 Today Intel finally fills out their Haswell line with the new 4+ Socket Haswell-EX now called Xeon E7v3. Unlike many past -EX launches, this time the interesting stuff is in the details, the main platform has quite a bit of carryover from the E7v2.
Today Intel finally fills out their Haswell line with the new 4+ Socket Haswell-EX now called Xeon E7v3. Unlike many past -EX launches, this time the interesting stuff is in the details, the main platform has quite a bit of carryover from the E7v2.
To start off with the new Haswell based E7v3 is compatible with the boards from the older Ivy Bridge based E7v2, quite the impressive feat. Much of this is due to a very simple and rather fortuitous feature of those boards, the voltage regulators. Like smaller Haswells, the big Haswell-EX has on-die voltage regulators aka FIVR. If you are not familiar with the tech, we wrote it up here.
On the surface, FIVR would seem to mandate a board change, moving the VRM from the motherboard to the die itself is not a minor undertaking. Instead of all that work being done on the board as it was on Ivys, how can it be moved without board changes? The fortuitous part comes in because the Haswell voltage requirements are in the range that the Ivy VRMs can supply. With a firmware update, Haswell-EXs are happy to live on the Ivy-EX boards.
Luckily for users who plan on upgrading their E7v2s to E7v3s, a count we would put at roughly zero +/- a small number, doing this is fairly efficient. The VRMs on the board are usually quite efficient and if not off or bypassed, they waste very little energy. The sharp-eyed among you may have noticed that the TDPs of the E7v3s are up a rather uniform 10W over their v2 counterparts, this is almost entirely due to FIVR. Pulling the VRMs on die pulls 10W onto the die but also pulls 10W off the platform. Since this is TDP it is a worst case, we don’t think there will be much actual difference in practice and net platform power use should be about the same or lower.
So the platforms can be exactly the same, but the important bit is that they don’t have to be. E7v3s support DDR4 but the Ivy based v2s don’t. As you might guess if you want to use DDR4 in your 8-socket Haswell-EX based gaming rig, and for reasons we will get into later you really do, you obviously need a new platform. As if by coincidence, Intel has just such a platform ready for you and OEMs will no doubt follow with their own takes in short order.
The biggest difference between the two is the VRMs or lack thereof and the DDR4 slots instead of DDR3. Some OEMs may not redo their DDR3 platforms but the DDR4 variants will have to be completely redone. You might recall that the older E7v2s had a memory buffer that connects to the CPU and effectively fans out to DDR3 slots. Haswell-EX has four of these but they move up to a second generation part which supports DDR4. The older ones are compatible too but, well, you are better off with the new ones.
There are two new memory buffers were formerly known as Jordan Creek 2 but are now called the ever so much more memorable C112 and C114. The main difference between them is the number of DIMMs per channel they support, two for the C112 and three for the C114, but two channels per buffer either way. If you do the math that means eight DDR3/4 channels per socket so with 64GB LR-DIMMs you can cram up to 1.5TB per socket. That would be 6TB for a 4S system, 12TB for a 8S system or about enough to avoid swapping during even heavy web browsing. If you want more you will need to use third-party chipsets.
Things start to get interesting when you look at the two modes the C11x siblings have to offer, performance or lockstep. In Performance mode the link between the CPU and the SMI (that would be the third name for the memory buffer, fourth if you count ‘memory buffer’ itself) runs at 2x memory clocks or a max of 3200MT/s. That of course means memory is maxed at DDRx/1600. In Lockstep mode the SMI link runs at DDR4 clocks or a maximum of 1866MT/s, 1600 for DDR3. Since there are two channels of DDR4 per C11x, Lockstep mode leaves a lot of memory bandwidth on the table.
So why would any sane customer use Lockstep mode? Reliability aka the big difference between the E5 and E7 lines, other than socket counts of course. In Performance mode, each DDR4 channel is independent, Lockstep both channels are seen as a single wide unit operating in lockstep. Now do you see how they got the clever name? This width allows you to do quite a bit of additional error correction. In performance mode with x4 DIMMs you get SDDC+1 (Single-Device Data Correction +1 bit) but x8 DIMMs gets you only SECDED. Lockstep mode however allows for DDDC+1 (Double-Device Data Correction +1 bit) with x4 DIMMs, SDDC+1 with x8 DIMMs. In short you get significantly better error correction when using lockstep mode but pay for it with about half your bandwidth. If uptime is a concern, you go with Lockstep, if massive memory capacity and bandwidth is why you went with the E7v3, Performance mode is your answer.
Remember when we said you really want to pair your Haswell-EX with DDR4? The first of those reasons is because the new memory controllers support parity and error recovery on the command and address paths, not just the data paths like E7v2. This is a massive gain but only works with DDR4 so speed and energy use aside, DDR4 is the way to go. If you don’t think so, consider that a parity error on DDR3 is fatal, on DDR4 it is recoverable.
But wait, there’s more! Yes I know it is hard to believe but there are more improvements to the memory subsystem too. The first of these is multiple rank sparing which does exactly what the name sounds like. You can now specify more than one rank as hot spares so when the memory controller sees too many errors, it fails over to a spare rank and deactivates the error prone one. Now you can pull off this trick multiple times per memory channel without downtime, a major win for those who care about such things. That would once again be a large portion of the E7 customer base.
If that wasn’t enough we also now get address based memory mirroring, a nifty new feature that again does what the name intones. You can now designate memory regions for critical structures like the kernel, VMM, and addresses of that cool new torrent side, and they will be mirrored. Unlike the older methods, this doesn’t have to be a whole channel, you can pick only the addresses you actually need mirrored. This saves a massive amount of memory, instead of mirroring halving your total space, it now only has to take a small chunk. If you want specifics, each controller can have one mirrored address range and it works at a granularity of 64MB.
Just with the memory benefits alone, the new DDR4 based platforms are vastly better, more reliable, and more cost-effective than their DDR3 counterparts. Most of the new benefits only work with DDR4 so the choice really is a no-brainer, but that is only the platform, the new CPUs have some goodies too.
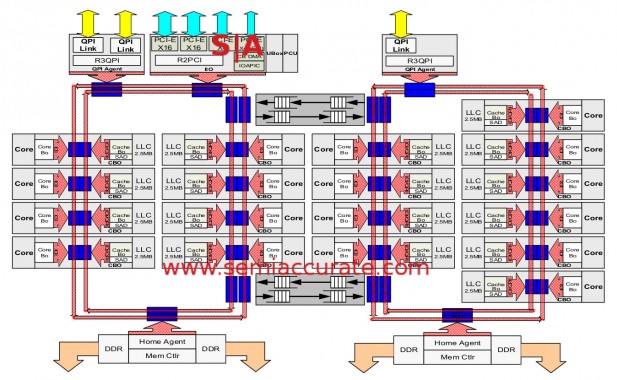
The die overview with one typo covered by the watermark
If you look at the diagram of the Haswell-EX CPU, it looks exactly like the diagram of Haswell-EP. Part of that can be ascribed to the type, there are only 32 PCIe3 lanes per die on -EX, not the 40 found in -EPs and mistakenly in the plot above. The major difference is the ring stop on the second (rightmost) ring which contains another QPI link. This is of course how the -EX scales to 4/8 sockets while the -EP only goes to two. Unless Intel decides to do away with that arbitrary restriction like they did on Romley, but we won’t question the wisdom of Intel marketing. Right now. Even if we are sorely tempted to. Aaargh! Getting back to the tech, all of the QPI links have been sped up from 8GT/S to 9.6GT/s.
Since QPI links are effectively PCIe lanes with a proprietary overlay and a few minor changes, losing 8 PCIe3 lanes and gaining one 8-wide QPI link means no socket changes or added pins. This saves a lot of money and design time, plus it just makes a lot of sense. While the per-socket PCie lane count goes down a bit, you now have 128 lanes per system instead of 80 on Haswell-EP, not a bad step up. How many system will need more than 128 lanes per box? If you have such a workload, you can always step up to an 8-socket system and the attendant 256 lanes should the need arise. More than that, well you need a third-party chipset, but you can do it. The end result look like this.
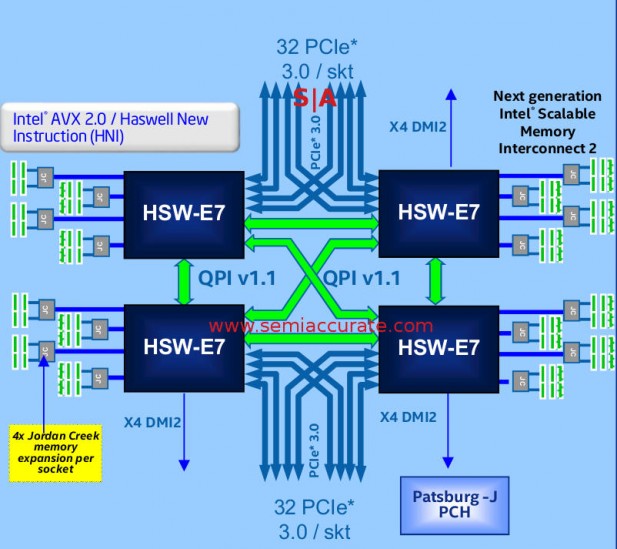
An example of a 4S Haswell-EX system
One aside is that the PCIe3 lanes now support relaxed ordering. This means that at companies which support casual Fridays and similar dress codes, the E7v3 can save a bit of performance sapping serialization overhead on I/Os. This won’t change the world by any means but it does help here and there, especially with heavy I/O loads like 10/40GbE NICs and wide SSDs like the ones Intel just introduced.
One major change from E7v2 to E7v3 is the aforementioned FIVR. You might recall that the Ivy based v2s had all cores working at the same speeds and voltages, not ideal for energy use. With the added control that FIVR brings, the E7v3 now supports per-core clocks, voltages, and other related power tricks. The uncore is also on a separate voltage domain and package C6 sleep states are now a possibility. High FIVRs all around, it is about time this capability was brought to the -EX line.
Other than that there really aren’t major changes to the die, the cores are the same, the rings and general layout is the same, and if you don’t look closely, you will probably miss even the big differences. On a more detailed level, specifically surrounding RAS, there are a bunch of very important differences between the -EP and -EX lines though.
Another feature of the core is what Intel calls Energy Efficient Turbo and it is an interesting one. In short when there is headroom for turbo, EET will look at idle counters on a CPU and see if it is actually doing something or spinning in place. If it is not actually doing work, turboing will only make it idle faster and consume more energy doing nothing, a big waste. EET will instead shunt that power to another place, usually the uncore, and turbo it instead. Simple but effective and quite useful.
If you are like most users, the more clock you can get the better, and the more turbo you can support, the faster things go. Some users however are more concerned with predictability, repeatability, and really get peeved at clock jitter even when it is on a very minor scale. We will call these users “Wall Street” for no particular reason, but that made up name isn’t the full set of clock related prickly customers. For them there is something called Turbo State Predictability. This is Intel marketing speak for capping turbo at a set level. If you really want your threads to run at the same speed, you can now cap the turbo bins so everything is more even rather than turning it off. People with private jets will love this, most others won’t care.
On the cache side you might recall the Intel Service Assurance Administrator, essentially cache tagging and tweaking to prevent a VM or a process from hogging more resources than are optimal. Since this is a capability of the Haswell core, you can now use the SAA features on the E7v3. There are two regions/sets per thread and the number of sets is programmable from 32-256. Counters monitor which app is using how much and will count hits and misses. From there the software can dictate actions to take and change the fill policy accordingly. This is the long way of saying if an app steps out of line and hogs the cache, it can be de-emphasized or even capped. For boxes with dozens of VMs on them, this can be a very useful tool to have.
Speaking of VMs, the core also brings with it VMCS shadowing and EPT A/D support in hardware. Both are hardware features to reduce the number of VMEnters and VMExits needed by either copying/shadowing data directly into the VM and VMM or tracking requests in hardware rather than software. We won’t go into the details here but both save quite a bit of pointless overhead.
Since we are talking about caching, Haswell-EX now has a directory cache but not a full directory. Each Home Agent has about 14KB of space allocated as an 8-way, 256-set, 2-sector space. This doesn’t actually store the cache line contents, just an 8-bit presence vector showing who hopefully owns what line. This allows any snoop request to be sent to the potential target directly instead of being broadcast. Given how much bus overhead and energy is consumed by snoop traffic on large systems, this is a potentially huge win.
The rest of the core is effectively Haswell with all the things that core brings with it, AVX2 being the most important. Like its brethren, Haswell-EX has an AVX clock and AVX Turbo mode, the polite way of saying that AVX cuts clocks once again. This is not a bad thing per se, doing more work consumes more power so rather than limit the whole chip, Intel just backs things off when AVX instructions are detected. You still get vastly more work done than without AVX2, but the lower clocks bother some people.
Haswell-EXs will watch the instruction stream and if there is one of a subset of AVX2 instructions, it will back off the base clock for 1ms. This backing off ranges from 0-400MHz or so and also affects turbo frequency. The exact change is highly dependent on core count, SKU clock, and a bunch of other factors, in essence high bin, high core count parts are backed off more than lower bin, lower core count ones. This is far from the end of the world, don’t let anyone tell you it is.
One bit that should have been on the lesser Haswells but wasn’t is TSX or Transactional Memory. In short the bug was fixed and now you can have TSX, not that there was officially a bug earlier, the feature was just arbitrarily fused off on some models to piss everyone off. Damn, I wasn’t going to mock Intel marketing in this article, was I? Too late, sorry. Nope, not sorry. That said TSX is here and on the -EX line it is a very good thing. While we won’t go into the details of what it does, if your workload is lock bound, TSX can mean absolutely massive performance gains with a minor bit of re-coding. It is either very worth the effort of nearly pointless, those who potentially need it know which category they fit into already.
Last up we come back to RAS and probably the most interesting new feature of the E7v3 family. It isn’t really a platform or core feature, kind of a bit of both called MCA2 or Machine Check Architecture Gen 2. What this does is enhance MCA by getting it on the mic sooner. Sorry, bad Beastie Boys joke. Without MCA2 a warning or error in the system will be sent to the OS and/or software to log, deal with, or just crash spectacularly. Even in the least severe case where something is just logged as a warning isn’t all that problematic… unless you have dozens of boxes running on that system.
In that case, which is likely to be the norm on 4/8S E7v3 systems, instead of one problem you get a warning or error propagated to dozens of OSes. Instead of one headache to track down and fix your datacenter may have just logged dozens or hundreds of trouble spots. Some OSes may ignore the issue, other may go blue with envy, but it is a serious problem for the spud behind the console. Even clicking ‘OK’ 63 times for an ECC warning can get tiresome. That is where MCA2 comes in.
The big benefit of MCA2 is that it can intercept warnings and errors in firmware and not pass them on to the OS or software stack. If an error is recoverable, the high level OSes don’t need to be notified, a hardware or single VMM log entry and warning will suffice. If there is for example a fatal memory error, the single VM that is affected by it can be allowed to gracefully puke and die without the others being any wiser. The same VMM and/or hardware logging will take place but the OS itself may be beyond help.
In short MCA2 reduces or eliminates the potential swarm of warning or error logs that an operator has to deal with. Instead of shouting fire in a crowded theater, MCA2 points the usher to the fire and has him put it out without causing a stampede of patrons. It may not sound like a big deal but given the cost and complexity of system management on the scale of a large datacenter, this can save serious money for operators.
Better yet the firware doesn’t just have to log the problem, it can decide which VM, OS, or application to notify, or not raise any external flags. It can also add related data to the mix to aid the higher level software in dealing with whatever went bump in the night. If you are running lots of E7v3 systems, particularly ones with tons of VMs per box, MCA2 is a very valuable feature.
And that is about it for the new Haswell-EX line aka the Xeon E7v3 family. The platform it runs on is either old or new, but the features you get with the new one are the big gains over the E7v2 family. The difference between the E5 and E7 lines are minor on an overview scale but major if you care about RAS and uptime. For those customers the upgrade is a huge step forward, and one that they will very glad to have. If you are considering a 4 or 8S platform, at the moment there is only one realistic choice, and it just got better by ~1 v unit.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024