious viewpoints about certain manufacturers, facts be damned. Lets look at the tech in a futile attempt to dispel some of this willful ignorance.
In the distant past chips were sold based on clock speed and binned based on the highest clocks they could run at. When you are talking about low single digit hundreds of MHz, a 33MHz bin was a big and noticeable deal. By the time clocks hit 3GHz or so, 33MHz is rounding error and 100MHz bins were probably not worth paying a significant percentage more for.
While clock speeds were still a differentiator they were far less of a selling point because a 20% difference in performance between bins was no longer possible and 3% added clock was not worth 25% added price tag. Somewhere along the line core counts per die and/or sockets multiplied and clocks dropped quite a bit for mainly thermal and power reasons. Performance went up per socket, then leveled off, and eventually it often went down for non-server workloads. Intel sold Sandy-Es to consumers with only 6 of the 8 cores active for this reason, a good performance trade for users.
Early on in the dedicated mobile chip era, that would be during the Intel Banias, Dothan, Conroe, and Merom era, call it 2004-2006 or so, something changed. That something would be how Intel binned chips. Before these parts the simple binning of how fast can it run was modified to a variant mainly for mobile devices, how fast can it run within a set power budget. This was a result of the out of control power use during the late AMD K7 and Intel P4 eras. These CPUs were just too hot and power-hungry and that became somewhat of a limiting factor.
Even here power was a secondary factor though, the binning flowchart was a simple: 1) Can it run at X MHz? 2) Can it do so at under Y Watts? Even with this secondary metric it was really a one dimensional binning process because speed is what sold. If you really wanted to be charitable you could call it 1.25 dimensional binning, but certainly not two-dimensional.
If memory serves the first device to go with two-dimensional binning was Intel’s Conroe CPU even if this was done silently. Regardless of when it happened the idea was to bin on power as well as performance, essentially rate the device on a performance per Watt scale. This is very different from a clock number under a given wattage, even though they sound similar the difference is fundamental. Intel was binning mobile CPUs on efficiency grounds, not clock based performance, and selling the more efficient ones at a significant premium. A high-end mobile SKU might run at the same clock as a lower end SKU but the more expensive one used less energy to do the same work. In a laptop this was usually worth paying for too, binning had gone two-dimensional.
Around this time another factor came in to play, variable clock speeds. The idea is simple enough, at low loads make the chip run slower than its maximum speed to save power, underclocking on the fly. This worked well and methods to do it have become more and more sophisticated as time passed, switching between clock states became faster and faster with latencies sometimes dropping an order of magnitude or more between generations. This helped reduce power draw but TDPs still crept up.
The next major fix was what was called power gating or dark silicon. The idea is to turn off portions of the chip that aren’t being used. For multi-core CPUs if you are not using one core, turn it off. That lead to more and more granular power gating with every passing generation. What was a core or an accelerator gated off became pipelines, pipeline stages, and then ever smaller functional blocks. As things stand now most CPUs have more of their logic turned off than on and it is usually off for more time than on. While this helped keep power use under control it still crept up, just more slowly than before.
One last technology is the so called ‘turbo’ modes, in essence it overclocks instead of underclocks the CPU. Earlier variable clock mechanism basically measured load and if it was low enough, ramped clocks back. Turbo is vastly more sophisticated, it measures load, energy used, and temperature to calculate on the fly how much headroom is available under the TDP for the device. If there is any power left to use and temperature is within bounds, it will let the CPU run faster than it’s rated clock speed.
One real problem is that this has to occur in a “thermally insignificant time frame”, basically a really short time so the chip won’t cook itself and/or burn out supporting power circuitry. In essence the CPU needs to determine how much power slop there is really fast then ramp clocks up or down equally quickly to take advantage of that headroom. Analog temperature and power measurements are far too slow to work here, you simply can’t read the result fast enough for the CPU to effectively use. Worse yet by the time your sensors read a dangerous temperature it may be too late to throttle back before damage is done.
This resulted in a digital power management technology that doesn’t measure power and heat, it calculates it. Knowing the design and process of a device you can do things like calculate that a 32-bit add will flip X transistors in area Y and burn Z mW in the process. You can calculate based on the work done by the device how much power it is or will be using and know the energy use and thermal loads in almost real-time. From there you can do the really simple math to figure out how much headroom you have left under TDP.
This may sound easy but there are dozens of variables that go in to making it work not to mention having to characterize your device in borderline crazy detail. That said it is a must on modern devices, any of them worth considering do it as a matter of course. With each new generation the latency between clock steps goes down, clock steps become more granular, and the controlling algorithms are more accurate.
As it stands now almost all modern CPUs, GPUs, SoC, and other chips are binned on performance per Watt, can drop clocks to fractions of their base clock, turn off logic blocks in a fine-grained manner, and can ramp clocks up on the fly to take advantage of any available energy left under the TDP. Reaction times are almost on a per-clock basis now and precious little work is done needlessly. In short, we are fast approaching the point where the TDP is almost all consumed by transistors flipped for useful work or unavoidable leakage, the overhead is almost zero.
So what does this have to do with GPUs? Where does PowerTune 2.0 come in? CPUs are really good at running fast with relatively narrow workloads, IPC is usually in the low single digits. GPUs are the opposite, they run relatively slowly but are effectively really wide, parallel devices vs more serial CPUs. They can and do manage a lot of useful work per clock and graphics are one place where most of the device can be lit up at once. GPUs that are doing their normal job have a much higher percentage of the die doing work than a CPU does.
Modern GPUs are also relatively similar to CPUs in power saving technologies, maybe a generation behind but not missing any of the fundamental pieces. In essence almost every transistor flipped on a GPU does useful work just like a modern CPU, the efficiency differences are measured in very small percentage terms. Since more of the GPU is lit up at once, this usually leads to GPUs consuming a lot more power per unit area than CPUs. For this reason GPUs hit the power wall long before CPUs, and this has effectively capped their raw performance.
For the past few years GPUs have been going up in performance by tens of percent rather than the doubling every year of past generations. This is because die sizes have hit a wall, economically for some, reticle limits for others, power based for all, and a combination of the three in many cases. Power is capped at about 300W for modern PCIe based GPUs due to power supply limits, cooling, and related problems. Related to this is that transistor shrinks have slowed dramatically and the normal halving of power per transistor flip every shrink is slowing too.
As the designs become more efficient the number of transistors on a die are almost linearly related to the power used. If you add more transistors you add an equal proportion of power use. If you turn them off, clock gate, or downclock them, performance takes a similarly linear hit. This is the long way of saying if every transistor is useful for every clock, turning them off will only hurt performance, adding more will only increase power, and more die will only hurt efficiency while costing more. This is the effect of the power wall coupled with a very efficient design.
Going back to chip design there are three fundamental trade-offs in designing a device, performance desired, power used, and temperature. You can make a chip faster through higher clocks, more sophisticated architectures (for higher clock speeds), or wider execution paths. Some of these may work for your intended device, others may not, and all three can be done in the same device if needed. If you want speed, you can get there by throwing energy at it to one extent or other with rapidly diminishing returns.
Unfortunately increased energy input means increased heat out without the same diminishing returns as performance, and heat is a serious detriment to performance. For the most part the hotter a semiconductor gets the more it leaks and more energy is required to perform at the same frequency. A GPU operating at a fixed 1GHz with junction temperature of 100C will need significantly more Watts to do the same job as the same part cooled to 20C. This is a classic trade-off, some parts are designed to tolerate high temps, others are designed to operate most efficiently at high temps, others just like it as cool as possible. Operating temperature is a classic engineering trade-off, most consumer parts seem to cluster around 80-100C operating temps but we can’t stress enough that this is a trade-off not a physical rule.
If you want to run your GPU at -70C it is more than possible, maybe not feasible or sane but quite possible. You will probably spend more money on a cooler than you spend on silicon, and consume far more energy in keeping the temps that low than you can ever hope to save, but it is possible. For some reason there is no consumer product on the market that does this, do read a lot in to that.
The last of the three is effectively higher speed through more transistors. This can be adding gates to remove clock bottlenecks and/or lessen the amount of work done per clock cycle, or add more pipelines, cores, or logic to get more done per clock. All of these options add transistors and if a GPU is efficient like all modern ones are, that just means more power burned to get more work done. CPUs went multi-core when it became clear that you got more performance from two cores than one bigger one with 2x the transistors. GPUs because of their parallel nature have a very different set of trade-offs than CPUs though, what works for one is not optimal for the other.
A lot of you might have noticed that modern desktop GPUs have all converged on a similar point, die sizes in the 350+/-50mm^2 range, TDPs of 250+/-50W, and clocks clustered in the 900MHz-1GHz range with an end result of very similar net performance. This isn’t by chance either, it is careful engineering trade-offs that all have the same basic transistors to play with. As power management architectures evolve, the result is more and more efficient use of those transistors. Performance won’t go up radically with more efficiency, the basic shaders that do the work don’t change much, so in effect the ranges above will just narrow. There are a few outliers but performance per Watt or performance per area is nowhere near as good as the sweet spot GPUs.
If a die shrink drops transistor area by 50% without changing power used per transistor switch, the die size would halve but performance would stay about the same barring any thermal density effects. If transistors didn’t shrink at all but power use per flip went down by 50% (TSMC/GF 20nm -> 14nm ‘shrink’ anyone?) then you could double the die size and use the resulting transistors for 2x performance from 2x the area. 50% shrink with 50% power used per switch would mean the same rough die are with 2x the performance. This is the long way of saying without the government releasing all that alien tech stored in Area 51, GPU performance is more or less bound to process tech advances at this point, minor incremental gains are the best we can hope for otherwise.
On that depressing note let’s go back to the erstwhile point of this article, AMD’s PowerTune 2.0 tech. If GPUs are binned on performance per Watt, can clock up, down, sideways, and calculate energy use and temperature based on the instruction stream already, what does it do? How can it possibly increase performance?
If you consider high performance to be the maximum possible clock speed, a fair assumption in the GPU world, then PowerTune 2.0 can do a lot. A fixed base clock in this context is pointless, when you are not pushing the GPU hard a modern GPU will be running at a small fraction of its base clock. If you are gaming the turbo modes will use as much of the available TDP headroom as possible to jack the clock as high as possible for as long as possible. A graph of power and clock speeds should have the power draw pegged at the TDP almost exactly and the clocks varying by a little bit over a very small time frame. Take a look at the performance chart AMD showed off at the Hawaii launch a few weeks ago.
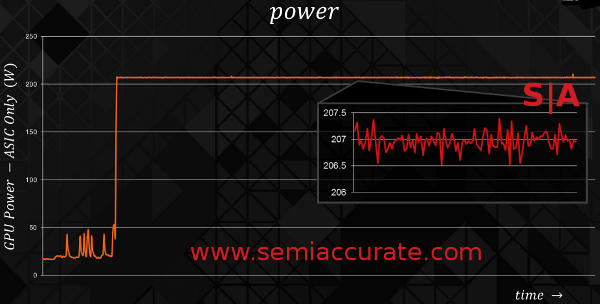
AMD GPU power use over time
So power is variable but held in a tight range, performance should vary with roughly the same range as power, and in theory that is the end of it. Since we live in reality rather than theory, the card heats up. Heat leads to more leakage and less efficiency, higher fan speeds mean more power used by the card but not the ASIC, and so less of the total card energy draw ends up as useful work done. Traditionally the card will slowly heat up until it hits a preset limit and then throttle back hard until it cools down, they throttle back up. The end result is a brutal stair-step pattern that gamers recognize as uneven performance, dropped frames, and other unwanted behaviors. The graph of it looks like this.
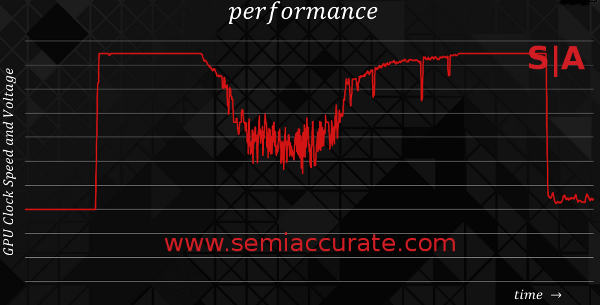
This is why a thermal trip stutters frames
In the end this works but it is really sub-optimal. When things throttle back thermally the card doesn’t die an early death but the user experience rhymes with butter trap. Additionally it is really wasteful, efficiency drops off precipitously and that is never good. Any uneven performance, power use, or temperature spikes are to be avoided if you want happy users and maximum performance.
That is what PowerTune 2.0 does, 1.0 was effectively turbo, 2.0 brings both board power and temperature in to the mix. Like Intel did with its platform power states a few years ago, AMD is doing with GPU board power. It starts with a newer Serial VID Interface chip, power controller for the layman, that can switch much faster, more granularly, and over a wider range than before. This new part samples at 40KHz, transmits data at over 20Mbps, has 255 voltage steps between 0 and 1.55V (6.25mV steps for the pedantic), and can switch between power states in 10 microseconds.
More importantly it can read the state of the board and the power draw there. Memory, passive components, and the fan are all part of the board TDP calculations now, not just the ASIC itself. GPU power management means everything on the card, not just the chip. This is one of the key parts of PowerTune 2.0.
The other key part is the realization that temperature is not just an engineering trade-off at design time, a fluctuating temperature is both wasteful and can destroy the user experience. What do you do about that problem? You pick a maximum junction temperature that you want the chip to run at for efficiency purposes, basically leakage balanced off against cooling/fan power draw, and pin it there. This means temperature is no longer a variable that will climb, trigger a thermal safeguard, then throttle performance back. If the cooling solution is adequate, all you need is a very basic fan controller to vary speed a bit when needed and voila, fixed temperatures.
As temps climb a bit, fans throttle up and should reach a steady state under most gaming conditions. This means temp is fixed and fan power draw is fixed too. Now the GPU ASIC should be able to have a power budget that is essentially (board TDP) – (fan Wattage) – (other board power use). Since the fan power draw is now static the ASIC has a fixed TDP to work with too. No thermal peaks also means no unwanted throttling and the GPU should be able to operate in a very tight clock range.
One problem with this is production variances. A chip is binned on performance per Watt but those bins are pretty gross. An AMD Hawaii/290 has two bins that are both at fixed TDPs and sort of fixed clocks even though that is mostly irrelevant now. These two groups are really based on units fused off more than any performance metric though, shader count is the defining factor. So that means any production variances are seen as where the clock settles down once a steady state is reached. Luckily modern semiconductor fabrication processes mean this variance is pretty small.
As the Tech Report found out, when the fan speed is limited like the 290x is in non-Uber Mode, you can have a fairly large variance between cards. Once the fan speed is jacked up that 5-10% difference becomes essentially zero. Why? Simple enough, in the real world you have physical differences in the cooling heatsink, fan, thermal pad, physical contacts between pieces, and movement during shipping and assembly. All this adds up to tolerance differences and that can lead to differences in cooling efficiency which are far greater than any semiconductor differences.
If you tweak a heatsink a bit the temperature change can be noticeable, not a problem unless you have a card that is tuned to take advantage of every last Watt, degree, and clock. If the cooling solution can’t dissipate the heat generated at maximum Wattage you will fall back to the old cycle of thermal throttling and stuttering but in a far less extreme manner. This is exactly what appears to be happening in the case of the 290X.
This variance can be taken care of by upping the cooling performance, basically allocating a few more Watts to the fan. If AMD engineers did their math right, that should still allow the parts to run at max clocks only with a slightly higher fan speed. This means more noise but that is what you get with a high-end gaming GPU at peak performance. It looks like AMD’s reference design fans are borderline adequate, something that will thankfully be a thing of the past in a few weeks.
In the end, PowerTune 2.0 fixes one of the three variables, temperature. That leaves power and clocks to fluctuate. Since power is fixed by design (or PCIe specs in some cases), clocks are effectively pinned at a given point. This point is essentially overclocked to the maximum possible frequency given the other fixed constraints. AMD says the Hawaii/R9 290 family can modify the clocks on a per-clock basis, good luck topping that with a manual switch. For any given set of temperature and wattage values, without other physical constraints PowerTune 2.0 can extract the maximum possible performance out of a GPU on a clock by clock basis. And now you know how and why.S|A
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024