![]() Today Centaur is hinting at their first new x86 CPU in a while with details about it’s AI co-processor. SemiAccurate thinks the new CHA SoC with it’s CNS cores and NCORE AI accelerator is a very interesting device.
Today Centaur is hinting at their first new x86 CPU in a while with details about it’s AI co-processor. SemiAccurate thinks the new CHA SoC with it’s CNS cores and NCORE AI accelerator is a very interesting device.
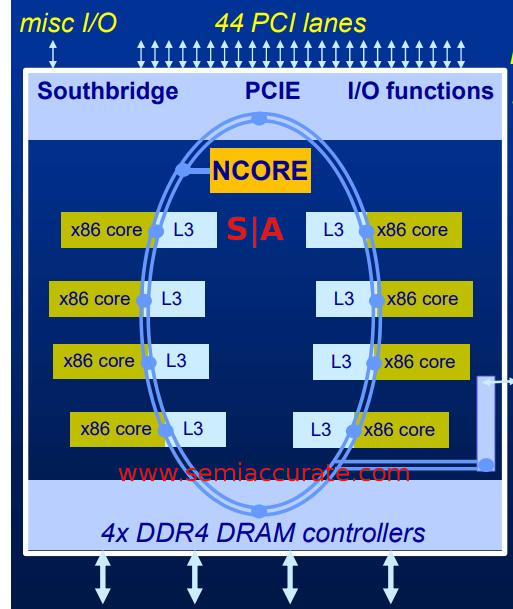
It as been a long time since Via’s Centaur division had a new core but it looks like it was worth the wait. The company now has CHA silicon in house and it is up and running. Not much was disclosed on the CHA/CNS side other than it is an 8-core CPU on a ring bus running at 2.5GHz. The core sports AVX-512 and all the latest goodies fed by four channels of DDR4/3200. This is not a wimpy core, it is full out 8C edge server CPU and the first one with a real AI co-processor. Better yet it all fits on a <195mm^2 die on TSMC’s 16nm process.

Yes it is real and it runs now
Before you point out that Intel CPUs have VNNI and will have BFloat16 next year, CNS have BFloat16 now and will have VNNI soon. What CHA’s NCORE brings to the table is a full on 32,768-bit wide, that is 4096-byte wide for the math averse, AI accelerator. That is borderline crazy wide but it has some very useful benefits. If you are latency sensitive, 4096 calculations in one clocks means very little waiting.
Hollow no more
The NCORE unit is literally sitting in the middle of the chip and it is on the ring bus as a peer even if it looks like it is mapped over PCIe. This is done for convenience of software, the CHA runs full Ubuntu and uses standard drivers, it isn’t a hack or weird architecture, just vanilla x86. With the first integrated AI accelerator. And 16MB of cache. Also 44 PCIe3 lanes in case you need to plug something else in to the box.
Most AI accelerators are just a bunch of dense MACs with the control logic elsewhere. NCORE does not take that route, it is a real co-processor that can DMA and do other tricks with the system and memory. It has it’s own internal memory, a generous 4K/MAC, which in aggregate supplies about 20TB/s to the units. That is a huge number but you need that to feed 4096 8b calculations per cycle, and NCORE can issue all 4096 instructions every cycle if the data is there. If there is a miss locally, NCORE can hit L3 directly and then go to memory if needed but this obviously take longer.

NCORE diagram and plot
The NCORE itself is arranged in 16 256B, not b, wide slices which each have 256 tiles of the aforementioned 4K of memory, 1MB total per slice. Eight of these slices are grouped on each side of a little logic and memory to feed the beast and parse out instructions, this is the processor part of the co-processor. This all sits on the ring bus with the CHA cores and everything else, that 16MB of total NCORE memory is all very local.
On the software side things are not fully finished with most of the major frameworks in process at the moment. Because of this, Centaur’s MLPerf listings are in the “Preview” section, not the “Available” category. Since the CHA SoC is not released and the software is very early, this is expected. Centaur says the current versions do better on the benchmark, much better on some, a little on others, and this should be reflected in the next MLPerf update.
Even with this early software, NCORE’s width means it wins all of the latency tests by significant margins, the closest second place in MobileNet-v1 Stream, a Xeon 9200, takes >150% of the time. Intel won’t divulge the MSRP of the 9200 but lets just say the CHA will be a double digit multiple cheaper and the Xeon will use a large multiple more energy. In MobileNet and ResNet testing, the CHA is >20x the core performance of the Intel Xeons, not bad for a company you probably didn’t realize was still making x86 CPUs. The price/performance of this CPU should be borderline unbelievable compared to the competition.
So why would anyone need CHA or use the NCORE accelerator? Easy, edge computing for things like camera/video analytics, network end point, and other aggregation areas. Aren’t there devices that already do that, even some with AI capabilities? Sure there are, but none run x86 code. If you want to run your current x86 based AI stack on the edge devices in a low power environment, there is only one choice, CHA from Centaur. That’s the key message and we have to say, it is a pretty good one.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024