![]() The Kinect sensor in the upcoming XBox One uses a clever way of measuring depth, but what problems arise from it? Microsoft has obviously solved those problems but how did they do it, and what were the trade-offs?
The Kinect sensor in the upcoming XBox One uses a clever way of measuring depth, but what problems arise from it? Microsoft has obviously solved those problems but how did they do it, and what were the trade-offs?
If you haven’t read SemiAccurate’s three-part series on the XBox One’s main SOC (Parts 1, 2, and 3) and the first part of our Kinect article, you might want to go over them over first. This part is a continuation of those two articles and is once again based on the excellent Hot Chips 25 talk by John Sell and Patrick O’Connor.
The Kinect’s quite novel way of using timing and a dual ported sensor array to get depth related data and neutralize problematic lighting conditions is really innovative. Once you have the two differential images, the calculations are easy enough to do and since they are known and fixed you can easily do it in hardware. The outputs of the A and B ports and the calculated results looks like this.
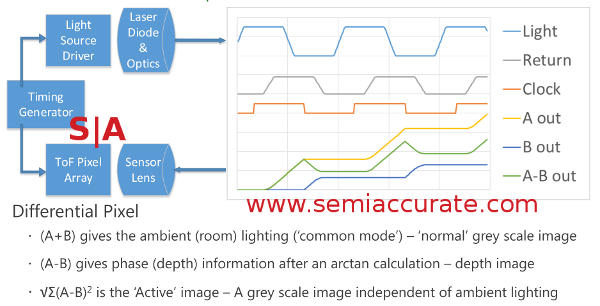
A and B ports can result in lots of data
So we know the Kinect can measure the distance with a simple calculation based on the two images, but how? Time of flight or more to the point time of flight and a few phase tricks. The speed of light is known, the timings of the sensor and light source are known, and the phases of light generated and received are known. With that the time of flight of the photons can be calculated almost trivially with phase being the easiest way.
There is one minor problem in that phase wraps after a wavelength, about 3.75m for the 80MHz light frequency the Kinect designers wanted to use. You might have noticed that a 3.75m wrapping distance is less than the 4.2m that the design goals specified. If you use a lower wavelength this effectively extends the distance before phase wrapping but will drop your resolution. This also runs afoul of another design goal and so it is equally a non-starter. So what do you do?
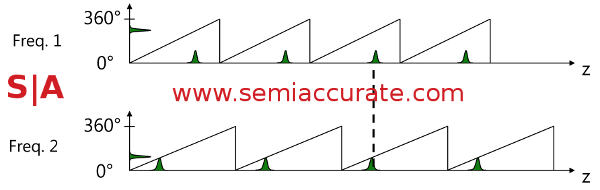
Wavelengths do matter for sensors
The answer is to modulate the light source once again to put out two frequencies. You can measure the phase of frequency one and get a result that is one or possibly one of two distances depending on potential for phase wrapping. A second wavelength will also give you one or one of two possible distances and the two compared will only have one point in common. This is of course your distance. In effect with one dual ported sensor, a timing generator, and a modulatable light source the Kinect sensor can measure distance accurately, at high resolutions, and best of all cheaply.
But wait there’s more, more problems anyway. Remember the whole issue of a brightly lit person in light-colored clothes close to the camera vs a person in black clothes and dim light at the edge of the detection range? Light falls off with the square of distance so an object at 4m will only reflect 1/16th the light of the same object at 1m. Add in that a bright-colored outfit may reflect 95% of the light vs 10% for a dark outfit and you have an even larger problem. Just for fun toss in the non-uniform lighting conditions and you have a dynamic range problem from hell. [Editor’s note: Is hell more uniformly lit as it is only lit by fire?]
Microsoft determined that they would need a dynamic range of about 2500x to cope with all of these requirements, far more than a simple camera can achieve. In fact doing it in conventional ways means a far more expensive camera than the XBox One’s price will allow for. The solution was to once again be both clever and innovative with the sensor design.
Remember the part about the high modulation rate of the light source? 10s of MHz vs a pixel count of .217Mp? See a disparity? Remember how the dual ported pixels can take an A and a B image for every frame? The sensor can actually do much more than that, it can take multiple A and B exposures per frame. O’Connor said that the sensor can determine exposure on a per-pixel basis, quite the technical feat. This allows the depth camera to have a dynamic dynamic range in a way that most regular cameras can only dream of. More importantly it solves the dynamic range requirements without throwing expensive hardware at the problem.
One other thing that the new Kinect has that isn’t exactly related to the depth sensor is an array microphone. This is used for assigning audio to a source, essentially who said what. The Kinect allows the XBox to detect people and objects but more importantly it can differentiate between multiple simultaneous moving people and objects. While you might expect the mic array to add to the object detection accuracy it is the other way around. The camera detects the people and then that information is fed in to the steering algorithms for the microphones to improve their accuracy.
If you recall from the first part the Kinect sensor had a block under it called the Camera SoC. Calling it an SoC is a bit of a stretch, it really is a data consolidator and organizer. The Camera SoC pulls in the sensor output, packetizes it and sends it off to the main XBox SoC. The color image, depth data, and sound are all interleaved in a single packet structure sent to the South Bridge via USB3.0. This is a big part of achieving the <14ms latency requirement for responsiveness.
One thing you will notice is completely absent is any mention of how people, parts of people, and various objects are identified and analyzed. How does the system figure out that this blob of depth data a person and that blob of depth data is a chair? The answer is easy enough, the Kinect sensor doesn’t nor does the Kinect device, the XBox One does. The sensor data is fed directly to the main SoC with the lowest latency possible where the magic happens.
Remember all those offload engines on the SoC, a good number of which didn’t appear on the block diagram? This is where the Kinect does the heavy lifting but since it is done on the XBox One’s CPU/SoC I guess that is a bit of a misnomer. All the processing is done with accelerators where possible and by one of the 8 AMD Jaguar cores where they are a better fit. How is this accomplished? That is a good question that Microsoft didn’t answer.
In the end the Kinect sensor did it’s job. It met all the performance requirements needed to make it a decent gaming device controller. In theory anyway, we don’t have one and they are not publicly available so we will have to wait and see the results but the underlying tech looks good. Better yet Microsoft did it using solid state devices that depend on the speed of light and silicon timing, no expensive individual calibration needed. Cheap, functional, and clever, what more could you ask for?S|A
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024