![]() Intel is re-imagining what servers are, and the result looks nothing like what you think of as a server. The term for it is Rack Scale Architecture (RSA) or Rack Disaggregation (RD), and it does just what the name implies.
Intel is re-imagining what servers are, and the result looks nothing like what you think of as a server. The term for it is Rack Scale Architecture (RSA) or Rack Disaggregation (RD), and it does just what the name implies.
Current servers be they rack or pedestal have changed little in the last two or three decades. You have a CPU or two, sometimes many more, on a motherboard with DRAM, a chipset, some I/O slots and ports, and occasionally a few other bits. If you know what a block diagram of a PC looks like, you get the idea, and silicon consolidation aside, it has been pretty static since the dawn of the PC.
Over the past 20 or 30 years this was just fine for most customers. If you wanted a server, you just bought one powerful enough to meet your needs or budget. If you needed a lot more than one, you bought a bunch of rack mount servers, configured them, and slid them in to a rack in your closet, err high tech data center. Until the advent of the Internet, it was rare for a company to need lots and lots of servers, a user only needed access to a small number for work.
The net changed all of that while spawning data centers and now megadatacenters. Companies no longer buy a server, Amazon, Google, and Facebook buy them by the rack, tens of thousands of them a month. The concerns of old, expansion, flexibility, and basically enough performance to do the job are no longer even considerations for this type of customer. They know what they want down to the LEDs on the board and the power each uses, and will not buy any more than they need. The old concerns are gone, the new ones are (Total Cost of Ownership) TCO, (Return On Investment) ROI, and almost nothing else. They don’t put slots on boards that won’t be used, no ports that won’t be filled, and installation/provisioning trump any aesthetic concerns.
What was the bread and butter of the PC industry has become totally unsuitable over the last handful of years. This problem has become so acute that the major players have banded together to not just throw out the old ways, but come up with new ways of doing things more suited to this brave new world. RSA and RD are just a few of the ideas, and industry bodies like Open Compute Project (OCP) are guiding some of the efforts. While there is no shortage of ideas, the end results tend to look more like a SeaMicro or Calxeda box than the traditional rack stuffed with 2U servers. There are good technical reasons for this too, it isn’t a game of copycat.
Intel has a vision that can be broken down in to three distinct phases, today, emerging, and future. Today is easy, go to any data center and look down the aisles. You will see racks of machines with 2U boxes stuffed in them and maybe a switch or two on the top or middle. Some more daring installs have storage or other functionality in there too but the majority are 1/2/4U x86 machines.
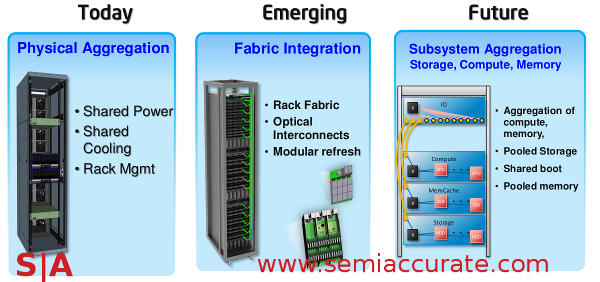
Ghosts of servers past, present, and future Mr Marley
Emerging is what RSA and RD is all about, at least what this generation of it is about. The idea is simple, take that tried and true architecture and modularize it to the highest degree possible. Break up every last bit that you can, and put in place standards that allow customers to mix and match the result. This allows them to buy only what they need, install only what they need, and theoretically have fewer headaches while doing so. If they want a CPU board with two DIMM slots and the normal one has four, they only have to redesign that bit, not the whole system. If it is made to the correct standards there should be no problems with it later on.
If done right this will lower costs, massively advance end-user customization abilities, and increase density by almost silly levels. What you get is nothing like what anyone would recognize as a server unless you are used to seeing SeaMicro like boards slotted in to a blade enclosure that houses most of what was on an old server board. Intel has several variants of this theme that fit the Open Compute Project guidelines and other related efforts. Take a look at this diagram, it is not what you might expect to see when shopping for rack servers.
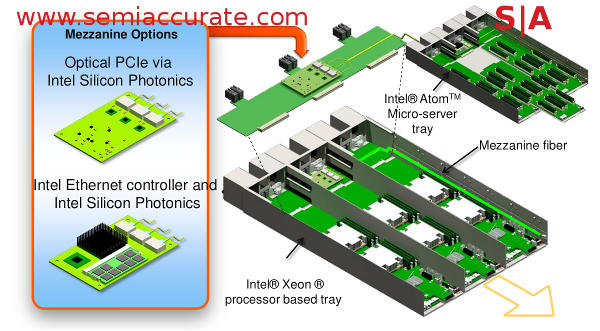
What the near future looks like other than flying cars
The basic building block is a tray, each rack mountable sled unit takes three trays, and they plug-in to a backplane. The trays themselves can house anything out there, from 2S Xeons to the tiniest of microservers, that part is up to the customer. If they meet the standards that they are designed for, you can plug-in either one, or storage, or management platforms, or anything else you want. Networking should work as well, but that isn’t the brightest idea for reasons we will get in to later.
The most intriguing part of all this is the Atom Micro-server tray, but the interesting parts are not shown on the diagram. One phrase that was said to SemiAccurate about the slide was, “DIMM form-factor servers”. Stop and think about that for a second, Atoms can be stuffed in to a small form factor, but a server, memory and I/O included in the form factor of a DIMM? How any of those do you think you can stuff in to a 2U sled if you don’t need a PSU, drives, or ports? If you thought credit card PCs were cool, how about an 8-core 64-bit x86 server with several gigs of memory on a DIMM? Admit it, you are smiling now.
Intel of course wants you to pick a Xeon or an Atom, whichever fits your needs and budget better, but if you go the OCP standards route there are many others from ARM to more obscure vendors out there that will sell you trays that should work without hassle. In any case, if RSA and RD take hold there will be no shortage of options to pick from.
The reason networking was not mentioned earlier is that the whole point of RD is to break things up, and networking is an easy one to break out. One major point of the emerging architectures is to disaggregate networking from compute so that as long as you only need what the backplane offers for bandwidth, it isn’t something you need to worry about.
If you take a look at the Mezzanine boards in the diagram above you will see Intel offers two options, optical PCIe and optical Ethernet. The key point is both are optical so both can offer large bandwidth numbers across long distances for relatively low-cost. One of these “mez cards” will have more than enough bandwidth for three 2S Xeon boxes or 36 Atom chicklets. 40 or 100GbE is far less of a problem when you are optical end to end.
In the Intel vision of the emerging markets, pun fully intended, these all mez cards run fibers up to the top of the rack where they plug-in to a passive optical backplane. This is fancy wording for a U-shaped fiber that routes the signal to another mez card or big switch somewhere else in the data center. You actually don’t need to plug it in to the same rack really, if you are using the right type of fiber the other end of the cable can be a non-trivial number of kilometers away.
This brings up two points, topology and disaggregated networking. Topology is pretty obvious, you can make whatever topology you want, limited only by the creativity you showed playing with a Lite-Brite as a kid. If you still haven’t passed the square peg/round hole test after years of intense studying, you probably don’t belong in the data center anyway. Most others should not have terrible difficulty carrying out pre-planned networking topologies with this architecture. If you bought a rack with mez cards capable of doing what you intend, then it will just work.
Disaggregated networking is a bit more conceptually troubling and it goes something like this. Normally you have a big switch sitting on top of your rack that can route things to and fro among any server plugged in to the rack. It had a big pipe off the back to another tier of switches that would route things between top of rack switches and possibly to another tier of switches on the other side. This was big, expensive, hard to configure right, and fell painfully flat when you needed to do things like moving VMs that had MAC address requirements. The new trend is flat instead of tiered networks, but that too has problems.
The solution, emerging solution that is, is to break it all up. Instead of a big switch or 12, each tray has a far less capable switch in it that can meet the needs of anything plugged in on the inside and pass whatever needs to be pushed off box to the right place. Depending on your intended topology that could be a tiered system, a flat system, or even a cable to the box above to form a store and forward optical ring of megadatacenter size. I wouldn’t recommend the last one though.
If you are a large enough customer, and anyone buying these racks in multi-digit numbers qualifies, you probably have a topology in mind. You also have the clout to make sure the firmware does what you want, not that it is likely to not do it in the first place. The whole point of disaggregation is to be flexible, networking included. After the first generation or two, doing what you need probably won’t be an issue for all but the most pathological cases. What your network looks like from there is up to you, but you will have one logical control plane across multiple distributed hardware installations. Breaking up a big expensive switch in to many smaller ones makes no sense if the result costs more to manage than you can ever hope to save. One logical control plane makes life so much easier it is almost silly for the data center architect.
As you can see above, the tray/sled architecture with a mez card on the back allows you to have one NIC per three or 36 x86 servers with no external switches needed. If you want storage, plug in a storage sled or just run a fiber to the bank of storage racks on the other side of the megadatacenter. Management is either on board or on a management server sled if you really want to do something the mez cards can’t do. You really don’t need to buy anything extra, it should all just work. Density sky-rockets too, power use drops because you only use what you need, and all this lowers TCO in other ways too. It also precludes you buying a single server, the smallest unit that makes sense is now a rack.
Intel sees this as the architecture for short and mid-term data center servers, but it isn’t there yet other than early test parts so it is still considered emerging. Everything can be swapped out now, the only thing in common is the interface between the sled and tray or the server and I/O unit to be more precise. You don’t have to have a sled/tray architecture, that isn’t necessarily proscribed it is just one of many potential solutions. The OCP version is one variant, another is called Scorpio, and Intel has their own vision as well. Don’t worry about too few options in an RSA/RD world there are dozens already.
The Intel RSA is described above, OCP is more or less the same thing without the optical backplane, and Scorpio is a joint effort between Intel, Alibaba, Baidu, and Tencent. If Scorpio sounds like a defacto Chinese national data center standard, while not officially one it is likely to become just that. As such it is worth looking at in a bit more detail, Scorpio will likely be deployed by the tens of thousands per month.
Scorpio is far less radical than the others but should be deployed in China-scale numbers before the competition see much real deployment. Each ‘server’ is one rack and it has a central PSU, cooling and management infrastructure for the entire rack. You can see where a lot of cost reduction is coming from as well as much of the efficiencies. This isn’t just limited to the cost of hardware or power and cooling, management is not cheap either. Managing a rack as a unit is a lot easier than managing 120 2S servers or 1440 Atom thingies, and easier is far cheaper than hard.
Two neat things Scorpio brings to the table are plug and play installation and GPS. Plug and play is easy enough, think a customized version of the management tools currently out there just deployed on a rack scale. Asset discovery and push configuration is also nothing new, it just isn’t done on this type of box in public very often. Using GPS for asset tracking and management is a bit novel though, ever seen a server that needs GPS to be located before? Now do you get the scale these things are going to be deployed on? Finding a blinking light in a 12 acre row of racks is not easy, especially if rack #4789271-A/ZZ9 is not exactly where the hand written map on the wall a few hundred meters that say says it is. And no, I am not joking.
When emerging runs out we get to the architecture called future. No, not that future just the term meaning later. By then it will be called emerging though, Intel really needs to work on these code names. That said, the whole RD and RSA work is just the start of the paradigm shift, the really radical changes are yet to come. How radical? Ever why a server needs to have local memory? I don’t mean storage, I mean DRAM, why is it local? If you said latency, you are right, but what if other things far outweigh the need for low latency?
A good example would be sheer sizes that are not amenable to local physical connections or the need to share among a large number of CPUs. Remember we are talking about installations where GPS is the preferred method of locating a box so scale is several orders of magnitude more than anything you are likely thinking about. Everything in this case is a pool, memory, storage, ports, bandwidth, etc etc. It can all be arbitrarily configured, reassigned, and twiddled mostly though a remote software control panel, not a GWASMAAF (Guy With A Screwdriver, Map, And A Flashlight).
Now you know where we are now, you know were we are going soon, and where we will end up in servers someday be it over the rainbow or in a lights out megadatacenter. If you know what a server looks like, you will be completely lost in a megadatacenter of the near future. Rack Disaggregation is from a hardware, software, and management perspective completely different to nearly everything we have now in the server space. Luckily the goal of this change is to give us more compatible options and let the end-user configure it till they get bored. Mix and match. Unluckily it is only the beginning, these fundamental changes are a cross between the low hanging fruit and what is actually possible, the real changes are yet to come. This article will be updated in 1-2 decades with the resulting progress, really.(1)S|A
(1) Note: It hopefully won’t take that long to write it up, we actually know how it will be done now.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024
- Doogee (Almost) makes the phone we always wanted - Mar 11, 2024