![]() Intel is talking about their version of Infini Band called True Scale, and there are some rather interesting details on how they get the results they do. The fabric Intel devised seems to work well enough when scaled to thousands of nodes, so it should be enough for you too.
Intel is talking about their version of Infini Band called True Scale, and there are some rather interesting details on how they get the results they do. The fabric Intel devised seems to work well enough when scaled to thousands of nodes, so it should be enough for you too.
How to get a network to scale to thousands of nodes is a tough problem, but one that Intel is tackling out of necessity. The problems that HPC clusters now tackle are ones that can put literally infinite CPU power to good use. Sandia’s Chama cluster for example has 1232 nodes and 19,712 cores all tied together as one complete system. Unfortunately for Intel, Chama will not fit in a sub-21mm thin package, so it misses out out on all that Ultrabook marketing money, the server team will have to make it up.
Seriously though, connecting thousands of nodes together is not a tough problem, but doing it with very low but consistent latency is difficult. When you have so many systems that need to act as a single device, a slow node or link can take down the performance of hundreds or thousands of other computers. This type of HPC problem is what Intel is aiming at with their True Scale product.
The idea is simple enough, InfiniBand (IB) was designed over a decade ago as a data center backbone to replace ethernet and fiber channel links. It didn’t but several years later found a home in the HPC world as a low latency interconnect that scaled well to borderline silly core counts. It wasn’t exactly simple or cheap, but HPC is a world not know for either adjective, the first priority tends to be solving a problem. While IB is seeing more uptake in it’s originally intended markets of late, HPC is where it dominates all other interconnects.
True Scale is a superset of IB that is focused on small packets rather than the larger ones that IB was originally intended to tackle in the data center. To do this, it replaces the traditional Verbs based MPI libraries with a layer that Intel calls Performance Scaled Messaging (PSM). Verbs and MPI libraries can still be used on your True Scale cluster, but the optimization efforts were put in to PSM.
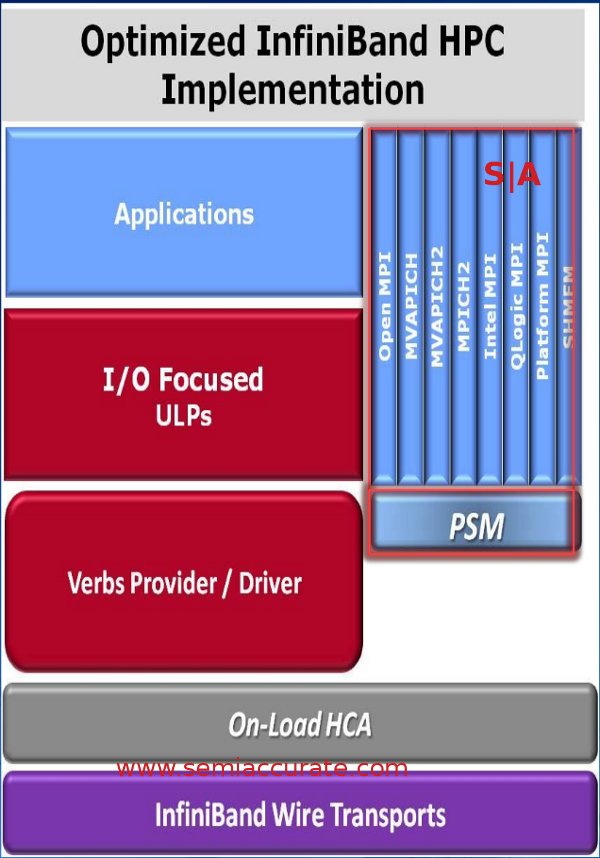
True Scale PSM stack
The first thing that saves a lot of time is that PSM is connectionless, paths are defined in the routing table when the fabric comes up, so there is no searching for what goes where. Adapters don’t have to maintain much if any state information so they can fire off or take in data without having to compute any addresses. That means low latency, and for HPC works, latency is about the most important metric out there.
One of the ways that Intel gets True Scale to scale so well is something they call QDR-80. QDR IB is Quad Data Rate or 40Gbps, QDR-80, in case you can’t see where this is going, is 80Gbps. Before you say that Intel is cheating by doubling the speed of transfers it is not that at all. Any individual True Scale card or port runs at 40Gbps just like QDR IB, Intel just puts two of them in a system.
This is what you call a convenient solution to a problem, use twice as many to get twice the performance. It is only convenient if you are selling hardware, customers are not too keen on the concept of buying twice the adapters and switch ports, and this stuff is not cheap to begin with either. To that end, Intel has priced the cards and switches at half of what the competition does, so 40Gbps costs half what QDR-80 does, or you can get twice bandwidth for the same cost as the old way. That said, there are some technical problems.
If you think back to the Nehalem class of servers, when Intel first came up with integrated PCIe, memory controllers and QPI, they had some time to market issues. Those issues surrounded machines with two northbridges in them, there were some stubborn corner cases that made engineers soak the rugs in their cubicles with tears. Those were eventually solved, but the problems with shortest paths to memory, PCIe, and other non-CPU devices are still very thorny.
As you can see with the diagram below, if you put one adapter in a 2S server, one core has direct access to the device, the other has an extra hop. Hops equal latency, and latency is bad. You can solve this by using 1S servers, but that has costs associated with it too, management being the least of them. The solution is to put in two cards and tie one logically to each socket.

The problem with one IB per box in pretty green arrows
That of course doubles the cost of the hardware, and trust me here, large IB switches are painfully expensive. Intel anticipated this and cut the price of the hardware in half so if you can deal with the latency, you win on cost. If you can’t, you can fix the problem by throwing hardware at it for the same money. We are not sure if this is a good idea for companies making hardware like Intel, count is good, halving ASP is not. That said, Intel did it, so it probably does work out for them.
One take home message from all of this is that Intel has not come up with a magical way to reduce latency in 2S systems, you still have to pay the price small though it may be. If you put a second adapter in, that makes one problem go away but the new problems it introduces are potentially much harder. That would be software, how do you tell a socket to send data to one card and not the other? What if an OS moves a process from Core 3 Socket 0 to Core 5 Socket 1, which PCIe slot does the data go out across? Do you partition the system, and if so at what cost to the running code? Do you pin threads to cores, define paths, or just do something that no one has thought of before?
The answers to these blindingly complex problems were not given out by Intel, is is obviously part of the secret sauce that makes QDR-80 work and True Scale live up to the last half of it’s name. That said, it does work, it does scale, and while we have some ideas as to how they do it, that is as far as Intel was willing to share. Intel claims that going the QDR-80 two adapter route shaves about 4/10ths of a microsecond off the latency numbers, not enough to notice if you are in a DMV line, but mana from heaven in the HPC world.
It does seem to work too, Intel had testimonials from three users that SemiAccurate can only describe as ‘casual’, Sandia, Los Alamos, and Lawrence Livermore National Labs. They have clusters of varying capacities starting at a mere 1200 nodes or so going up to over 20K nodes. If the QDR-80 secret sauce works well in these clusters, it is safe to say it will be at least adequate for your needs. Either that or wait for Windows Home Server 8, it brings serious optimizations for AV work across 1500+ nodes. That was a joke, you can giggle now.
If you haven’t already realized it, Intel is serious about the high bandwidth, low latency interconnect space. They make silicon, adapters, servers, software stacks, and even one that I admit I had no clue about, cables. About the only part they don’t sell is complete switches, but they do make ASICs for them. The advent of QDR-80 brings twice the performance per dollar that QDR did, and takes a chunk off latency at the same time. Most importantly Intel seems to have solved the hardest problem facing InfiniBand, 2S latency, and that is the biggest news.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024