![]() ARM is introducing a new M-series CPU core called the Cortex-M7, successor to the older Cortex-M4 line. While SemiAccurate can’t explain the naming process, we can tell you a lot about what this new CPU brings to the table.
ARM is introducing a new M-series CPU core called the Cortex-M7, successor to the older Cortex-M4 line. While SemiAccurate can’t explain the naming process, we can tell you a lot about what this new CPU brings to the table.
The new Cortex-M7, previously code name Pelican, not Pelican Lake. uses the same ARMv7-M ISA as the M4 with a few new cache maintenance operations. This means it will run the vast array of v7-M code out there with few if any modifications, it will just run it faster. How much faster? About 5 CoreMark/MHz in 40LP designs and a net 2x M4 performance when implemented in 28nm. On the DSP side, ARM is claiming about 2x the performance of the M4, presumably per clock. In short the M7 is a lot faster than the M4.
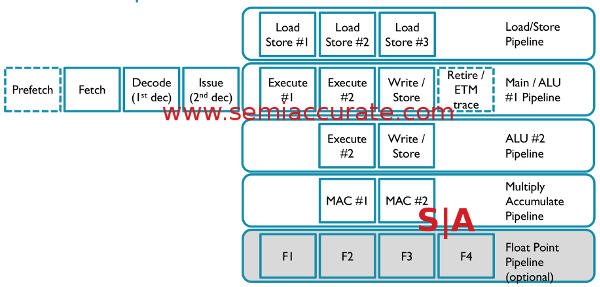
ARM M-Class pipelines, now with branches!
As you can see, the M7 has a 6-stage in order superscalar pipeline, the M3 and M4 were 3 stage single issue affairs. This is where a lot of the speed comes from, width and higher clocks via the longer pipelines. As you can see the FP pipeline is optional as it is on many ARM designs but the DSP-like instructions are integral to the ARMv7-M ISA. If you do have the FP pipeline, instructions can be dual issued with INTs. In short the M7 is a very different implementation of the ISA from that in M4 class cores.
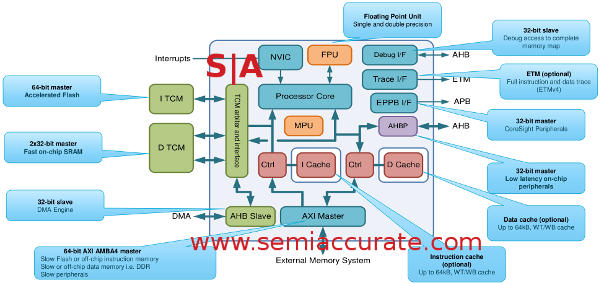
The block diagram of the M7 core
Things get interesting once you get outside of the core proper starting with the caches. Yes the M7 can have caches, once again optionally, up to 64KB I- and D-caches. The I-cache is 2-way set associative while the D-cache is 4-way, plus both can be configured independently from 4-64KB. For the technically oriented they support WT, WBRA, and WBWA, feel free to look it up if don’t already know what these are. The M7 has a full L1 setup, optionally, which is quite impressive for an embedded controller.
More interesting is the TCM, both I- and D- flavored, which stands for tightly coupled memory. This is a cross between off-chip L2 and dedicated memory but the semantics of it are not the important part. The I-TCM is 64-bits wide while the D-TCM is either 64b or 2x32b independent loads depending on bit 2 of the addresses sent. Each can support up to 16MB of memory, support wait states, and can be used to boot from if the correct type of memory is used, that would probably mean flash.
The idea behind TCMs is quite simple, to provide more deterministic performance for the SoC by providing a dedicated memory store closely coupled to the cores. For a lot of embedded applications, this is not just a nicety, it is almost mandatory. If you need hard realtime operation, buy an R-class CPU, but for the next best thing, TCMs help a lot. One thing ARM is very proud of is that they kept interrupt latency the same as on an M4, 12 cycles. Given how much more complex the M7 is, this is no small feat. Software and solutions providers will be quite happy with this, any changes would be problematic for code portability.
Moving more off die we come to the bus, now a full 64-bit AXI AMBA4 master. It supports most of the current ARM compatible IP so you can put almost anything on it you want. Since the M7 is aimed at embedded devices with task specific use cases, we expect to see a swarm of co-processor bearing designs in short order. Don’t expect many vanilla Cortex-M7s, everything will have special sauce because, well, you can now.
One thing ARM is quite proud of is the safety features of the M7, and no we don’t mean the debug and trace blocks in the upper right of the diagram. The real stuff is baked in starting with ECC in the caches. The TCMs can optionally have ECC on them, plus the main memory can presumably be ECC. We say presumably because it is not part of the M7 core, but ECC memory controllers for ARM aren’t exactly scarce.
On top of this the M7 architecture itself has a built-in memory protection unit for, well, memory protection. There is also new logic in the design for exception management but we don’t have more detail there. Most interesting is that if you have two cores, you can run them in lock-step mode for added reliability. Not many non-realtime cores support this out of the box, it is very handy if you need it but optional if you don’t.
In the end the new ARM Cortex-M7 looks like an M4 on steroids with roughly 2x the performance and more headroom. It may be an small extension of the ARMv7-M ISA but how it is implemented is quite another story, the M7 is a superscalar multi-issue beast in comparison to its predecessors. In the exciting world of embedded controllers this new M7 is a big leap forward and should enable a new class of smarter devices with a lot more features at a lower cost than before. How can you argue that?S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024
- Doogee (Almost) makes the phone we always wanted - Mar 11, 2024
- Intel Birch Stream Boards Speak From The SIde - Mar 6, 2024