![]() Not content to release only a new architecture, ARM is also announcing a new core called the Cortex A35. This new low-end mobile CPU is the 64-bit replacement for the mass-market A5 and A7s.
Not content to release only a new architecture, ARM is also announcing a new core called the Cortex A35. This new low-end mobile CPU is the 64-bit replacement for the mass-market A5 and A7s.
As the name suggests, the Cortex-A35 sits beside the A5 and A7 cores and below the A53/A57 high-end pairing. I know it makes no sense but there are some numbers in common between the lines, and the A part is consistent, that is enough, right? In any case this is the core, formerly code-named Mercury, that will bring 64-bits to the mass market.

The roadmap looking back
If you look at sales numbers, the two cores that the A35 replaces are a huge percentage of the market making up ~600M of the 1.4B phones sold in 2014 according to ARM’s figures. Since the A5/7 cores are 32-bit only, this meant enough of the market is not 64-bit capable to cause headache for devs and OS vendors. Google doesn’t want to be in the same situation as Microsoft so the faster this transition happens, the better for everyone.
ARM is claiming there will be silicon in 2016 and if their usual cadence is kept, that means pre-release silicon at MWC in February or March. Expect customer silicon later that year, the speed at which it hits the shelves depends on the who the lead partner is more than anything else. That said they should be all over the place by holiday 2016, the time between core releases to partners and consumer products has been shrinking of late.
So what is the new A35 other than 64-bit and lower end? ARM starts out with a claim of lower power, and it is an interesting one. Instead of quoting things in the normal way, IE ~20% better than its predecessor A7 at 32-bit workloads, they took an unusual path. First ARM redid the A7 with the latest tools and PDKs on the same 28nm process as the first A7, they call this the A7 re-baselined.
That core was ~10% more efficient but will never be released as a product, it is something any partner can do on their own, there are no RTL changes. The new A35 on the same 28nm process and running the same workload is a further 10% more efficient than the A7r2 or 19% better than the A7r1. We will round it to about 20% for the sake of argument, until we can compare core revisions without SoCs we have to take their word for it anyway.
In comparison to the A53, the next step up the food chain at the moment, the A35 is a claimed 25% smaller, uses 32% less power, and is 25% more efficient, all numbers we find plausible for a 2+ year newer core. Please do note that ARM does not claim it is smaller than the A7 much less the A5, just that it is much more capable and more efficient. Size is more than enough to keep the A5/7 alive in many cutthroat markets but the feature uplift should mean a swift uptake in most consumer mobile devices. So what does A35 bring to the table? Quite a bit.
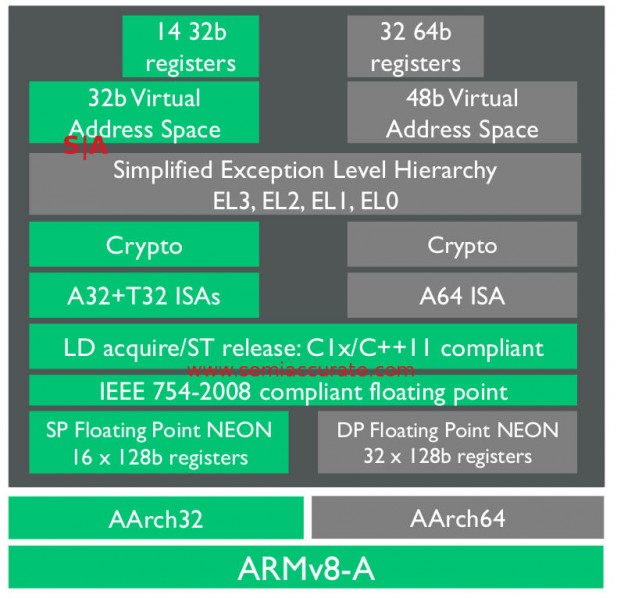
ARM low end ISA options for A35
To start with the new core adds quite a bit to the older 32-bit ISA, aka AArch32, something we weren’t expecting. This starts out with a new set of optional crypto instructions good for a claimed 3.5x increase at SHA-1 and 11x faster at AES. These are also available in 64-bit modes as well but that is expected in a modern device. There is also a new FP/NEON unit good for a claimed 2x SP FLOPS and 5x DP FLOPS over the A7, a massive increase. This unit is now fully pipelined and has much improved store performance, and the numbers do show that. This is likely aided by a set of new load acquire and store release instructions. Even in 32-bit mode the new A35 has enough new to make it worthwhile.
On the 64-it side everything is about what you would expect, it is current with the latest v8-A ISA revisions and should be quite a bit faster than 32-bit operations. Much of this is down to the vastly increased register count, and size too. In 32-bit mode the A35 has 14 32-bit registers which increases to 32 64-bit registers in 64-bit mode. On the FP/NEON side the count goes from 16 to 32 but all are 128b wide. In addition to the speed, this added register count should increase efficiency too, less swaps to memory should be noticeable on the battery life side.
So that is a bit of the what side of A35, but how does the core increase performance and how does this architecture differ from the A5/7 twins it supplants? It is fairly similar in many regards, still in-order and still has only limited dual-issue capabilities, it is not the OoO multi-pipe architecture of the A53/A57 twins. If the A7 is barely dual issue and the bigger A5x parts are true dual, the A35 is in between in most ways. That said there was a lot of attention placed on optimizing many of the weak areas of the A7, especially memory performance.
On the front end of the CPU, ARM increased the performance of the prefetch unit quite a bit, but not to the same levels as the bigger A-series cores. Those cores have more pipes to feed and can afford to spend a bit more power doing so. The A35 was optimized for a very different power point here so it is a bit lower performance but a lot more efficient.
The algorithms are different, the instruction queues are smaller than the A53 but larger than the A7. A lot of this has to do with the dual issue functionality, the ability to issue more instructions per clock means you need a greater store on hand to pull from. In effect the instruction queue size mirrors the issue capabilities of the cores.
On the L1 side of things there are three main updates starting with a boost to the TLB, it is now 512 entries vs 256 on the A7. The prefetch is capable of automatic multi-streaming which will likely hide fetch latencies a bit better. Last up ARM added automatic write stream detection, good for a bit more performance by sensing streams and not allocating buffer space to each individual entry. None of these things are a big bang in and of themselves but together they do add up.
Moving out a bit farther to the L2 there are again three main changes. The first is increased buffering capacity and resource sharing, important because up to four cores can share an L2. Similarly the coherency mechanism are improved which should reduce contention and buy a bit more performance here and there. Last is improved write stream detection, if you improve it on the L1 front and not the L2, you just move the bottleneck, something ARM appears to have avoided.
Last up is the NEON unit, something we told you about earlier. This now has a fully pieplined DP unit which explains the disproportionate increase in performance there. Added to this is better store performance, another traditional weak point for many ARM cores which FP heavily utilizes. Together the NEON unit brings the A35 up to a more modern standard on the FP math front, a boon for multimedia and games.
From reading the above you might have guessed that the FP and memory performance of the A35 should blow the A7 out of the water, and it does. We told you about the math performance earlier, the memory side is equally impressive at a claimed 3.75x better. As long as the energy use does not grow in proportion this will probably be a lot more noticeable to users, it has long been a point where lower end ARM cores underperformed. Hopefully that is now a thing of the past.
Speaking of power use, that side of the world did not go untouched on A35 either with two new additions. The first is a more granular power domain structure with the NEON units can now be fully powered down separately from the cores. If code does not use FP or SIMD instructions, that whole block can be slept or powered down independently of the rest of the core. FP and SIMD blocks are usually quite large and thus leak quite a bit compared to integer units. Since they are significantly larger and more capable in the A35, they likely leak more now too. If they are slept they leak less, and when off it goes down even farther. One of the keys to making this possible is a much lower wake up latency, if the NEON block is slept or powered off, if it can’t wake up quickly, performance will suffer badly.
To better control power management, ARM has standardized the Q-channel, the path the A35 will speak with an external power controller over. The new sleep states are hardware controlled on die and the chip can automatically wake from retention without external help, but full sleep is obviously a different story. With the standardized Q-channel doing these sometimes tricky sleep and wake transitions does not mean every SoC designer has to reinvent the wheel. Standards are good here, especially in the low-cost world that the A35 will play in.
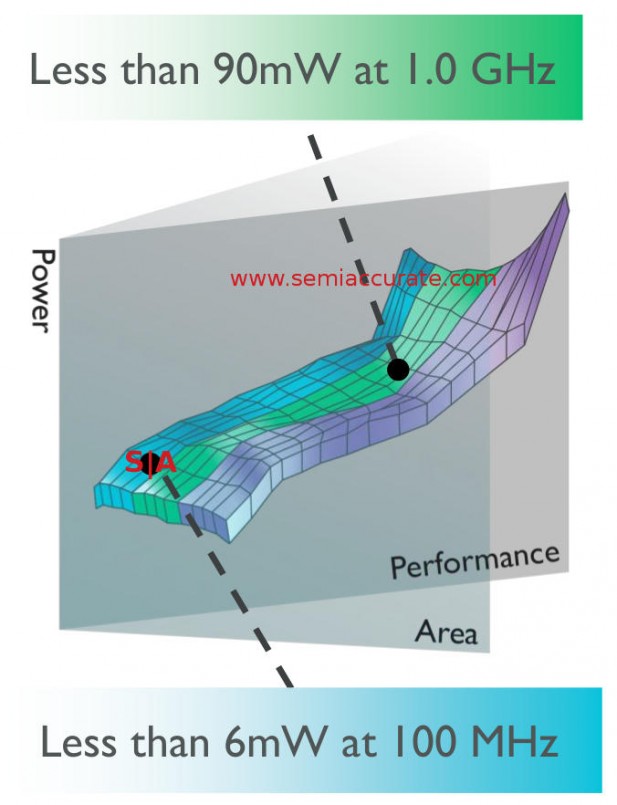
A35 power curve for 1GHz optimized core
Like previous cores there are several optimization points for the A35. The two ARM tends to quote are the lower end 1.2GHz core which is about the same frequency as many A7 implementations. On the high-end the cores will scale to 2GHz and beyond but the most efficient operating point is about 1GHz. ARM claims a mere 90mW draw at that frequency and a mere 6mW when running at the lowest operating speed, 100MHz. Yes the A35 can run lower than the A7 and step down more granularly. One thing to note is the slope of the curve above 1GHz, now do you see why they do a different design for the 2GHz optimized cores?
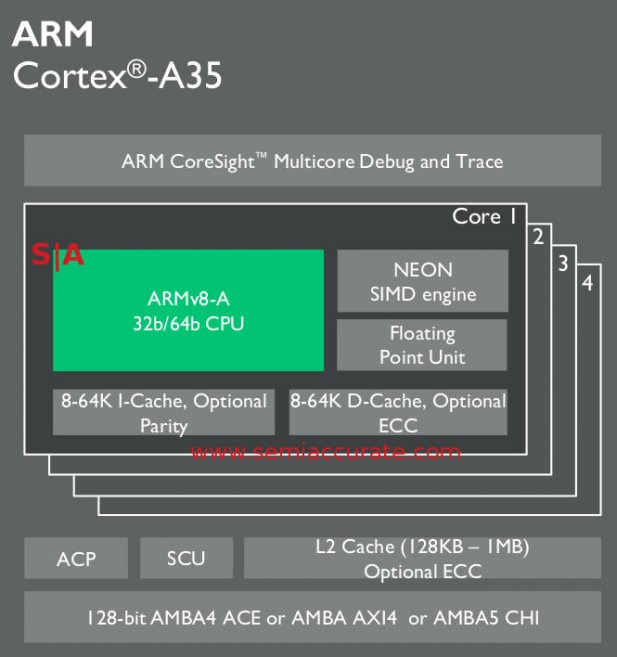
First one to correctly count all variants wins the picture above
So that in a nutshell is the A35 core, what ARM is calling its most configurable ever. Why? 1-4 cores per cluster, optional NEON, optional FP, 8-64K I-cache, 8-64K D-cache per core, both with optional ECC. The L2 is also optional and if you say yes, you can make it from 128K-1MB, again with optional ECC. It will all interface with an AMBA4 ACE, AMBA AXI4, or AMBA5 CHI bus out of the box, and can have an optional coherent ACP port too. ARM claims the smallest A35 core with 8K L1 and no L2 will only occupy .4mm^2 on a 28nm process. A 4C 32K L1 I/D, 1MB L2 version with NEON, crypto, and all the bells and whistles will be over 10x larger, that is over 4mm^2 or into bloated pig territory. Just kidding unless you are designing an SoC for emerging markets and other extremely cost constrained uses, then tenths of a mm^2 are life or death.
All in all ARM is moving the lowest end of the consumer device market into the 64-bit world. In less than a year the transition should start and a year or so after that it will be hard to find a 32-bit phone or tablet. The new A35 core seems far more efficient than it’s predecessors but won’t threaten the higher end A53/A57 pair on any benchmark that doesn’t include cost. Better yet many of the traditional weak points of the smallest consumer device oriented ARM cores have been addressed leaving a much more rounded product for even low-end consumers. In short it moves the mass market up to the current v8-A architecture with little pain and a lot of gain.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024