![]() ARM is launching the successor to the CCN-504 bus, say hi to the new 32-core supporting CCN-508 bus. If you are familiar with the CCN-504 this new bus will look like more of the same with emphasis on the more side of things.
ARM is launching the successor to the CCN-504 bus, say hi to the new 32-core supporting CCN-508 bus. If you are familiar with the CCN-504 this new bus will look like more of the same with emphasis on the more side of things.
SemiAccurate said a bit about the CCN-504 bus when LSI announced the Axxia 5516 line a while back, they co-developed the bus with ARM. Near the end we mentioned that there were whispers about the Axxia line scaling to 32-cores but since CCN-504 only allowed up to four clusters of four chips there needed to be a new bus for that. Enter the CCN-508 that scales to eight clusters of four CPUs.
CCN stands for Cache Coherent Network and as you can probably guess, that means the CPUs are indeed all coherent. The 5 is likely for working with the 5th generation ARM bus called AMBA 5 and the last digit is the cluster count. There is a flavor of AMBA 5 called CHI or Coherent Hub Interface that is a non-blocking crossbar which scales to four cores. These form the backbone of the eight clusters and each attach to the ring that is the heart of the CCN-508. It looks like this.
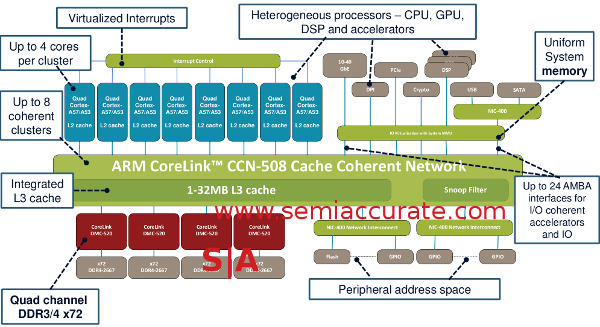
Ring around the crossbars with a bunch of other stuff too
Each cluster of four AMBA 5 CHI connected CPUs have their own L2 cache whose size is likely determined by what CPU you use for your SoC. The older CCN-504 supported A15, A53, and A57 cores but the newer 508 does not officially support the A15. While it is only our speculation it is likely that by the time this new bus comes out the A5x devices will be more than ready. If you are building a >16-core SoC for high bandwidth uses, you want as much CPU power as possible not to mention memory and cache. Why? The longer version is here.
So if you take these eight clusters and connect them with a 128-bit wide link to a large ring you have the basis of the CCN-508. That 128-bit link is important because even though the bus runs at core speeds, the devices that use it are bandwidth hogs. At the moment speed and width are necessary, and having 128-bit wide connections to everything really help eliminate needless bit fiddling and the associated latency from it. Currently the CCN-504 runs at more than 1.5GHz on TSMC 28HPM and the 508 should clock similarly.
Connected to the ring are up to 24 AMBA connected accelerators. These ports can be coherent but don’t have to be and AMBA 4 AXI or ACE-Lite interfaces are supported too. Since these are 128-bit ports there is likely some bit-twiddling here if your logic bock isn’t wide enough. Examples of accelerators are 40Gb Ethernet, DSPs, PCIe channels, crypto blocks, and any other ARM compatible IP you want to slap on there. Luckily the library of IP blocks compatible with ARM is about as extensive as one could hope for and CCN-508 gives it all the bandwidth it hopefully needs, that would be over 50GBps per link.
Thanks for the high bandwidth memories
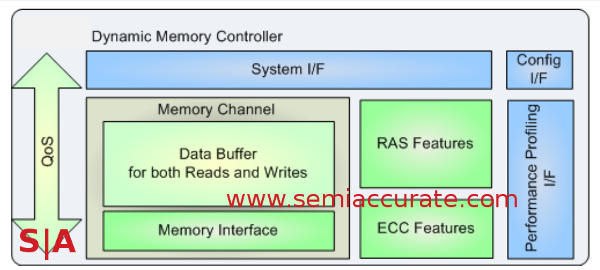
The last major group of connections are the four Corelink DMC-520 memory controllers, each one is 32-bits wide. The math savy among you may notice that it adds up to 128-bits of memory width, see a trend? Each controller will support DDR3, DDR3L, or DDR4 up to 2667 speeds with full parity supported. That means a total of more than 21GBps per channel and well over 80GBps aggregate system memory bandwidth. ARM says there is extensive buffering to reduce R/W turnaround problems too.
Each DMC-520 connects to the ring with the mandatory AMBA 5 CHI and to memory with standard DFI-3.0 links to the PHYs. All the latest low power modes are supported as you might expect and they are quite programmable as most networking systems have quite stringent latency demands here as well. Related to this is an end to end QoS system that basically tags packets moving around the ring which are stripped off as data hits the CHI link. Similarly DMC-520 supports the full Trustzone partitioning for virtualization and security.
The CCN-508 ring itself obviously supports the whole QoS paradigm and it can arbitrate and regulate both inbound and outbound traffic. Given the nature of the workloads CCN-508 based devices are aimed at, as you would expect the ring itself supports parity and some other unnamed RAS features. Telcos don’t take errors lightly so heavy RAS is kind of mandatory in the space.
As you would expect 32 coherent cores and up to 24 accelerators that are usually bandwidth heavy require a lot of data. QoS on top of that mean caching is more than just a nicety it is absolutely required as a starting point. The CCN-504 supported up to 16MB of L3 cache, CCN-508 doubles this to 32MB and that is probably what you will see in most of the high-end CCN-508 devices. To keep all of these devices from consuming all the bandwidth with coherency traffic there is also a snoop filter upgraded from the one in the CCN-504.
All of the links on the CCN-508 are optional, some SoCs need more CPU, others need just enough to boot and hand off to the accelerators. Some need massive memory bandwidth, others not so much. In short the CHI clusters can have between 1-4 CPUs, there can be between 1-8 populated CHI links, 1-24 accelerator links, and 1-4 memory controllers. This is a rather large array of supported options even before you throw in cache variances and different accelerator blocks.
How does it work? ARM says perfectly because it is both based on the CCN-504 which is out in silicon now and because of a cycle accurate simulator. This simulator has been validated to within 3% of the RTL on the 504 so the 508 version should be pretty good as well. I guess we will know when chips come out bearing it, something that should happen shortly enough.
Lastly we come back to the thing on everyone’s mind of late, power. As you would expect the CCN-508 has extensive power gating and power down options to turn everything off as soon as it is not needed. In addition, each of the CHI links can power down fully if required or not required as the case may be. In short it can scale from over 250GBps peak, 160GBps sustained bandwidth to almost off with lots of steps between the two extremes.
So where does this leave us? CCN-508 is a bit more than twice CCN-504 in some respects, less than twice in others. Aggregate performance is pretty massive. It has to be with each port supporting more than 50GBps bandwidth. Since the CCN-504 bus was designed for a serious comms and signaling SoC line and the 508 builds upon that, the outlook for this new bus looks good. If the rumors are to be believed we will see in pretty short order.S|A
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024