![]() Nvidia is finally launching the GK10x based professional graphics cards today, and that brings up some touchy questions. If you recall, Nvidia has a graphics oriented professional line and a compute oriented one, ever wonder why?
Nvidia is finally launching the GK10x based professional graphics cards today, and that brings up some touchy questions. If you recall, Nvidia has a graphics oriented professional line and a compute oriented one, ever wonder why?
If you recall, the current Kepler line is split up in to two distinct products, the consumer GK104/106/107 chips, and the “professional” GK110 chip. The two have very different architectures, and the differentiating factor can be summed up as GPU compute. Basically the little cards have most of the GPU compute functions removed to save power, transistors, and complexity. The new cards being launched today are the Quadro K4000, K2000, and K600, all little brothers to the current GK104 based K5000.
As we said months before anyone else, the GK104’s selective feature removal paid off. The down side is that while the graphics performance is great, the compute performance is the polar opposite of that. You can see this in the numbers on Anandtech, they have probably the most complete set out there even if they are based on the consumer versions of the cards. The new GK110 card, aka Titan, is faster than most of the competition, but that was expected. At 551mm^2 (Note: Apologies for us calling it wrong 13 months ago, several months before introduction. We were off by 1mm^2, punishments will be swift and unforgiving.) it would be a shock if it was anything but fast.
Compute ability can be seen not in the raw GK104/GTX680 vs GK110 numbers, but in the GK104 vs the older GF110/GTX580 match up. The GK104 is faster than the GF110 in gaming, significantly so. In compute, it has the peaky performance we told you about long before launch, some tests have it beating it’s older brother by large margins, others have it losing by equally large margins. GK104 is definitely aimed at gaming and graphics, not compute. GK110 is what GK104 should have been if it were not so focused on graphics, it’s performance is much more rounded or even skewed the other way.
The problem is that the much larger die GK110 is not commensurately faster in gaming vs the GK104. It’s massive die size should buy it much more raw performance than it gets in the real world, indicative of the things that Nvidia could not take out for this chip because it’s primarily focus is compute, not graphics. In contrast, AMD’s Tahiti/HD7970 cards show much more even performance, with compute and graphics being fairly well balanced. The take away message here is that the older GF11x GPUs and the AMD Tahiti GPU are balanced, Kepler skews GK10x towards graphics and the GK110 towards compute. As products, this is not good or bad, it just is the choices that were made. Depending on your particular needs, a Kepler based solution could also be good, bad or neutral.
Technical issues aside, there is a minor problem with making GPUs this way, cost. Nvidia is bifurcating their chips like we said years ago, there are two distinct shader architectures now. They no longer have a single GPU line now either, and the various chips are not simple shader count based variants of the same architecture like AMD has and Nvidia had pre-Kepler. The big problem here is cost, you have to develop two shaders, and neither will sell nearly as many copies as a single architecture. If you are making gobs of money off both, this is a problem only in that it drops margins. If you sell more by having more focused products, and/or can charge more for each card, you can win on absolute income and margins. Like the tech, finance could go either way.
Given the rapidly shrinking graphics market, Nvidia is unlikely to increase sales much, and jacking up prices is quite risky in this economic environment too. Since some Kepler based professional cards have been released for over a quarter, there are some hard numbers to ponder, but the split does not appear to have created the proverbial home run product. Although it is early, Nvidia appears to be holding the line on sales, but now has to pay for two distinct development paths that only marginally overlap.
That brings us to today’s announcement of a the GK10x based professional cards. The Quadro K5000 version has been out for a while now, but the compute oriented Tesla product is long overdue. Sure there was the K10 with two GK104s on board, but where is the single GK104 compute card? Why did it take 6+ months to be revealed? You would think if they could put two on a PCB, one on a PCB would be neither a technical or yield challenge. Same with the GK110 based Quadro/professional graphics solution, why is it MIA? It isn’t yield or technical problems, so whatever could it be?
This is where the bifurcated shader strategy starts to bite. Nvidia has three major lines, GeForce for gaming, Quadro for professional graphics, and Tesla for GPU compute. Prior to the Kepler line of GPUs, you had different sized variants of the same basic architecture capable of doing all three tasks. The top of each line was the big GPU, the mid-range was the middle GPU, and the low end was the low end chip. Lines were differentiated by fusing off DP FP capabilities on the pro graphics products and gaming lines, but not on compute ones. Furthermore, drivers would lock out “professional features” on the gaming cards, but not on the professional graphics models. Of course price was also very different with the pro and compute cards being an order of magnitude higher than the same chip at a higher frequency that had a GeForce label, a few more fuses blown, and different drivers. This allowed Nvidia to make borderline obscene profits on the non-gaming lines.
With the bifurcation of function in Kepler, the big GPU was compute heavy and relatively light in graphics performance. The medium and small GPUs, GK104 and GK106/7 respectively, were compute light and graphics heavy. This is all fine and dandy until you look at the way Nvidia has their product stack lined up. If you think about it as three lines with three die sizes each in prior generations, Kepler can now only fill five of those nine slots, the two lower slots on graphics lines and the top compute slot. Below GK110, there is no good compute fit. Above GK104, there is no good graphics fit.
Enter Maximus. According to Nvidia, it is the best, nay bestest way to do workstation graphics and compute out there. Now you can put a Quadro and a Tesla card, professional graphics and GPU compute respectively, in the same workstation! Wow! [Insert Nvidia advertising run of the month here.] Now you can pay twice as much as before to get the same result as a single balanced card, what can possibly be wrong with that notion? If a GF110 cost $399 or so in GeForce GTX580 guise, why wouldn’t customers love paying $3000 for a Quadro version of the same chip and then another $3000 for a Tesla version for their workstations.
Except customers don’t like paying twice as much for the same functionality they used to get in one card. In Fermi generation, it was a stretch to justify the need for doubling up on the same exact ASIC. In the Kepler generation of GPUs, it suddenly makes a lot more sense from Nvidia’s perspective. Not only do they not have a single chip that can fill all niches now, but they work around that inconvenience by charging twice as much. Accountants love this idea, but customers are a bit cooler on it for some reason. In the current economic environment, for some unfathomable reason, this concept is not taking off.
And that leaves Nvidia in a pickle. They can’t fill the product niches they have created with a single GPUs architecture any more. Their solution is great for their bottom line but painful and regressive for their customers. This scenario usually doesn’t end well for anyone, and given how well their professional line is doing, it looks like customers have noticed this.
That brings us to today’s launch. Nvidia has a lot of benchmarks to show they trounce the competition, that would be AMD’s FirePro line. These Nvidia sourced benchmarks show that their lines are something between equal to and abusively faster than competing AMD products. They may cost more, sometimes many times more than AMD, but the extra speed is worth it. AMD countered with a deck showing that the synthetic benchmarks were indeed a tie or a loss for them, but in real world applications, not synthetic benchmarks, they trounce Nvidia. Nvidia has yet to show real world benchmarks. The deck looks like this across multiple program types.
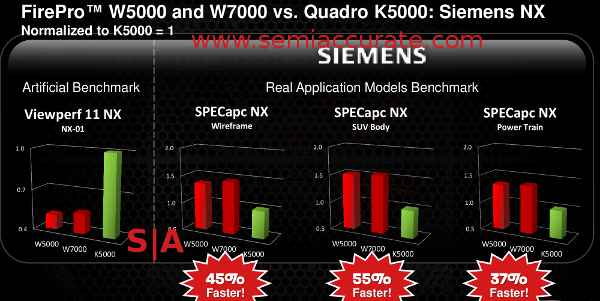
Note the difference between the two viewpoints
There are several slides that show the same thing, a synthetic ViewPerf 11 subtest where Nvidia trounces the AMD card, and real world examples from Siemens (pictured), Dassault Systems, PTC, and others that do what the synthetic ViewPerf subtests claim to represent. As you might guess, AMD beats Nvidia like a drum here. Which is right? Who is telling the truth? You can either benchmark things or look at a different set of numbers, sales. That is the ultimate arbiter of who is “right”, be it through technical means or marketing superiority.
In sales, Nvidia essentially created the professional graphics category years ago, and is the dominant player in this lucrative business. They have owned 90+% of the market by unit sales for years and have further subdivided it in to professional graphics and compute categories. Now their silicon choices mean they can’t actually satisfy the very categories they have created. The solution is to put two cards, each architected for different performance area, in to the hands of every consumer. At effectively twice the price per seat, if they pull it off, the splitting of the lines will pay of and the development costs of two shader architectures will pale in comparison to the revenue. AMD’s more rounded performance will lose on both fronts, but not to the same card. Even at the lower prices AMD is charging, customers won’t care because this market is about performance, not cost.
How did it work out for Nvidia? A year ago and a half ago, prior to this dual cards with Fermi/Maximus launching, Nvidia owned almost 90% of the professional market and AMD was in the 10-12% unit share range. Revenues were even more lopsided toward Nvidia because AMD had lower prices as well. Now that the bifurcated and more focused Keplers are out and the Maximus strategy is baked in to silicon, how are things going? How much market share did Nvidia gain? The last set of numbers SemiAccurate has seen put AMD at around 20% unit share and climbing at more than 1%/quarter. Double the cards, double the price, and double the marketshare for the competition.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024