![]() Intel is introducing a new 22nm Atom core, and for the first time in the history of the line it is a new microarchitecture. Lets take a look at what we can expect from this new device, and why.
Intel is introducing a new 22nm Atom core, and for the first time in the history of the line it is a new microarchitecture. Lets take a look at what we can expect from this new device, and why.
If you are wondering what has changed in this new core that Intel calls Silvermont, it would be easier to list off what is similar to the older 32nm Saltwell core. That answer is easy enough, the L1 cache size and the marketing name Atom, almost everything else is different. Actually this is a bit misleading, the L1 may technically be the same size but it is all new as well too. The goals Intel had for the core are simple enough to describe, more performance for less power, and it looks like Intel achieved their goals. Unfortunately there were no exact numbers given out during the briefing SemiAccurate got last week, but the information was more than enough to get a clear view of what to expect from devices.
First on the list of major changes is one you probably expected, going from an in-order core to an out-of-order core. Why? We told you about this change over a year and a half ago, along with the move to dual pipes. We got the spelling of Avoton wrong, but we can live with that. Unfortunately SemiAccurate’s moles really missed out on the next biggest change, the move from Hyperthreaded (HT) cores to paired single threaded ones that share an L2 cache like some other modern x86 architectures of note. We don’t know whether to pat the little guys on the head for nailing it long before anyone else or hunt them down for the things they missed. Mole herding is tougher than it appears.
These two rather fundamental trade-offs were not made without understanding what those trade-offs entailed. For some odd reason both of them involved increasing single threaded performance while dropping power use. Please note that it is not just increased performance per watt, it is increased performance per watt at a lower absolute wattage used. Intel architects said that the increased complexity of an OoO CPU was balanced by the removal of HT functionality. The net result is a core the has higher single threaded performance at a lower wattage, and the threading loss is balanced out by a second siamesed core.
Two cores and an L2 cache are called a module, up to four of which can be connected to a single SoC fabric through a point to point interface called IDI. The fabric is also connected to the SoC’s myriad of other functional units, the memory controller, and I/O. Unfortunately Intel was only talking about the core itself so no details on what that fabric looks like or the rest of the chip yet, and that is where much of the interesting stuff happens of late. Each module has its own voltage plane but individual cores can run at disparate clock frequencies.
Running cores at different frequencies is currently not being used but the reasons to do so are simple enough, power sharing. This is an area where Silvermont differs from its Saltwell predecessor because like the bigger Intel cores, Silvermont can shift power from one core or the GPU to the other units. Shifting power allows burst mode ‘turbo’ to temporarily exceed the unit TDP for thermally brief time frames. Silvermont can reassign the power budget between cores, to and from the GPU, and to other unspecified units on the SoC.
Since Intel wasn’t talking about the SoC yet, they won’t say what those units are or how this feature is utilized, but you can see how it would be useful to speed up things like fast photo encoding from the camera. This is also where running two cores in a module at differing frequencies can be utilized. Intel was very clear that the capability to do so is there now and it works, but there really isn’t a need to use it in current products. That said if you have a reason to do so, Silvermont can twiddle the clocks on a single core in a module at your whim. For those of you into processor minutia, there is one PLL per core pair and they get to differing clocks with a DLL.
This power sharing is a lot more sophisticated, it measures not only thermals and electical load, but is aware of power delivery capabilities on the board as well. Most of this is similar in concept to Saltwell, but much more sophisticated. You might recall that the Penwell chip had a few discrete points that it could clock at, basically papa bear, momma bear, baby bear, and twitchy cousin Zeke who uses too much crack bear. Or something like that in Intel lawyer-approved terminology, but you get the idea. Silvermont can adjust those clock points dynamically based on the above parameters and likely many more minor ones too, Saltwell only had three or four discrete stops.
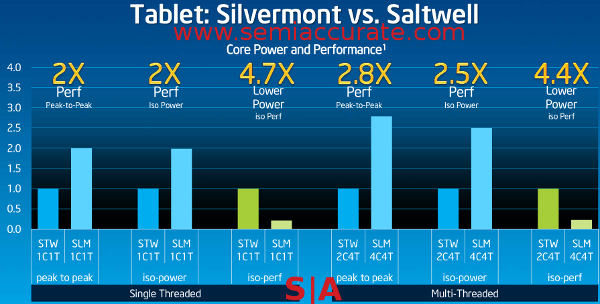
Don’t ignore the fine print on this one, that is where the interesting stuff is
So how does it do? Intel didn’t disclose clocks at all for the Silvermont core, but they did say that it is about a 50% IPC improvement over Saltwell. As you can see in the graph above, the single threaded side has a 2x raw performance improvement at both peak and a fixed power level. This is interesting for two reasons, clocks only being one of them. 2/1.5=1.33 so you can assume clocks go up by about 33% in total, 2.5GHz+ on the top end.
The second chart showing iso-power is the more interesting one though, it says that at the same power level, Silvermont is 2x as fast as Saltwell. Looking at the peak-to-peak chart, it also shows 2x the performance so you can safely assume that the TDP of a single Silvermont core is the same as a single Saltwell core running at a lower clock. Silvermont has HT though and that will up efficiency on multi-threaded code too. The iso-perf numbers show that Silvermont is not just more efficient in an absolute sense, it gets better on discrete workloads likely because of HUGS/HUGI (Hurry Up and Go to Sleep/Idle) allowing it to finish and power down quickly.
Back to the multi-threaded performance side of the world, on a 4T workload Silvermont steps further out in front of Saltwell. What you are seeing here is the difference between a “real core” and a HT thread, can you hear the champagne corks popping at AMD? Yes, two real cores are much faster than one threaded core, and powering both can be done more efficiently than a single threaded core too. That is what the middle graphs shows, a single 22nm core delivers 2x the performance at the same power as a 32nm one, but when you go to four threads that gap jumps to 2.5x. In this class of cores, HT isn’t a win, but that doesn’t necessarily carry over to other core architectures, bigger or smaller. We eagerly await the Sky Lake product briefings…
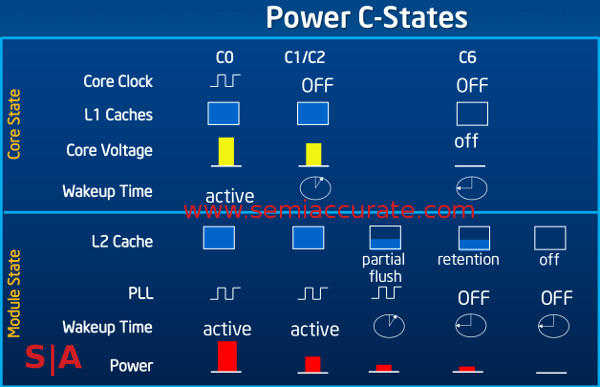
The last three are the important ones
One last thing is the C-states and as you would suspect, they have a major overhaul this time around too. It is hard to do much more than platform power level awareness, the SoC can’t control the user yet so that is what it has to play with. The most major change in Silvermont power levels is the module states, specifically the last three. Off and Retention are nothing new, Saltwell had those as do most modern architectures large and small. This time around they are incrementally improved with faster entry and exit along with much finer grained power gating. This may not sound like much but a few percentage points saved here adds up when you go in to and out of those modes many times a second. It can result in a lot of newly found standby time.
The new one is the partial flush feature and it is quite the interesting hack. Partial flush isn’t exactly what it sounds like, it flushes the entire cash when the SoC goes to sleep, but how it works is where the magic lies. Normally in PCs you gain efficiency by running a task as fast as possible then turning off for as long as possible. With the cache flush you are bandwidth limited, you can only dump things out as fast as your memory will take them. Partial flush takes advantage of this by lowering the SoC to the minimum possible speed necessary to save the cache out to NVRAM at full speed.
This saves power by running the core as slowly as possible while saving out, but once again that is old hat. Silvermont saves the cache out by ways, one at a time, then powers down that section of the cache progressively. Instead of waiting for a hypothetical 10 time units for a cache dump before shutting down, they can save 1/10th of the cache in one time unit, then power down 1/10th of the cache. You then save off another 1/10th of the cache and power it down etc etc. You can see how this will save a lot of the power consumed by the cache during each power down cycle. The absolute value of this number is really small, but once again it adds up and your battery is finite.
And that sums up the Silvermont core itself from a user perspective, several big and fundamental changes like OoO, two pipelines, and the loss of HT. Many of the gains that lead you to the massive 4-5x efficiency improvements are small and obscure in isolation, massive in aggregate. They all add up to a very efficient core and the 22nm SoC process they are built on adds to that too. How did Intel do all of this on an architectural level, and how exactly does the process add to it? Those topics are up next.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024