![]() At Hot Chips 28, ARM unveiled their SVE extensions for supercomputing. SemiAccurate will try to clear up some of what this vector extension does and why the Fujitsu Post-K supercomputer will use it.
At Hot Chips 28, ARM unveiled their SVE extensions for supercomputing. SemiAccurate will try to clear up some of what this vector extension does and why the Fujitsu Post-K supercomputer will use it.
The first point is that SVE stands for Scalable Vector Extension and it does indeed scale from 128 to 2048 bits in 128b chunks. It is an optional ISA extension for ARM v8-A/AARCH64 for use in supercomputing, not consumer or media type work. While it may fit some of those workloads, it is not NEON v2, it is separate and distinct by design. It also isn’t fully finalized and public, that release is expected in late 2016 or early 2017 with silicon bearing SVE not expected until 2019 or 2020.
Lets start out with the obvious part, the scalable bit because the core feature of SVE it is widely misunderstood. The nice thing about SVE is that it is vector length agnostic, your hardware can range from 128-2048b and the code can be written for 128-2048b vector units and they don’t have to match. If your vectors are 2048b wide and the hardware is only 128b wide, code will automatically run in 16 passes. If the code is 128b wide vectors and the hardware is 2048b wide, 15/16ths of the hardware will be powered down and a request will automatically be made to fire the idiot who wrote the code or specced the CPUs depending on who is the guilty party.
This is the long way of saying the hardware will automatically deal with longer vectors than it has physical units to deal with. No code is necessary, it will just work. It may not be optimal in terms of latency or hardware utilization but it will work. Given that the marquee customer is Fujitsu and their Post-K supercomputer which will use a 512b wide SVE pipe, you can be pretty sure their data will come in 512b increments. Others making SVE enabled silicon for similar projects can pick the physical widths to suit their projects.
One thing SVE won’t do is pack unfilled vector units with multiple disparate instructions automatically. If you have a 512b SVE unit and four independent 128b vectors, the hardware will not automagically run them in one cycle. If you have a compiler that can pack this type of work together before hand, you win, but the hardware won’t do it for you. This plus the ISA itself is why SVE isn’t really suited for consumer or image processing work. You do need to know your code and workloads if you want efficiency from SVE but it will cover up a lot of sins elegantly where other vector extensions would throw an exception.

SVE registers and architectural state
Now that we know the rough outline of SVE, what does it add to the ARM ISA mix? How about scatter/gather, per-lane predication, and predicate–based loop control. It all starts by extending the 32 128b NEON registers (V0-V31) with 32 128b SVE registers (Z0-Z31) plus 8 lane mask registers (P0-P7), 8 more for predicate manipulation (P8-P15), and one called FFR (First Fault Register). These are all 16b in length as are the three ZCR_ELx registers. These are control registers that allow SVE at the three privilege levels (EL1-EL3) and show the vector length available at each level. Why you would need different vector lengths at different levels I can’t explain, but you can set those registers if you really want to hobble SVE at a level.

SVE Predicate bits and states
One nice trick about SVE is that it re-uses the four ARM predicate flags Carry/Overflow/Zero/Negative aka NZCV for its own uses. As you can see from the table above, it is either a fascinating re-use of register space or needless minutia that no human will ever need to care about. In any case this predication can be per-lane and also used for loop control, and does so without introducing large chunks of additional hardware and overhead to non-SVE instructions and silicon.
ARM was concerned with efficiency for SVE and managed to cram the whole ISA into a 28b encoding space or 1/16th of the AArch64 instructions. Some of this savings came about by not needing to encode vector lengths and a bit more by dumping fixed point and DSP ops for media work. The biggest change came about when someone realized that constructive ops with predication are expensive to encode so they were summarily dumped. Destructive ops are what you get with SVE but if you want constructive you just use an instruction pair (MOVPRFX and ADD) which the hardware treats as one 64-bit op. You can also do it manually as two operations too but if the hardware is there…. All in all this and a few other low-level tricks allowed SVE to fit in a tight 28b encoding space.
One interesting side effect of this and the vector length agnostic approach of SVE is that vectors can not be initialized at compile and neither can predicates. The hardware will increment a register by the number of 64-bit dwords in the vector and then the predication logic runs a loop while that register is decremented by the number dwords that are consumed by the vector unit. Spills and fills of the vector registers must also adjust this counter as code runs. To simplify things, the hardware keeps track of the vector length the software wants to run and adds or subtracts from it as data is processed, the theory is simple enough.
If you have made it this far without one of those cerebral hemorrhages that neurologists admit they rarely see you are probably wondering how SVE deals with speculative vectorization, do they use predication to partition the vector? The answer of course is yes they do but that should be pretty obvious. If you are just picking back up after a long hospital visit and reading during rehab therapy sessions, this means that SVE code can speculatively pack a vector with elements and if one doesn’t show up by the time it is ready to execute, the hardware can deal with it.

SVE vector partitioning and FFR use
Operations that could cause these holes in the vector should be done in a partitioned vector. Those operation that could leave a hole should also be done after a break, aka a partition point. The hardware must be able to only execute the safe parts of the vector and then check to see if the rest is ‘safe’. If a problem is detected, the controlling loop must exit and the next partition is not executed. The hardware spec requires a CPU to detect a break condition that may result in a fault on a lane or lanes and then iterate through partitions until the break is found. This is where our old friend the FFR register comes into play as you can see above.
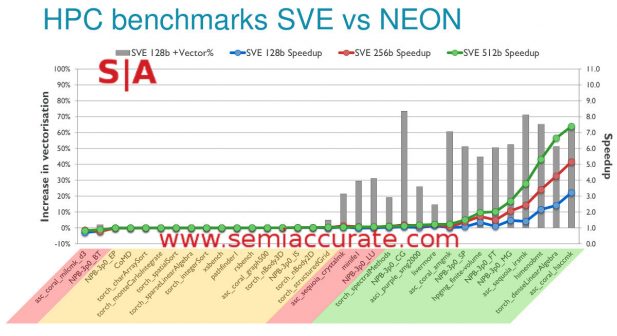
ARM SVE benchmarks at last
So how well does SVE do? As you can see above in some things not very well but in others it provides a massive jump, >7x what NEON provides at a 512b SVE width. This is why Fujitsu picked the ARM ISA to replace Sparc in their Post-K supercomputer, with SVE it can now do the heavy vector work required of a supercomputer CPU. Add in scatter/gather and all the rest of the goodies and you have the basis for a number crunching monster. The only down side is that it is designed to be an HPC/supercomputing monster but not a consumer image processing beast. Luckily for the consumer, there are already solutions in that space, start out with the 2x 1024b wide DSP units in the Qualcomm 820 , for now that should get the job done. For the rest, SVE hardware will be here in a few years.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024