![]() Today ARM launches two new server cores and a new servers platform too, say hi to the V1, N2, and V1 platforms. SemiAccurate thinks this is a very interesting forking of ARM’s server strategy with cores going after niches in a way that Intel can’t match.
Today ARM launches two new server cores and a new servers platform too, say hi to the V1, N2, and V1 platforms. SemiAccurate thinks this is a very interesting forking of ARM’s server strategy with cores going after niches in a way that Intel can’t match.
The Neoverse N2 is obviously an update to last year’s N1 core that has made waves in the market in chips like Amazon’s Graviton 2. The smaller throughput oriented E1 core doesn’t get an update, today anyway, but don’t be surprised if we see a new E-series in a few quarters. The big news however is the V1 core and the cunningly named V1 platform it rides upon. The roadmap looks like this.
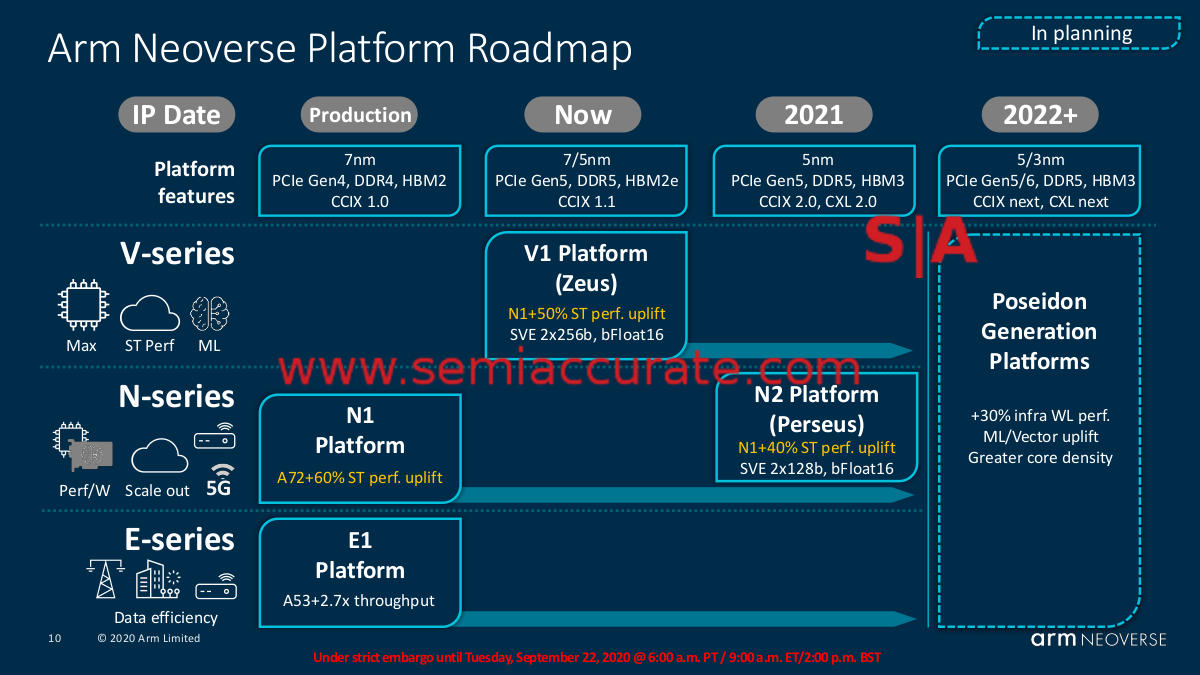
ARM Neoverse roadmap
In 2018 ARM promised an aggregate 30% performance boost every year with their server cores. Last year’s N1 was a claimed 60% uplift from 2018’s A72/Cosmos platform so even with a few caveats it is clear they met their goal and then some. This year we get the V1 (Zeus) platform with a 50% uplift from the N1 which again exceeds their goals. Next year comes N2 (Perseus) which is a 40% bump from N1 or about 10% less than V1 which doesn’t meet the 30% target for 2021 as long as you take things year by year. In aggregate 1.6 * 1.5 = 2.4 which is well above the 3-year 30% cadence of ~2.2x.
Assuming these numbers hold up in the real world, mission accomplished until Poseidon comes along in 2022 with a claimed 30% bump in performance. Thalia is next (1) with a laughable increase in performance, and yes you probably need to look up why. In any case as long as Poseidon doesn’t miss their targets by a large amount, the 30% claim looks like it will hold for at least another 3 years. As of right now, N1 appears to pummel Intel silly in Graviton 2 form, see?
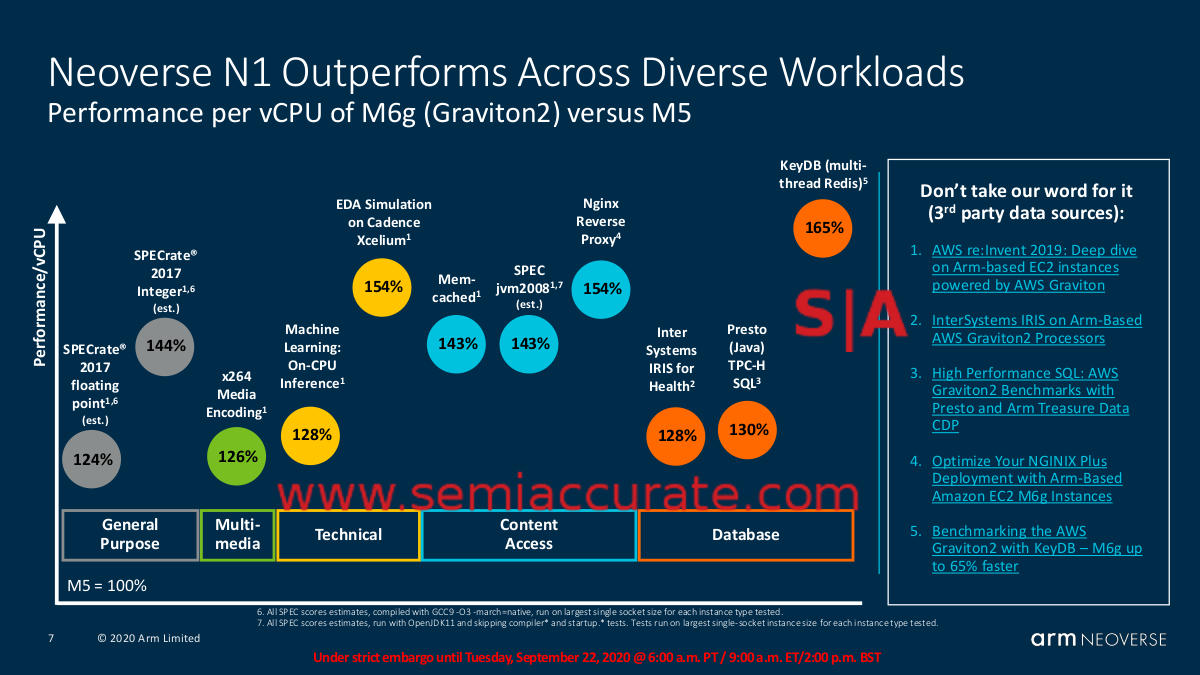
ARM N1 performance
So with such a commanding lead and Intel not coming out with anything that will threaten N1 until 2022 best case, why the hurry? You could say AMD and that would be fair, Milan is about to come out with a serious performance uplift so that is a threat. The real reason however appears to be tailoring different cores for different workloads, something AMD and Intel can’t do at the moment. V1 is not a bigger N1 and it is faster than N2 which comes out a year later. So why bother with N2 at all if V1 is faster and comes out sooner? Efficiency.
Here is where things get a bit nuanced. OK, they get a lot nuanced because V1 is 50% faster than N1 and a bit faster than N2. What V1 isn’t is more efficient than N1 or N2 which matters a lot to some and far less to others. Efficiency is not an on or off thing, it is a spectrum and can depend highly on workload and the rest of the platform. N-Series cores are aimed at average server workloads, E-Series cores are aimed at throughput and networking workloads, and V-Series cores are for HPC and heavy compute systems. Take a look at the diagram below, the ratios are what matter more than anything else.
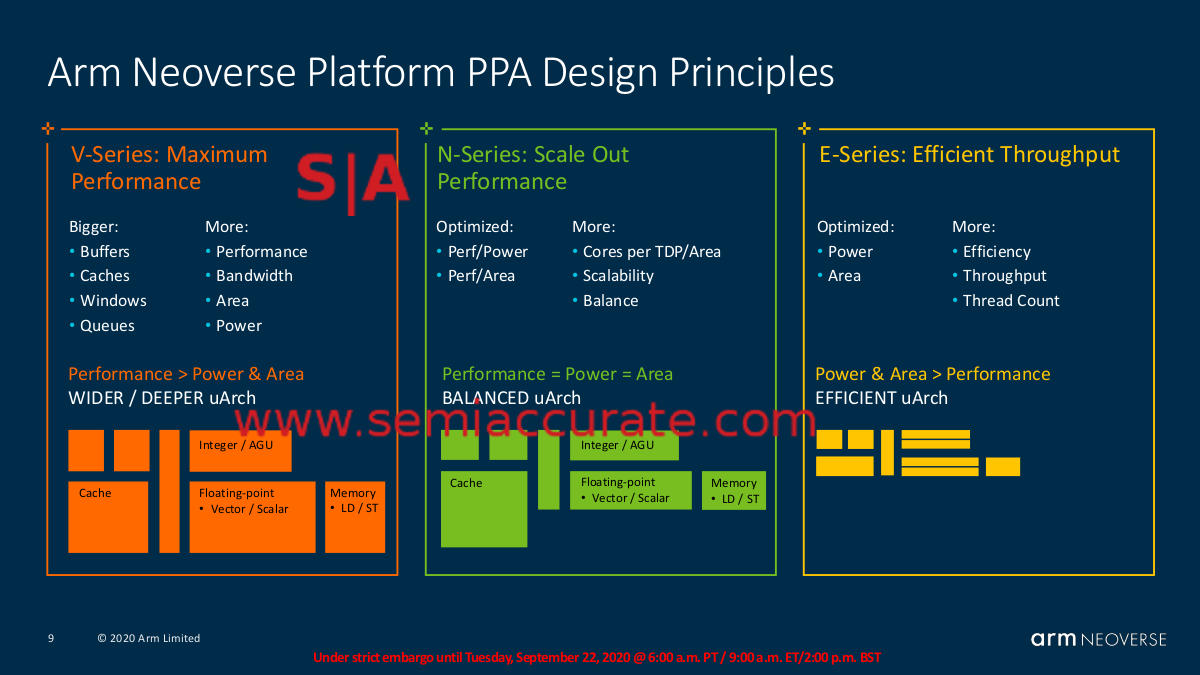
ARM core PPA diagram
As ARM says, V1 is a bigger core, takes more power, and does more work. To do the same job as an N1, V1 will do it faster and use more power to get there. As long as you can meet your service SLAs for a single thread, N1 is probably the better bet for TCO. If you need heavy compute for HPC work, V1 is probably worth the few extra watts it takes to get there, it will probably have a lower TCO if your code takes advantage of the features V1 offers.
What are those features? Bigger buffers, larger caches, more memory bandwidth, and 2x the vector width for SVE code. That last one alone is almost a clean kill for HPC assuming your code takes advantage of the ISA which most will. Basically you get more for more if you can actually take advantage of that more, some can, some can’t. Take a look at the chart below which ARM compares V1 to N2 at the rack level.

ARM V1 vs N1 core performance
If you are a little confused by the fact that the V1 has significantly more FLOPs per core and rack but the N2 has a bit higher performance per rack, that is good, you are paying attention. What they are saying is that if you have a normal server workloads with integer and FP workloads, N2 will be your best bet for these average, all around workloads. If you are doing heavy math work like FP laden HPC and simulations, V1 will be significantly faster. This best of both worlds approach is why ARM has two server lines, basically you can’t get the best of both worlds with one core.
Why not? V1 scales to 96 cores per die while N2 goes to 128, both practical limits rather than any specific platform limitations. The extra area of V1 is a problem but not the end of the world, the extra energy it uses is the real hard ceiling. If you don’t want to force water cooling on your partners, 250-300W is about your limit and that is what dictates the core count more than anything else. N2 can pack 33% more cores on the die so if you are doing web serving or things that require lower latency threads, N2 is the way to go. Sure you can water cool servers and force the issue but…. umm… learn from Intel’s folly of putting marketing over tech.
Then there is the last bit which is possibly one of the most interesting, packaging. AMD made waves with Naples and Rome for advanced packaging on volume devices and Intel is going further but only for low volume science projects. ARM isn’t claiming any specific construction technologies today but they are laying the groundwork for partners to do some very interesting things. Take a look a the roadmap slide above, then at the one below.
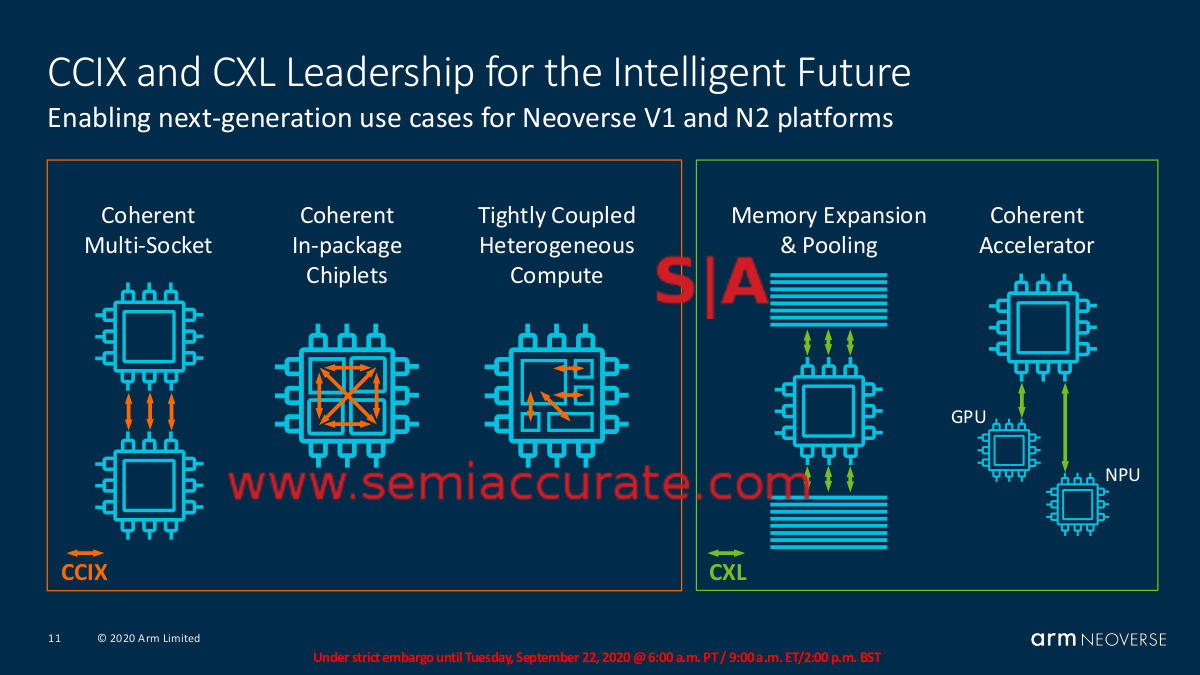
ARM’s interconnect strategy
N1 and E1 are claimed to have CCIX 1.0 or at least are capable of supporting it. CCIX 1.1 is in Zeus which bring some minor updates to the table but neither 1.0 or 1.1 are anything really important. CCIX 2.0 and CXL 2.0 in Perseus are the ones to pay attention to, they will bring the ability to make chiplets a reality and open the ARM world up to mix and match SoCs in a way that Intel talks about but is unlikely to ever get to. CXL adds external memory pools, coherent accelerators, and much more to the mix, and when coupled with CCIX, can be a game changer. While nothing is officially announced at the moment, in two years this will be the area to watch.
So in the end ARM is laying out a pretty comprehensive server roadmap. Sure they only design core IP and related bits but the parts announced today are going to allow partners to make some very interesting SoCs. The forking of the server cores will put serious pressure on AMD, Intel is basically out of the game at this point, and silicon vendors can tailor offerings to a much finer degree than ever before. Throw in chiplets and coherent interconnects and you have the basis for a comprehensive line of servers.S|A
(1) We just made that up and likely confused a bunch of people who know the real name. No we are not sorry but look on the bright side, at least we didn’t call it Euterpe and not point out it was a joke.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024