 AMD is finally talking about hQ or Heterogeneous Queuing, the final step in the Fusion integration of CPU and GPUs. hQ itself is more of a mechanism for software to utilize the hardware that is in Kaveri, but it will carry over in to much much more.
AMD is finally talking about hQ or Heterogeneous Queuing, the final step in the Fusion integration of CPU and GPUs. hQ itself is more of a mechanism for software to utilize the hardware that is in Kaveri, but it will carry over in to much much more.
Conceptually speaking hQ is a pretty simple idea to explain because at its most basic level all it does is allow the GPU to send tasks to the CPU. Of course this simple thing to explain has a lot of tech behind it, simplicity is usually the product of a lot of hard work. Before hQ the CPU could place tasks on to the GPU’s queue but not the other way around. Schematically it looked like this.
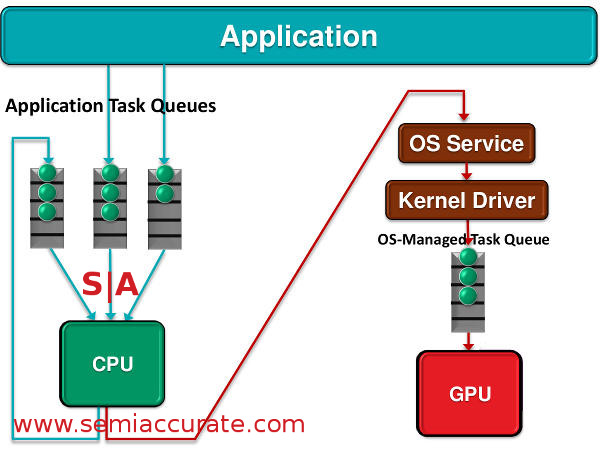
The old way or at least the way it is now
What hQ brings to the table is now this communication becomes bidirectional. More importantly look at what talks to what and the paths to get there in the diagram above. In the old way the application only talks to the CPU and then the CPU has to go through many layers of OS overhead to message the GPU. This overhead is called names like DirectX and drivers, something that Mantle aims to obviate as well. In the new hQ way of doing things not only can the CPU put things in the GPU queue but the GPU can put things in the CPU queue too.
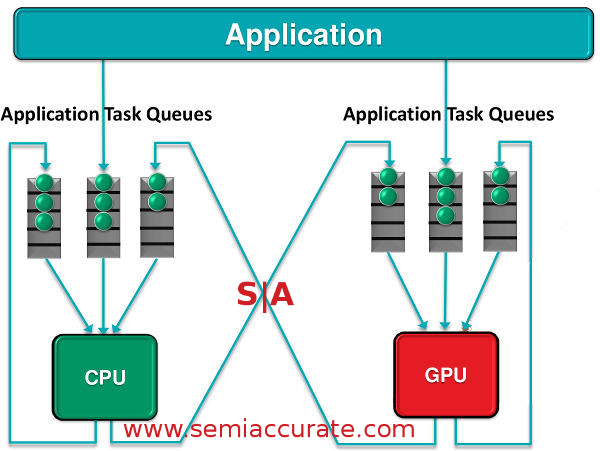
hQ is the basis for the new way
Probably the most important thing in the above diagram is that the application can talk to both the CPU and GPU directly, no OS overhead involved. Almost equally important is the lack of any performance sapping layers between the two compute units. Part of the reason that hQ brings the benefits it does, or at least it should, is because it cuts down on overhead. How does it cut overhead without software layers? A standardized packet format.
An application will put tasks in a CPU queue by making up a packet and putting it in a predefined memory location. When the CPU is ready it knows where those memory locations are and what formats the contents use. Since each packet is a fixed 64B long, this is easy enough to do with simple pointers. Likewise a GPU also has queues that work in the exact same way, memory locations, pointers, and a bit of magic allows the app to just dump work packets in the GPU queue as well. On an APU at least everything is effectively the same for CPU compute and GPU compute, the application just needs to pick what goes where and when. So far so pretty normal.
Where hQ gets interesting is that there are now mechanisms that allow the CPU, not the application, to place things directly in the GPU queues bypassing the normal software and OS overhead. Better yet the GPU can do the same thing, a GPU compute program can make up a task and seamlessly hand it off to the CPU with almost no overhead, basically pointer passing at it’s finest. Does this sound at all familiar? Remember column 4? If not, look at the picture below.
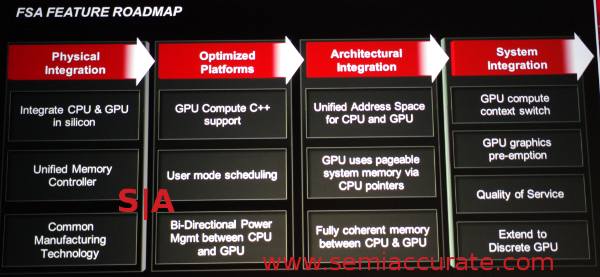
A four step program to the Fusion based future
Column four has GPU compute context switch and extend to discrete GPU, both of which hQ implements. Yes it works on a discrete card too, you can pass pointers to main memory locations across a PCIe bus too it just makes about zero sense to do because of latency overhead. Quality of service is on the list too and hQ could implement that as well but AMD isn’t talking about it yet. It doesn’t take much imagination to put a QoS value in to a reserved field on the packets and have a simple sort shuffle things around here and there. That only leaves GPU graphics preëmption to get to the wonderful world of Fusion but that is more of an AMD GPU architecture issue, not the realm of software queues.
So what are these wondrous packets that we keep blathering on about? The queue packets are just a 64B field that is placed in main system memory, nothing more. There are only two packet types, dispatch and barrier, both of which and a little more sub-type information are in the first four bytes. Following these are 14B that describe the workgroup and grid sizes, two bytes each for X, Y, and Z dimensions with two reserved bytes between the workgroup and grid descriptions. Four bytes starting at 24 describe the private memory allocation and the following four are for group memory allocation.
At byte 32 we have a pointer to an object in memory that has an implementation defined executable image for the kernel, effectively the code to be run. 40-47 contain the memory address for kernel arguments and the next 8B are reserved. The last 8B starting at 56 are the address of a signaling object used for task completion. This is all for the dispatch packet, we will skip the barrier packet as it is beyond the scope of this article.
These packets are placed in queues, heterogeneous ones if the hQ name didn’t give that much away already. Queues are assigned by the CPU and can be very large in size but once they are created the size is fixed to minimize overhead. The packets themselves also carry over this theme, they were architected to have only one level of indirection. As we said above since the application running, the CPU itself and the GPU can all place work packets directly into the queue of any other unit, the overhead is quite minimal.
Should the hardware queues not be sufficient there can be a thin software layer on top of it to manage even more queues, effectively infinite numbers vs the 50 or so in near future (read Kaveri) implementations. Please note these are not the same hardware queues as the GPUs have in the ACE, that is completely different.
Almost all of the hQ work is done in userspace with only minimal work done in the kernel. This minimizes transitions and the overhead they bring and also allows apps to do what they need to do without costly privilege escalation. Once again the idea is to minimize any performance sapping overhead that doesn’t need to be there in any way possible and it sounds like AMD did a pretty decent job of it too.
What do you end up with? In APUs at least a CPU can work on a program for the serial portions and then simply pass it to the GPU in the middle of a running task. Nothing gets interrupted from the user perspective and the latency is minimal. Parallel portions can then run on the GPU and then it can pass the thread back to the CPU when the parallel portions are done. On pure GPU workloads the GPU can request things from the CPU directly, allocate a buffer, run this code on a texture at memory location ABC, and many other things. In theory it is exactly what AMD promised Fusion would do 3-4 years ago when Llano first popped on to the scene.
One other question that many have been wondering about is how will this hQ work translate if you have a discrete GPU, AMD discrete GPU of course. The short story is that it will work but the performance may simply stink. One of the main reasons that GPU compute is a bit underwhelming in practice is the PCIe overhead eats all of the time saved by crunching portions of a problem on the GPU. In many cases it would be quicker to just crunch the numbers on the CPU rather than do some, send the rest, and wait. And wait. And wait.
For hQ and the related hUMA and HSA, portions of the technology that are available on the non-APU hardware should just work as intended but the real benefits brought on mainly by a single coherent memory space won’t be there. If your code needs this kind of flexibility you can either manually tune the kernel to do what you want and pipeline things to and from a discrete card or buy an APU. AMD probably prefers it if you do the latter one but will happily sell you a Firepro if you want to go that route too.
How does hQ figure out what is a good fit for the CPU and what is a good fit for the GPU? That is easy, it doesn’t nor does it attempt to. This problem is completely up to the coder to solve for the moment, nothing is automatic and nothing is done for you. This may change at a later date but for the moment it is all manual. AMD does say that the whole process is similar to normal parallel programing, just run your normal profiling tools on the code and anything they spit out a recommendation for parallelizing on is almost assuredly a good fit for the GPU.
In the end, hQ is pretty simple idea that builds on hUMA, HSA, and large amounts of careful work by AMD and the HSA foundation folk. Once again it is early on but the promise of supporting libraries, tool sets, and compilers is encouraging. Better yet a few languages with Java being the notable one are going down the path of supporting hQ and related technologies out of the box. Since Oracle is a kenote speaker at AMD’s APU13 conference next month you can safely assume a lot more on this topic will come out then.
Until hQ becomes adopted by the mainstream and transparently implemented it will be a tool for those who really need it. If you do the hard work it is very useful now and spending the extra time to code for it is worth the pain. For the rest just hold off a bit and if the software promises hold up like SemiAccurate thinks it will, hQ will just be there under the hood and you will never know it. You will however notice the results even if you can’t tie the two together.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024