![]() Cavium and Xpiant, soon to be merged as Cavium, are coming out with a new class of high-end Ethernet switch. The idea is to make it field upgradable via code, but not necessarily programmable.
Cavium and Xpiant, soon to be merged as Cavium, are coming out with a new class of high-end Ethernet switch. The idea is to make it field upgradable via code, but not necessarily programmable.
The idea behind this new class of device is that new protocols come out all the time and that usually means buying new switches. This in turn means a long wait from standards implementation to purchasable device, you usually need to spin new silicon to support new standards and that isn’t quick. So called ‘programmable’ switches or SDN devices aren’t really in the same class as a core switch, they do much more but tend to have much higher latencies.
With their XPliant Packet Architecture (XPA), Cavium is trying to split the difference by making an upgradable but not programmable switch. With their new devices you can add protocols and services via table uploads so in theory the 18-30 month silicon upgrade cycle can be reduced to software and test time. Think weeks or months, not years.
How does XPliant manage this feat, upgradability without programmability and the attendant latency? They don’t have a general purpose processor like the programmable switches that operate higher up the OSI stack, they operate strictly on L2 and L3 plus tunneling and bridging but do nearly everything possible at those levels. The list of protocols that they support is said to be really long if not complete, including some of the new tunneling protocols like VXLAN, NVGRE, and GENEVE.
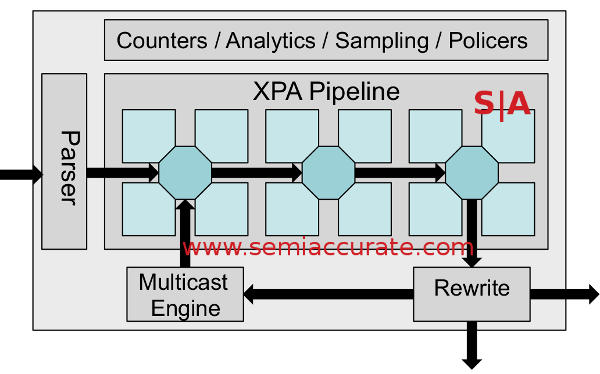
A very simplified version of XPA
The way this is accomplished is via a generic architecture with a few fixed bits, namely the initial Ethernet frame parser and a few other things like the multicast engine later on. The rest in the middle of the XPA pipeline picture above is a blank slate that you load tables, not code, into at boot. These tables are then used to parse the packets and forward them to the next table, rinse and repeat until you are done or hit the end of the line.
This may sound like a programmable device but it isn’t for two key reasons, the first being that the compute bits aren’t really exposed to the users. More importantly is that this is a stateless machine that can only operate on one packet at a time, it can’t do the multi-packet assembly, disassembly, decoding, and DPI type work that a true programmable switch can. Then again it is not meant to, and that is where the speed comes from.
One caveat to all of this is that if you want to do that kind of work, you might have noticed the block on the above diagram labeled, “Counters/Analytics/Sampling/Policers”. With the flexibility of the XPA architecture, you can tag a lot more packets and shunt them and only them to a device that does the DPI and multi-packet work. Things that need more loving attention, usually for very anti-social and anti-user reasons, can be sent to the right place and the rest goes on with minimal latency. It also has the potential to change analytics if the device vendor wants to ‘code’ that, XPA has the potential to change the game there too.
The Xpliant/Cavium chip may not do all of that work but it can send the work to the right place. That right place is an externally connected device that can talk to the Xpliant switch via a PCIe link and/or a dedicated 10GbE link. This means you can put their silicon on a PCIe card or pull a lane off an Ethernet device, your call, but you can make a device with DPI and programmability from bespoke hardware and an Xpliant switch beside it in the same box. Once again it all depends on what the device maker wants to accomplish, Xpliant only supplies the switch silicon and sample tables.
Now that you have an idea of how XPA works, what is Xpliant actually making? There are four chips coming, the CNX88071, CNX88061, CNX88081, and CNX88081. If those seem to be a bit out of order, that is because the first has only 10Gb PHYs supporting 10/40GbE the other three have 25Gb PHYs so they can do 10/25/40/100GbE.
Please note the 25GbE bit, that is not technically a standard but it is quickly becoming an industry consensus and may be a standard someday. You might have noticed that 100GbE is actually four lanes of 25Gb, and so 25Gb is just routing those four lanes to different places. If the 100GbE standard covers transmission details, 25Gb shouldn’t be much of a trick to implement and interoperate.
These four new switch chips are pretty fast, the CNX88071 can do up to 128 lanes of 10GbE or 32×40, 1.28Tbps in total. The smallest CNX88061 is capable of .88Tbps or 48x10GbE and, not or, 4x100GbE, the largest CNX88091 can do 3.2Tbps or 32x100GbE ports or up to 128 slower lanes in total, mix and match. That is a massive amount of bandwidth to shuffle around, a staggering throughput number especially at the low latencies needed for backbone switches.
That brings us to the basic business pitch from Cavium/Xpliant, in other words why would a customer want this kind of device. First off there is the upgradeability, you don’t need to by a new set of switches when a new protocol comes out, and if you have priced Cisco or related core and spine switches lately, you know what expensive means. In theory with an Xpliant device you can upgrade the tables with a new patch to support the latest spec or protocol and do so in a fraction of the time it takes to do a silicon spin. Even if you could add support for a tunneling protocol like VXLAN on current silicon, it would likely call for two passes through the switch adding latency and halving throughput.
On the OEM side, the idea is similar, you only need to buy one type of silicon for all your switch needs, no headaches or overstock if something doesn’t do well on the market. In theory you can make one type of chip into a range of products so unless there is a fundamental flaw in the product, it is malleable. Same with its use in the datacenter, if a device has the required throughput, going from a spine to a ToR (Top of Rack) box is a table load away, plus some cable swaps of course. This flexibility at the OEM and customer end can be quite important, and interns swapping cables are cheap, core switches are not.
The largest CNX88091 is made at TSMC on their 28nm HPM process, samples will ship in Q4/2014 on a 55x55mm FCBGA package. If you want to start development early, Xpliant has a model for Linux on x86 that runs their code now, obviously not at speed though. There is also a full SDK to write for the model with and the resultant code should be directly loadable on the sample hardware in a few months. All in all it looks like the Xpliant chips and XPA is a really interesting idea that attacks a useful and untapped market.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024