 Today at Super Computing 15 (SC15) AMD is launching the Boltzmann Initiative and introducing a new HPC focused driver, a new compiler, and a runtime to translate CUDA code into something that can be compiled using AMD’s new compiler to run on AMD’s hardware. Those of you who are familiar with Ludwig Boltzmann may recall his contributions to Kinetic theory and development of Statistical Mechanics. AMD has named its new HPC initiative after him to highlight how his work is still being used in neural networking and Navier-Stokes algorithms on GPUs.
Today at Super Computing 15 (SC15) AMD is launching the Boltzmann Initiative and introducing a new HPC focused driver, a new compiler, and a runtime to translate CUDA code into something that can be compiled using AMD’s new compiler to run on AMD’s hardware. Those of you who are familiar with Ludwig Boltzmann may recall his contributions to Kinetic theory and development of Statistical Mechanics. AMD has named its new HPC initiative after him to highlight how his work is still being used in neural networking and Navier-Stokes algorithms on GPUs.

AMD believes that a strong computing platform is built on top a solid driver. To that end they are now offering a headless 64-bit Linux driver that integrates the HSA+ Runtime to its customers. This is a currently separate and limited distribution driver from AMD’s mainstream open-source Linux driver. It includes a unified address space for both CPUs and GPUs, and is optimized to reduce the latency involved in the dispatch of PCIe data transfers. AMD has also followed up on this focus on PCIe by implementing a large Base Address Register so that a really large number of PCIe devices can be mapped.
AMD said that they were building a separate, essentially closed-beta, driver for HPC systems so that they could gather and implement feedback from their HPC partners in the shortest amount of time possible. Once AMD is confident in the quality of the features in this HPC driver they expect roll them into AMD’s primary open-source Linux driver.
The fast and responsive driver development process that a closed beta driver, just for HPC, enables is the key to getting buyers to consider AMD’s hardware. The HPC market is rather small in terms of people and companies that participate so building relationships with those HPC customers through driver feedback and feature suggestions is what AMD needs to do to win hearts and minds.
Speaking of features AMD HPC driver also implements optimizations for communicating between multiple GPUs on multiple nodes over high-speed links like Infiniband using a peer-to-peer methodology for RMDA. This improves performance for large compute clusters where GPUs maybe communicating both within the same node and with a rack on the other side of the room. Doubling down on this commitment to serving large-scale environments AMD has implemented a suite of tools for managing its driver across multiple nodes which should be very helpful for system administration.
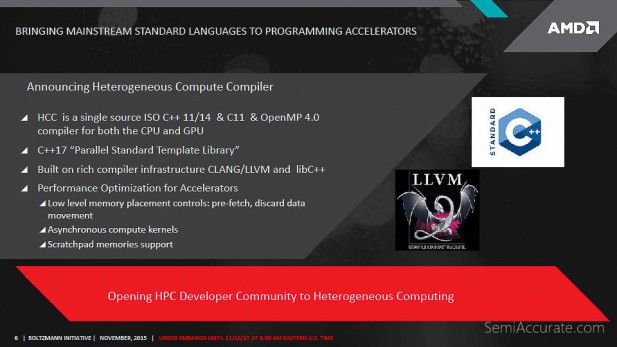
AMD is also introducing a new HSA compliant compiler today dubbed the Heterogeneous Compute Compiler (HCC). Based on feedback from the HPC community AMD has created an ISO standards compliant C++ compiler that can create binaries that run on both CPU and GPUs from the same source code. This compiler works with code written in C++ 11/14, C11, and OpenMP 4.0 and is built on top of CLANG/LLVM. It also enables optimizations for low-level memory placement controls like pre-fetch and discard data movement. More importantly it enables the use of asynchronous compute kernels and scratchpad memory support which have the potential to really boost performance on AMD’s hardware.
HCC is a pretty novel creation that leverages AMD’s work with HSAIL and the focus on enabling heterogeneous computing through compilers. If you want more specifics on how it works, I highly recommend that you read this paper that AMD published on HCC.

Most HPC applications are written in CUDA to run on Nvidia’s GPUs. The closed ecosystem surrounding CUDA makes it difficult for customer to move from Nvidia to AMD’s hardware. That is being fixed today using a runtime that AMD calls HIP for Heterogeneous-compute Interface for Portability (HIP). Using AMD’s HiPify tools you can generate HIP code from CUDA code and then compile it using AMD’s new HCC compiler to run on AMD’s GPUs or compile that same HIP code using Nvidia’s NVCC.
HPC developers, like most others, want to write code once and run it anywhere without having to worry about platform specific details. HIP allows you to develop code in CUDA and then run that code on both AMD’s and Nvidia’s hardware. While HIP doesn’t outright enable that dream it sure helps bridge the gap between an existing CUDA codebase and the C++-styled code that AMD’s HPC group is now promoting. It helps of course, that CUDA is already very similar to C++.
When pressed on why AMD isn’t just supporting CUDA directly AMD offered one big reason. The big issue is performance and AMD believes that porting HPC-focused CUDA code using HIP and then compiling and optimizing it using HCC will result in much higher performance on AMD’s hardware than merely running a CUDA binary on top of AMD’s hardware. Though HCC doesn’t offer this functionality at present, AMD did leave the door open to supporting the compilation of code from the open-source version of CUDA.

The steps that AMD is taking in building out its software infrastructure to attack the HPC market with the Boltzmann Initiative are impressive. There was some concern about how committed AMD would remain to enabling HSA and Heterogeneous computing through software efforts after the departure of Phil Rogers. As of today it those concerns appear to be unfounded. Individually the news that AMD is now offering HPC focused driver, a new compiler in HCC, and a way to port CUDA code in HIP would be big events, but together these announcements are game changing.
AMD’s GCN architecture has never really had the software ecosystem it needed to be a real option for the HPC market. Our sources at HPC server vendors have reported basically not selling any AMD hardware over the last year due to a complete lack of demand. The story up until now of AMD’s attempts to break into the GPU side of the HPC market boil down to offering great hardware with no software stack to back it up. With the Boltzmann initiative AMD is finally doing something to change that story for the better.
Taking a step back to look at the impact of this announcement in the context of AMD as a company we can see a trend developing. AMD’s Enterprise, Embedded, and Semi-Custom (EESC) group is on point and the products they’ve launched in the last few months show a much deeper understanding of what’s necessary to win in the target markets than any other group at AMD. Our only hope is that AMD’s dormant CPU/APU group and recently created Radeon Technologies Group learn from the example that EESC is setting.
If you want to find AMD at SC15 head over to booth 727. Don’t forget to ogle the 3U rack from One Stop Systems that uses 16 FirePro S9170 GPUs for a total of 512 GB of VRAM and 42 Tflops of DP compute.S|A
Thomas Ryan
Latest posts by Thomas Ryan (see all)
- Intel’s Core i7-8700K: A Review - Oct 5, 2017
- Raijintek’s Thetis Window: A Case Review - Sep 28, 2017
- Intel’s Core i9-7980XE: A Review - Sep 25, 2017
- AMD’s Ryzen Pro and Ryzen Threadripper 1900X Come to Market - Aug 31, 2017
- Intel’s Core i9-7900X: A Review - Aug 24, 2017