![]() When SemiAccurate last talked about Soft Machines there were some big open questions. Now a year later with their latest technology disclosure, most of those have been answered along with many more interesting pieces.
When SemiAccurate last talked about Soft Machines there were some big open questions. Now a year later with their latest technology disclosure, most of those have been answered along with many more interesting pieces.
If you don’t remember our last article on Soft Machines(SM), they are a startup that promises to break one of the oldest roadblocks in processor design, sharing a thread between multiple cores. Actually it is more complex than that, what their technology does is to parse the instructions from a thread across multiple physical cores. This was previously thought to be borderline impossible but SM showed it working on a prototype chip last year.
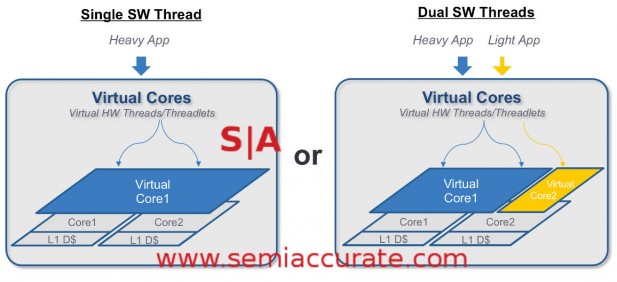
Partitioning like this is not easy
The idea is that all units on a core that can be used will be as long as there is enough work to fill all the available pipes. When a core has more work than it can handle, it can pawn some of that work off to a second core it is paired with. This workload sharing can run the gamut from zero to 100% of the work shared for theoretically optimum performance.
When SM showed off their chip last year there were a few things that appeared to be very big warning signs about the technology. The first was their low clock speed, the chip maxed out at about 500MHz at a time when the competition, presumably ARM SoCs, were hitting 2GHz. That said the architecture they call VISC was hitting a significant multiple of the IPC the competitors were so benchmarks results looked far better than the raw clocks suggested.
Then again they should because this is the heart of the SM technology promise, higher IPC means more performance at lower clocks for potentially large power savings. The only problem was that IPC is much easier to find the lower the clock speeds so that 500MHz clock appeared to some to be a big red flag. Soft Machines said at the time this was only a prototype part, much faster chips would follow in the future to dispel that notion.
Second up was the ISA, it was a proprietary one to the SM chips. There were emulators that could run ARM code along with potentially many others but that too was a bit of a sore point for some. In the past most code emulation was problematic, slow, and power-hungry. Again SM said this was different in their architecture and it would become clear in the future.
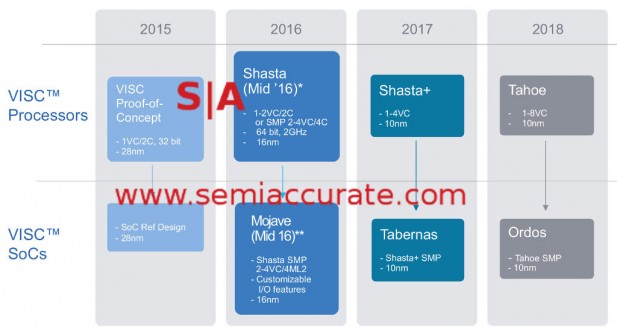
The roadmap in more detail than before
Step forward a year and Soft Machines is introducing two new chips, a server version called Shasta and a mobile SoC called Mojave. Both should be out in mid-2016 with Shasta being RTL and Mojave being an actual chip tapeout. As you can see above, they are both 64-bit, targeted at TSMC’s 16bnm FF+ process, and capable of SMP even if that term is a bit confusing when applied to VISC devices. More on that later.
The first of the red flags dispelled by Shasta is frequency, it should run at about 2GHz or roughly what current ARM cores hit in mobile form factors. It will have four physical cores arranged as two pairs of two in SMP orientation. Each of these two pairs can have two virtual cores assigned to them so Shasta will look to software like a four core SoC. Each of these virtual cores can utilize all the resources of the two associated physical cores so they can be pretty beefy when needed. Both of the physical cores have physically separate but coherent 1MB L2 caches.
Mojave is the same core structure but it will be a full physical SoC rather than the RTL form Shasta is released in. Since Shasta is aimed at servers and that market can be quite varied, the RTL release makes quite a bit of sense here. If you recall from our last article, SM is not going to sell chips, just license designs and IP to allow their customers to make the SoC of their dreams. The company will help out a customer or even design a chip to their specs, but those designs will be specific to the customer. If you think this through, you will probably conclude that Mojave is a customer design, and you would be right. That means SM has at least one customer making a SoC with their tech but they won’t say who or for what exactly. This is huge news for any startup, the first customer tends to be the hardest to get.
The next issue on the list was the ISA which moves from a 32-bit one on the prototype to a full 64-bit version in the Shasta/Mojave pair. SM can run what it calls personalities in software but they are not implemented in the expected way. Personalities are software and are loaded at boot time, but they are both light and low-level. They don’t emulate code, they just translate it to the native ISA, a 32-bit add is a 32-bit add on both native and emulated hardware, but probably have differing opcodes. Occasionally this software will need to do something more complex but the bulk of the work is basically a big lookup table.
Personalities are not purely software though, there are hardware hooks to assist in with the job, unfortunately SM did not go into more detail here. One thing they did say is that the code is not user accessible and runs underneath everything including a hypervisor where applicable. In x86 terms, think of this as ring -2 or something similar. To running code and users, everything should appear to be native hardware, assuming it all works as promised.
So with Shasta and Mojave, Soft Machines has answered both of the big questions that have followed them since last year’s architecture reveal. Assuming that the cores can run at 2GHz or so, don’t lose the IPC gains, and don’t suck power like a gaming GPU, things look promising. In less than a year we will know for sure when silicon comes out but for now we will be cautiously optimistic. That brings up the real question of how it all works. This is where things get really interesting.
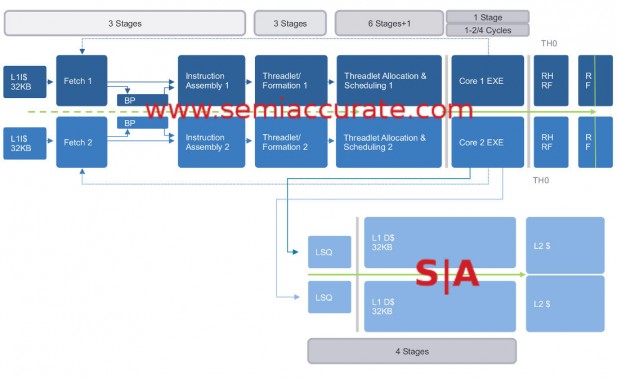
VISC pipeline times two plus a bit
The diagram above looks like a fairly normal pipeline for a core of this type but there are some exceptions. First up is that there are two of every stage, not just one. This is because there are two virtual cores and two physical cores per ‘processor’, (Note: Shasta and Mojave are both two processor SMP devices) so that explains the doubling. Also note the grey lines around the Core EXE and LSQ stages. These denote places where things can cross a boundary between cores.
One of the first questions this brings up is where is the boundary between virtual and physical cores, if there is one. The answer to that is prior to the Threadlet Formation stage the instructions are called global, past that they are much more associated with a physical core. A threadlet is a small bundle of instructions that is assigned to a physical core for execution. If a workload is heavy the global content will be treated as if there is one big CPU core, if it is light it will act as if it is two cores. Once the threadlets are formed they are parsed out to whatever physical core is appropriate.
This again brings up the problem of what happens if an instruction is scheduled on physical core 2 and the data it needs is in the L1 of physical core 1. If you have ever heard people say that splitting up a task between physical cores is impossible or at least horribly impractical, this issue is the major problem. Luckily there is a solution, coherency.
Before you point out that coherency does not solve this problem or even address it, with traditional coherency protocols you would be quite correct. The best they could do is get the data from a shared L2 or L3 which would both pollute the L1s and/or slow things down to the point where any gains from splitting the task would be lost and then some. This is why task splitting is considered ‘impossible’.
A lot of the Soft Machines magic comes in here, they have a coherency scheme that they describe as “light and tight” which can transfer data between L1’s in less than an L1 cache load cycle. This means that an op executing on core 2 with data in the core 1 cache can read it without a wait, the latency overhead is already accounted for. If you look closely at the pipeline diagram, you will see a bunch of +1s in the stage counts. When tasks are split across cores it adds a cycle to the scheduling and execution portions of the processor but that seems like a small price to pay especially if it is only intermittently needed.
This coherency scheme allows the hardware to ignore any potential cache issues, to the instructions it looks like both L1s are directly attached. Since that is the greatest problem in splitting tasks between cores, the impossible or impractical is no longer so.
Next up is a question of scaling, how high can things go for core counts? Soft Machines says that the Shasta architecture can go to 4/8 cores, basically double what they have now, without taking a latency hit. It could go higher with added latency but since the cores can scale by traditional SMP methods, that is the way to go. This is likely also why Shasta is being released as RTL, servers are a very diverse category with diverse workloads. Licensees can pick their own tradeoffs that best fit their own workloads.
Moving out to the system level we have some more interesting bits. The Shasta interface to the uncore is a 256-bit wide bus that can be customized with various plugins. This allows you to interface a VISC core with whatever IP you want, emulating ARM or MIPS does little good if you can’t work with their existing IP blocks. One other related feature is there are gaskets to third-party IP blocks that look to the system like PCIe attach points. This allows the SoC to do auto-discovery of IP blocks with known methods.
On the memory controller side Soft Machines provides their own design but they are amenable to third-party IP here too. They claim their 1-4 channel DDR4 controller can sustain 40GBps and the on-die fabric a can pass 200GBps to various consumers. That number is useful because the 1-8MB 4-way L3 can also sustain 200GBps so in theory it can be fully fed. The devil is in the details here but the high level numbers look fine from here.
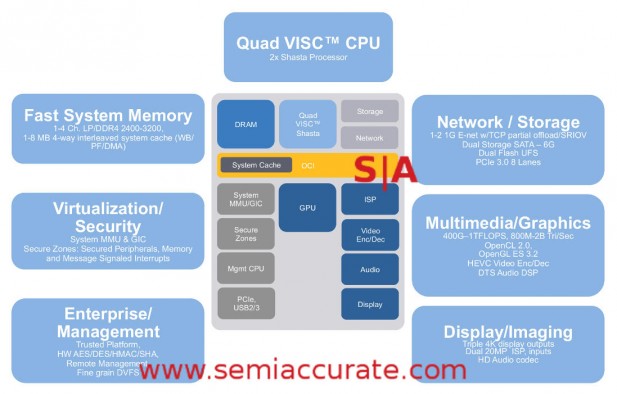
Looks like a phone/tablet SoC doesn’t it?
Moving on to the Mojave SoC there are a bunch of items that need to be added before a core is a full system be it on a single chip or many. The first big item on that list is a GPU and for this Soft Machines is turning to Imagination and a future iteration of their PowerVR architecture. Without naming it they are promising OpenDNE (Open Damn Near Everything) like OpenCL 2.0, OpenGL ES3.2, video encode and decode, plus a lot more.
In short Mojave should be state of the art when it comes to GPUs and promises .4-1TF of GPU compute along with .8-2B triangles per second. This range is likely the split between the lowest cluster count for this GPU family and the highest, not for a single iteration of Mojave. The ability to push three 4K displays and dual ISPs each capable of supporting 20MP sensors are just a bonus.
All of this is nothing without I/O and management, both of which are there on this SoC. There is the option for two GigE ports with some TCP/IP offload, two SATA6 ports, and 8x PCIe3 lanes. That should be good enough for mobile users, more than good for a decent Chromebook or clamshell device.
That brings us to management and Mojave has the usual buzzwords, TPM, remote management, and all the necessary crypto support. The SoC is clearly not designed for server workloads but there is enough security there to build something which could work in that context. Shasta is a more suitable starting point though, there is a lot to add before Mojave would integrate into a datacenter smoothly.
So that is the new offerings from Soft Machines and more importantly a lot more about how it all works. The chips and RTL have not been released yet but if the company hit their targets, we will have definitive proof that the whole VISC concept works. For the time being, they seem to have addressed the two main sticking points, clock frequency and ISA compatibility. If they get the Shasta and Mojave out on time, they very well could be game changers. I can’t wait to see the measured numbers.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024