 At long last, the saga of AMD’s Kaveri CPU has come to a conclusion with the release of the first chips in the family. Lets take a look at the details we have about the new device, what it does, and how it is different.
At long last, the saga of AMD’s Kaveri CPU has come to a conclusion with the release of the first chips in the family. Lets take a look at the details we have about the new device, what it does, and how it is different.
AMD held a tech day before CES to explain a bit about the chip but the actual tech part was woefully lacking. Apologies in advance for the huge gaps in the story, there was literally no time to get answers to the long list of questions we had about Kaveri. That said what we do know looks fairly interesting but it is more nuance than overt architectural changes. Fortunately those little changes can mean a lot, especially once software takes advantage of the changes.
You might recall that Kaveri was meant to be a late 2012 product before it slipped and slipped and slipped for 18+ months. SemiAccurate’s moles then told us the plug was pulled on the chip along with the big cores in the dark days of the reign of Seifert the First. These missteps were later undone with the revolution that brought a technocracy to the (almost) top of AMD, basically common sense returned. Unfortunately the delays meant that Kaveri went from a potential world-beater to playing catch up, something not helped by massive clock speed misses.
What is AMD delivering to eager buyers? Three parts called the A10-7860K, A10-7700K, and A8-7600 for $173, $152, and $119 respectively. All are on the same die, a 2.41 Billion transistor chip built on Globalfoundries 28SHP process using 245mm^2 of silicon all told. The GPU takes up 47% of that area so a little math gets us to 53% for the CPU side of the house. The fine print looks something like the chart below, and do note that each GPU core is 64 shaders in the old nomenclature or 8 = 512, 6 = 384.
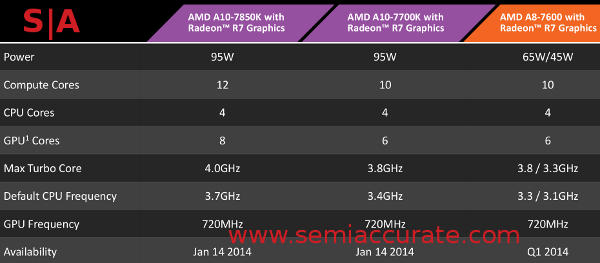
A few specs for a few models
First up is the process and it is an unusual one. GPUs need relatively low speeds and high density for optimal layouts, CPUs need high speeds and relatively lower density. What do you do for a chip that is nearly 50-50 CPU-GPU? Which one do you prioritize? If you are thinking that splitting the difference with a medium speed medium density process might work, that is effectively what AMD did. Needless to say there is a bit more math to it than that, but you can think of 28SHP as a custom middle ground process designed for APUs.
AMD telegraphed this move at Hot Chips 24 with a presentation about using high density libraries for the Steamroller core. As you can see the CPU clocks are pretty high peaking at 3.7GHz default frequency but the GPU side of the house only runs at 720MHz. Since the GPU is effectively a Hawaii part stuck beside a CPU, it should be clocked at Hawaii speeds approaching 1GHz. Middle ground in this case means more toward CPU than GPU, and AMD personnel SemiAcccurate talked to were quick not to place the blame on Globalfoundries. In short once the simulations catch up with the silicon, expect Carizzo to take a big leap in GPU performance.
You might have noticed that AMD now uses CC or Compute Cores instead of CPU and GPU cores, shaders, or other terms of the moment. The idea is that since a CPU can pass work and pointers almost directly to the GPU via HSA queues or hQ then the difference between the two types of units is almost negligible. Normally we would mock such claims, but for the first time Kaveri actually fulfills the promise of heterogeneous compute.
Although it still is a somewhat coarse grained threading model, work can be passed from one unit to the next with reasonable latency and efficacy. Because of the speed which this happens, the whole CC idea is valid but it is still really awkward to describe. In a few generations CCs will likely be much more accepted parlance but for the moment the tech is there, the mindset is still… umm… a bit yucky.
On the GPU side there are up to eight GPU cores each with 64 shaders identical to the Hawaii versions. We will skip over the details there because there is really nothing new to talk about for shaders. On the GPU front end Kaveri has eight ACEs which can each manage eight queues of arbitrary length as described in the hQ article above. They are all fully hardware coherent with the CPUs too, something not found in Hawaii because there is no CPU to be coherent with.
Most importantly, the ACEs in Kaveri can context switch, something not found in a pure GPU because it is completely pointless. In a CPU it is necessary if you want to multitask or have any concept of threading like all modern devices do. Context switching is one of the biggest advances in Kaveri, and more than anything is why the whole CC concept has substance behind the message. Once a GPU can context switch, it is essentially a very wide heterogeneous CPU, and that is exactly the point of Kaveri.
The Geometry Processor and Render Back Ends (RBE) have also been enhanced mainly to minimize off-chip accesses. This is the long way of saying enhanced caches and access to more sophisticated Load/Store Units. Off-chip buffering has been improved too, but the feeling we got talking to people involved was the real benefits came from not having to go off die as often as previous generations. Kaveri has 2 RBEs that can do 64 64b pixels and 256 Z-tests per clock.
More changes happened on the video encoding side with the unit going from VCE to VCE2. What changed? Not the Linux drivers that’s for sure, but H.264 YUV420 now can do B frames and YUV444 I Frames are possible too. The main reason for YUV444 is to take a whack out of wireless display latencies so I guess we have a console vendor from Japan to thank for this advance. On the decode side, UVD3 is now revved to UVD4 with the main difference being improved error tolerance and efficiency.
The last bit added to the GPU side of the Kaveri house is a TrueAudio unit identical to the one in CI and VI parts like Hawaii. A little birdie also told SemiAccurate that this unit is the PS4 sound system directly lifted without changes. If you were wondering who would support TrueAudio, the PS4 is the main dev target for this generation of consoles and it should be an easy port from there to Hawaii, CI, and now Kaveri. This is the long way of saying everyone should support it.
Moving back to the CPU cores, Kaveri has Steamroller cores, two groups of two cores just like Trinity. The main difference between the Piledriver cores in Trinity and the Steamroller cores in Kaveri is the front end. Decode and dispatch has been split up rather than being shared like in previous cores, eliminating a major point of contention. Additionally the microcode ROMs have been duplicated so there is no bottlenecking for access there either. In short most of the ‘advances’ made for Bulldozer were ‘updated’ to work right in Steamroller, that is to say removed.
Other than that, most of the claimed 20% peak IPC improvements, down from the 30% claimed at the Hot Chips talk, has to do with caches. The i-Cache is now 50% larger and 3-way associative, the branch predictor is much improved, and the scheduler goes from 40 to 48 entries. On top of this each Steamroller cluster can do two stores simultaneously to remove another big performance bottleneck. In short that 20% peak IPC improvement is worth a real world 10% average performance gain, something that would have been far more notable should the core have been released on schedule in 2012.
Tying these Steamroller cores together is a new coherent bus which AMD described as additional to the existing Onion and Garlic CPU<->GPU connection present since Llano. A bit more poking revealed that Onion has been replaced by a new fully coherent bus, not an additional pathway. What this bus does, how wide it is, and all the other important questions could not be answered because of the briefing timing. In short, a lot of the good things about Kaveri are found here but we can’t tell you anything more. It does, somehow, allow for system level atomics which are necessary for CPU and GPU task passing.
Kaveri comes in three versions that encompass three wattages, but the A8-7600 is listed as both 65W and 45W. This is because the new power management mechanisms in Kaveri are programmable to a degree not seen in previous AMD parts. There is a lot of interesting tech here but once again we can’t tell you anything more than it sounds like platform level power management is now supported but we can’t say for sure.
And that in a nutshell is Kaveri, Hawaii plus Steamroller with a coherent bus between them and heavily updated power management. Instead of CPU and GPU cores there are now Compute Cores or CCs, something that has actual technical grounding. All this is possible because of coarse grained pointer passing and context switching via HSA, hQ, and other related mechanisms coupled to system level atomics and coherency. Although it may not sound like much, what the hardware enables is a sea change for computing, especially on the server side. When the software catches up, Kaveri is going to be a very interesting part.S|A
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024