![]() SemiAccurate went over Microsoft’s XBox One SoC in great detail, now it is time to take a look at the Kinect sensor. While it might not have the same level of complexity as the main SoC, this innovative sensor is entirely homegrown IP.
SemiAccurate went over Microsoft’s XBox One SoC in great detail, now it is time to take a look at the Kinect sensor. While it might not have the same level of complexity as the main SoC, this innovative sensor is entirely homegrown IP.
If you haven’t read our series on the XBox One’s SoC architecture, it is worth going over if you aren’t familiar with the device. Large amounts of the Kinect functionality is done in the main SoC itself and we will be referencing it regularly. The three parts can be found here, here, and here. This is all based on the Hot Chips 25 talk by John Sell and Patrick O’Connor.
The first thing to consider when thinking about the new Kinect sensor is what problem is it trying to solve. The simple answer is that it is a 1080p depth camera but that really is only scratching the surface. Once you start looking at the fine details, how much resolution, how many objects, what distance, color, ambient lighting, field of view, frame rate, and a plethora of others does the real complexity emerge. What are the requirements of the new Kinect in the XBox One?
Patrick O’Connor laid out a myriad of challenges for the sensor team, the first was consistent performance. This may seem like a given but think about playing a game with children and adults, the adults close to the camera, the children far away. A child’s wrist may appear smaller than an adult’s finger, so how do you differentiate? The technical requirements ended up with a depth resolution accurate to within 1% and the minimum sized object detectable being 2.5cm.
Apparent size is relative to a depth so what distance do you need 2.5cm of resolution at? Given that the Kinnct is meant to be a controller for gaming while moving around, you need to have a large play area to do innovative things like this while taking it to the expectations for a “next generation” device. This meant an effective range of .8-4.2m with a 70 degree horizontal field of vision. 2.5cm at 4+m is not a trivial task, especially while tracking multiple people at 30FPS.
Next on the list was an accurate and responsive user experience. Remember how SemiAccurate was harping about the direct data paths from the South Bridge to the SoC and the DMA transfers it was capable of? If you want responsive you need low latency. If you want consistency you need dedicated hardware instead of shared hardware, and the higher the accuracy the better the user experience. The target here was a total latency as measured from photon in the sensor to data packet received at the CPU of <14ms. If you think about all the calculations that need to go on for a depth sensor, 14ms is an amazingly small amount of time.
The last major challenge is lighting. If you game in a dark room that poses one set of challenges, bright sunshine another. How about a room divided between bright sunshine and deep shadow with people moving in and out across the boundary all the time. This is what you call a very hard technical problem. Just to make things worse, how about an adult in a bright-colored or even somewhat shiny outfit close to the camera playing against a goth attired child at the edge of the play area? How did Microsoft’s engineers deal with that kind type of sensor nightmare? With a brand new type of time of flight sensor and deep integration with the XBox One SoC.
The sensor that powers the Kinect is pretty simple and extremely innovative at the same time, just take a fairly standard camera sensor and add a timing generator to it. While you are at it, connect this to an IR light source so the sensor can tell when the light is on and when it is off. Other than each pixel/sensor cell being dual ported, the sensor is pretty standard fare. It all looks like this.
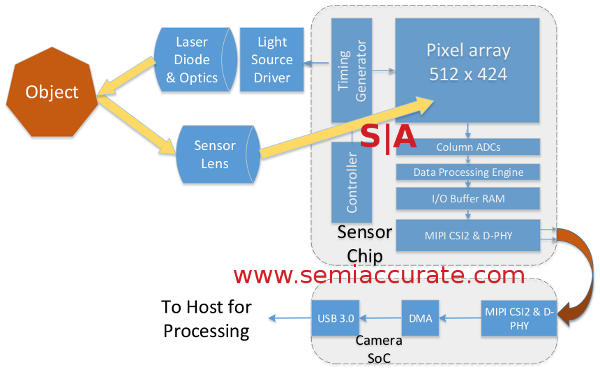
The basics of the new Kinect sensor
Here is where the magic starts and it kicks off with modulating the light source. This is technical talk for turning it on and off very fast, O’Connor mentioned tens of MHz as the frequency during his talk. The timing generator allows the camera sensor to know if the light is on or off multiple times per pixel. Remember that dual ported sensor architecture? If the light is on/high the output of the sensor goes to the A port, off/low it goes to the B port. Because of the high modulation rate you can get multiple shots in different lighting per pixel sensor per frame, 30FPS is painfully slow compared to tens of MHz modulation rates.
This allows Microsoft to do all sorts of clever things with the resulting data. The first is that you get two images, one that is lit (A) and one that is ambient lighting (B). If you add A and B you get what Microsoft calls Common Mode, a grey-scale image. Arctan (A-B) gives you depth information more or less for free too. The magnitude of (A-B) is called the Active image, grey-scale image that is independent of ambient lighting. With a lit and unlit image plus some simple but clever math, Microsoft can get a high rez grey-scale image with full depth data, all from a single sensor. Neato, eh?
This is not the end of the story however, there are a lot of other problems that this methodology creates. What are they? How did Microsoft solve them? Will Lassie alert Dad that little Timmy is trapped in a mine shaft before the PS4 launches? Tune in for the next part of SemiAccurate’s look at the XBox One Kinect sensor to find out.S|A
Note: This is Part 1 of a series, Part 2 will be linked here.
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024
- Doogee (Almost) makes the phone we always wanted - Mar 11, 2024
- Intel Birch Stream Boards Speak From The SIde - Mar 6, 2024