![]() AMD is pulling back the covers on the upcoming Carrizo CPU with at talk at ISSCC 2015 about power savings techniques. It starts with the high density libraries from Hot Chips 24 and goes into detail from there.
AMD is pulling back the covers on the upcoming Carrizo CPU with at talk at ISSCC 2015 about power savings techniques. It starts with the high density libraries from Hot Chips 24 and goes into detail from there.
Lets first talk about the overall structure of Carrizo, it has two Excavator modules, aka four CPU cores, and four GPU modules, aka 256 shaders. While this isn’t explicitly stated, if you cross-reference slide 13 which says “eight Radeon cores” with slide 4 showing four CPU core, well the math isn’t that complex. It looks like this.
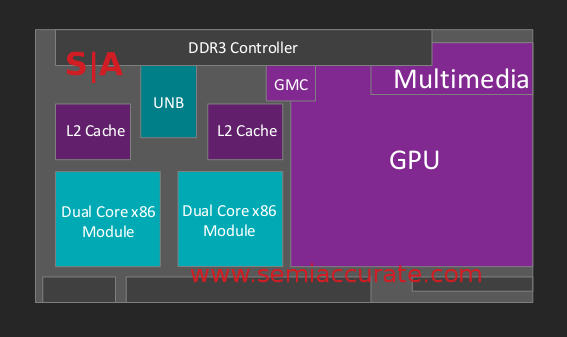
Really rough Carrizo block diagram
One thing not really clear on the block diagram above is that Carrizo is a single die design, almost SoC-like because it integrates the Southbridge (SB). When asked about the wisdom of pulling in the SB onto the main die instead of an MCM, the answer was pretty convincingly weighted toward single die. Doing one chip is cheaper, uses less board space, smaller and less complex than MCMs, and no assembly losses either. The number of transistors needed for the SB functionality is so small now that it doesn’t add much cost either, plus there are no legacy fabs for AMD to fill. On top of that you get the SB functions on a current node and they are under the control of system power management for massive power savings.
This allowed AMD step into the modern world of system level power savings with their S0i3 state, effectively S3/Standby for the entire platform. Intel has been doing this for years now, AMD hasn’t and it showed in idle power numbers. While S0i3 won’t catch AMD up to Intel in this regard, it should get them firmly into the territory of ‘good enough’. At last AMD will have a fairly competitive mobile part with graphics that work right on games, not sure if this is a, “Yay!” or a, “Finally” but, well, take it either way.
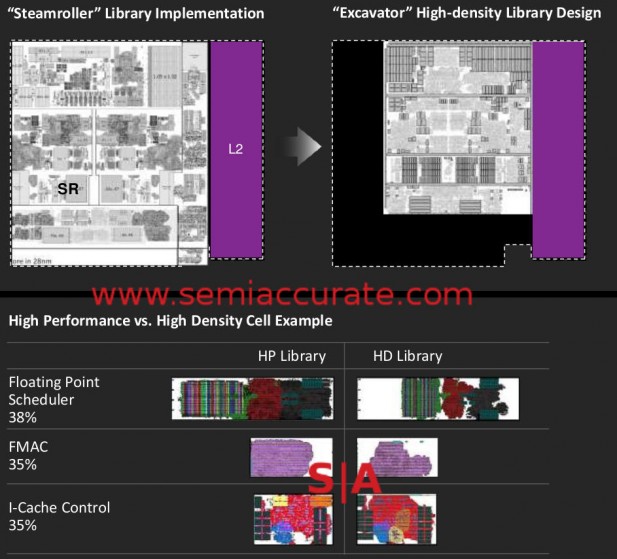
High Density Libraries mean smaller blocks
The most major change to the design of Carrizo was the use of so called High Density Libraries (HDL) for the cores. This is a long-standing technique on the GPU side that packs in more transistors per mm of die area through tighter metal layers. For the record, AMD uses 12 metal layers and in Carrizo there are eight 1x pitch layers. Those versed in CPU design will realize that this costs absolute speed at the top end but gains quite a bit of space and potentially power efficiency everywhere else. If you look at the lower levels of metal, you can immediately see the difference. (Note: This is not the full stack picture)

Some of the metal layers showing HDL difference
What this means is compared to the earlier Steamroller core, Excavator clocks better for a given wattage until nearly 20W per core pair. Since work done per unit power consumed is efficiency, Excavator is significantly more efficient than Steamroller. It is also significantly smaller, 23% less area used on the same process, not bad at all. On the GPU side, HDL is always a win versus high performance libraries (HPL), the graphs never cross over. The net result looks like this.
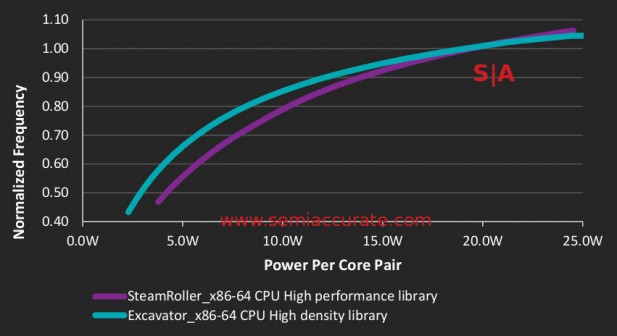
Efficiency curves of the two libraries
What is probably more important is how this change affects the overall design of Carrizo, it is a comprehensive but subtle change. The device itself was re-architected to reflect the new realities of the metal layer structure, essentially the CPU is more GPU-like and to a lesser extent the converse is true. This means the Transistor choices of the CPU look more like a GPU with far fewer high Vt transistors on one side plus far fewer nominal Vt long length transistors on the other. (Note: This technically is from a comparison of 32nm to 28nm CPU cores in an earlier AMD ISSCC paper but it should be broadly similar to HDL vs HPL on the same process).
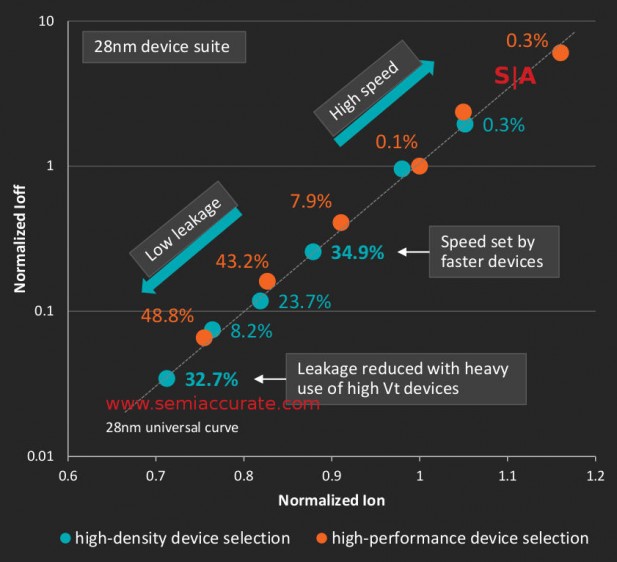
Power use vs frequency with the two libraries
If you change a device to reflect the GPU-like metal layers, it becomes more GPU-like in overall operation. As the slide above shows, this also has a very interesting effect on binning, instead of a big frequency hump and a long tail with HPL, HDL gives you a much more even frequency spread. That part is kind of obvious but the interesting part is that there are more usable devices the mid-range speeds with HDL but the absolute end of the tail is shorter.
Next up is something AMD calls Voltage Adaptive Operation or AVFS, it is said to save up to 19% CPU power and 10% GPU power. In a modern CPU, power delivery is uneven with spikes and droops all over the place. If an instantaneous power droop falls below the Vdd threshold, the transistor doesn’t work and bad things happen, really bad. Because of this you need to keep average power high enough that the bottom of a droop stays above the minimum necessary Vdd. This wastes a lot of power but keeps things from crashing or worse yet, silent errors.
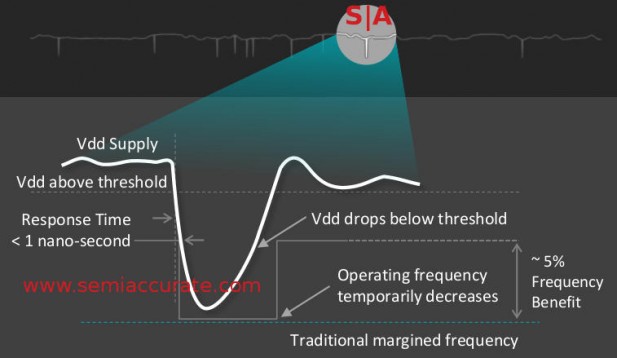
Voltage droops in line form
AVFS starts out by lowering the voltage of normal operation to the point where everything but a big droop runs like it should but a droop would cause errors. This explains the power savings but not how errors are prevented. That part is pretty simple, they detect the droops in realtime and drop the CPU or GPU clocks until the droop is below the Vdd threshold for the new frequency. Once the voltage returns to normal, the clocks are ramped back up. It is a proactive system with a stated response time of <1ns, enough to be completely unnoticeable to the user and likely not even visible to benchmarks. You could also take the power savings as a frequency gain, AMD claims AVFS is worth about a 5% clock increase. Doing this needs a lot of strategically placed sensors, each Excavator core has 10 AVFS modules which monitor about 500 speed paths.
Frequency shifting is hard for a given area but damn near impossible across a die with multiple CPU and GPU cores. Carrizo obviously only drops the frequency of the blocks it needs to when AVFS senses a droop but that has knock-on effects for memory, busses, and all the other components of the chip. Luckily because of the it’s APU heritage, all the major blocks of Carrizo operate asynchronously so you can play with clocks on short notice without screwing up a lot of other blocks. This means system stability during such changes is not a problem.
AMD is claiming that Carrizo packs about 3.1 billion transistors, 29% more than Kaveri, into the same die area as Kaveri. The Excavator cores themselves are 23% smaller than Steamroller but have a 5% higher IPC and consume 40% less power. Overall system energy use is down 20% or so and everything is updated. If you have read this far, you probably realize that we had no place to work in the fact that Carrizo has H.265 support and a claimed 3.5 increase in transcode performance, a handy number in light of the 4K vs 1080p increase, eh?
When looking at individual statistics one thing might have passed you by, the big picture. Each component is more efficient and overall power is saved, but what about the real world use cases? This savings and efficiency means that you can keep more of the GPU running at higher frequencies or at full turbo clocks for longer. All of this is of course necessary for HSA type applications, mixed CPU/GPU compute scenarios are where many chips fall over. AMD is claiming that Carrizo is going to be the first HSA 1.0 compliant CPU so the added efficiency should actually show up in the real world. It isn’t just about peak numbers, use cases do matter to many people.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024
- Doogee (Almost) makes the phone we always wanted - Mar 11, 2024