![]() Tilera is supplementing their Gx line of CPUs today with the 72-core Tile-Gx72 chip, an evolution of the current 16 and 32-core devices. While the architecture is not new, the rather odd core count was an unexpected surprise.
Tilera is supplementing their Gx line of CPUs today with the 72-core Tile-Gx72 chip, an evolution of the current 16 and 32-core devices. While the architecture is not new, the rather odd core count was an unexpected surprise.
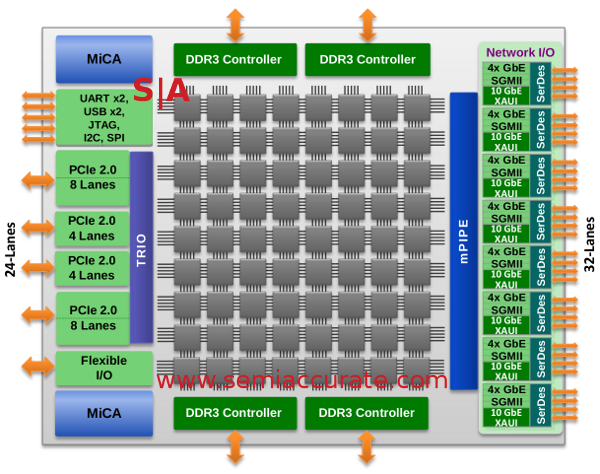
You might recall Tilera from our earlier article on the Gx family, the architecture hasn’t changed at all, just a few details. There are currently three chips in the family in full production having 9, 16, and 36-cores all in a pin compatible 1265-ball 37.5*37.5mm package. The new one doubles the core count and doubles just about everything else too. It is in an 1847-ball package that measures 45*45mm. The lineup looks like this.

Meet the family
You might notice that the difference between the 36 and 72-core variants can best be described as “2”. The big one has twice the PCIe lanes, twice the ethernet, twice the memory controllers, and so on. It pulls roughly twice the power too, said to be in the 60W range, not bad on such a large chip running at 1.2GHz. For those interested, no die size was given, but it is built on TSMC’s 40nm process and will sample next month.
72 is not a clean computer number
The core count is odd and not what was promised when the family was announced. At the official outing of the Gx line in late 2009, we were told there would be 16, 36, 64, and 100-core variants. The first two made it out ok, and a 9-core was added later. Realities of chip building hit the bigger two though and they ended up not having the expected core counts but 72 instead. 8*9 is not an arrangement you normally run in to in many CPU cores.
When asked what happened the answer was quite logical, “It was what fit”. Please note that the Xeon Larrab….Phi, yes Phi is 62 cores for the same reason, it fit. To make 64 or 100 cores work, Tilera would have ended up with white space in the middle or on the inside or on the ring, take your pick. 72 was also enough cores to do what the majority of users needed, basically it had enough power to balance I/O and compute. In light of that, 72 was in, the others out.
Since we have already gone over the architecture in great detail, we won’t rehash that part and instead focus on the uses. There are some pretty interesting numbers thrown out in the presentation, but the best bit is a use case. Tilera has been promoting the idea of doing work in pieces with each CPU doing part of a flow and then passing it off to the next one for another portion. It sounds rather silly, but it makes sense to have code locality in a throughput processor. Take a look at this diagram for a good illustration of that.
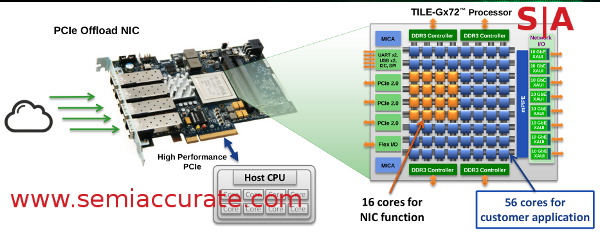
Note the cores used and what is near them
If you look at this, a generic NIC++, Tilera uses 16 cores for doing one of the + bits and leaves the other 56 for customers to use on the other +. Fair enough, but notice where the cores used are? This architecture can arbitrarily partition cores and pin functions to them so the NIC functions are on the cores immediately adjacent to the I/O blocks. Once that work has been done, it can hand off the result to the other cores with the minimum possible latency.
Tilera is claiming numbers like 1.7us UDP turnaround time for customer in the high frequency trading arena, and they are a pretty demanding bunch. This is not all that impressive a number until you realize that it is for 40Gbps bi-directional, 80Gbps total traffic on very small 64B packets. It rises to 110Gbps at 1500B packets and can hit 99% PCIe utilization. Not terribly bad for less than 25% of the available cores used.
Other workloads talked about are IP forwarding with traffic shaping (Boo, hiss!) which runs at 80Gbps using 60 cores, 40Gbps lossless packet capture with 16, SSL 3.0 processing at 40Gbps with only 10, and 40K 1024b RSA handshakes per second with 30 cores. Others listed are IDS, load balancing, video encode, video decode, audio processing, and many more. Other than video processing, almost none of these are limited by core power, most are I/O bound in some way. No matter what the problem, they are all very threadable problems, you are looking at hundreds or thousands of streams, not a single one so you can just add more devices if needed.
And that is the point. Tilera built a chip that fully utilized the space available instead of making a device that hit arbitrary numbers. Given the workloads that it is aimed at, Tilera may be performance bound on a single device, but that should scale almost perfectly linearly with added sockets. For that reason alone, the core count is mostly an irrelevant metric. While 64 and 100 are much cooler numbers than 72, but we think we can eventually come to terms with this issue.S|A
Updated: February 19, 2013. 11:40AM.
“1.7ms UDP turnaround time” has been changed to “1.7us UDP turnaround time” The typo difference between microseconds and milliseconds is significant. This is equivalent of what an FPGA has produced in the past.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024