![]() AMD’s new Vega GPU architecture changes things on two fronts, on die and off. Of the two the off-die seems the most fundamental change to SemiAccurate but both bring ground up new tech to GPUs.
AMD’s new Vega GPU architecture changes things on two fronts, on die and off. Of the two the off-die seems the most fundamental change to SemiAccurate but both bring ground up new tech to GPUs.
During CES AMD unveiled a bit more about Vega including some high level architecture details. It isn’t the full technical deep dive but there is a lot of information to be had. What’s more interesting is when you start asking how it ties into the other technologies they have introduced lately, SSG being a key one. The bits that make a gaming GPU into an AI device like Instinct also benefit from these changes too.
Vega at a high level
Lets start out with the obvious changes, the three on the left. If you are familiar with GCN architecture devices like Hawaii, you probably realize they are getting a bit long in tooth. The architecture isn’t bad but the process nodes it was originally meant for have long past and the optimization points for 16/14/10/7nm call for fundamentally different methods. Those changes require both shader level and device level architecture changes and that starts with the engines and pipelines.
First on the list of big changes is a really big bang, think DX9 or geometry shader addition. It is called the Primitive shader and it is lumped under the heading of New Programmable Geometry Pipeline. The old way of doing things was to have separate pixel, vertex, and geometry shaders fed by a compute engine (ACE) or geometry command processor (GCP). These fed the Geometry Processor and then the various pipelines, Vertex Shader(VS) then Geometry Shader(GS).

Pick your path wisely young learner
With the new Geometry Pipeline things are different. You can still do things the old way or you can take a new path, the Primitive Shader(PS). As you can see above, the PS is a separate path from the normal VS->GS path. While low-level details are going to wait a bit more for disclosure, the PS operates on higher level objects than the old path and can discard primitives that are not drawn at a much higher rate than before.
The PS path is much more programmable than before, the older pair of shaders were less flexible. Programmers will have to pick the new way of doing things but once they do, they have much more ability than before to use features from both domains to get the job done. In theory this allows new ways of doing the work of the old shaders, presumably more efficient ones too. I wonder what could catalyze the game devs to change their ways? *COUGH* consoles *COUGH*
One Achilles heel of the older GCN devices was they had a lot of ACEs but one GCP. AMD isn’t talking about the fine structures of Vega yet, but they are saying that the Geometry Pipeline can launch threads at the same rate as the ACEs launch compute threads. This implies multiple GCPs or at least a massively threaded GCP.

Cross-draw call logic is the important bit
This implication is bolstered by the slide above, it is likely that the Intelligent Workload Distributor(IWD) is the new GCP or GCPs, but it is also more than that. The key advance here is that the IWD does not schedule a pipeline or three, it is intelligent. Instead of looking at a draw call, it can look across multiple draw calls to optimally schedule for the device, not just the hot thread of the moment. This also implies one big IWD like one big GCP.
As always the devil is in the details but this could be a major change for the better in the utilization of the shaders on a GPU. AMD has always had a brute force advantage in shader math but utilization in the real world isn’t always optimal. If the new IWD changes this, it will be interesting to see how much of the peak performance Vega can extract on actual games. It should be higher than pre-Vega devices but by how much?
Now we come to the Next-Generation Compute engine or NCU. The Geometry Pipeline was new, this is Next Generation (Cue scary music from a 1950s TV monster show). AMD gave out some top-level specs on this unit starting out with a peak rate of 128 32-bit ops per clock. Actually they listed it at 512 8b ops or 256 32b ops per clock with a configurable DP rate. This one is interesting because if they are calling the NCU the replacement for an ACE, that would mean the listed rate is per unit. If you recall Fiji/Fury had eight ACEs, Vega will likely have more. This number puts the device in perspective unless AMD is calling an NCU a shader group, then the numbers make a lot more sense but the higher level bits don’t.

Pack em in to the shaders
There are two interesting bits about the NCU that likely necessitated a ground-up redesign. The first and more minor is the packed math operations we talked about for Boltzman/ROCm. Like it’s Polaris predecessors, Vega can do 2x 16b ops per clock or one 32b op, the non-packed 16b math is kind of useless but legacy code likely demands it’s use of opcode space. There is also a limited but not called out ability to do 2x 8b ops but not 4x 8b packed ops. These packed functions are aimed directly at AI work but could have limited use in gaming until packed 16b cards become the majority of the installed base.
The next one is the biggie, AMD claims the “NCU is optimized for higher clock speeds and higher IPC”. Remember that ground up redesign we harped on earlier? It looks like AMD is going down the same path as Nvidia did on clocks for much the same reason, the ‘old way’ is less efficient on modern processes with modern memories. Higher GPU clocks are going to be the norm now and you can point a finger at energy efficiency as the cause. Please note that this is a good thing for all the right reasons.
Higher IPC and clocks lead to much higher performance but graphics are not solely about brute force, you can’t render a modern multi-million polygon scene with all the effects turned on anymore without cheating. That cheating, or optimizing as most would call it essentially means the GPU or the game engine only does the least work possible to render the scene. Anything that would not end up as a visible pixel, visible being the important part, is work that does not need to be done. Worse yet it takes cycles away from useful work that needs to be done.
One of the biggies in this area is the key point for the other next gen feature of Vega, the Next Generation Pixel Engine or NPE. Cue the same scary music as last time. The main addition to the NPE is something AMD calls the Draw Stream Binning Rasterizer. It is a smart rasterizer with a newly added cache called the on-chip bin cache. It does about what its name suggests, it caches primitives.
The idea here is to save fetches to off-chip memory to pull in polygons as needed for rasterization. Going off chip is very expensive both in time and for energy consumption. With a smart cache AMD can likely avoid fetching a polygon or primitive more than once, or at least vastly cut down on the number of multiple fetches. This is a classic case of not doing unneeded work, and like backface culling and hidden triangle removal, it makes a GPU do a lot less busywork. You can think of the DSBR as a cache aware scheduler that can do non-coherent pixel and texture memory accesses from a dedicated cache.
If you are thinking that is really cool but would need a larger backing cache to be effective, you hit the nail on the head bringing us to the next point. All three of these new features, both next-gen and new alike, are all now clients of Vega’s L2 cache. Officially the claim is that this change will help a lot with deferred shading but it opens the door to a lot of hacks. What those hacks will be are yet to be seen, but a large universal L2 cache is never a bad thing for software trolls.
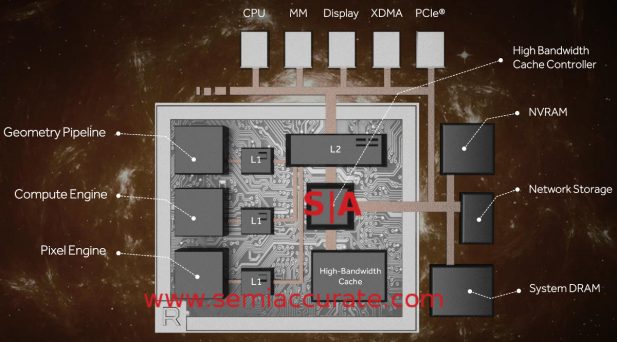
How do you feed this beast? That steps us out farther to the HBC or High-Bandwidth Cache and HBCC or High Bandwidth Cache Controller. AMD was a bit vague on what does what and why. If you look at the system diagram above, it becomes pretty clear that the HBC is a large dedicated cache for the HBCC. This may seem counter intuitive to have a second large cache besides the L2 but the HBCC really needs it.
The HBCC is probably the biggest reason that Vega is a ground up redesign, it is the biggest advance in a long time for GPUs. Why? Think 49b addressing or 512TB of space. Think SSG. Think coherence across systems, racks, and datacenters. Eventually. But for the moment the HBCC enables many of the things that AI developers drool for. The system diagram above shows it is directly connected to NVRAM, remote storage, device DRAM/HBM2, and the entire system. In short it is much more than a memory controller, it also does storage, PCIe, and a lot more.
HBCC can also do SRIOV natively so virtualization, a key to the professional space, should be childplay for Vega. In addition the HBCC is likely the controller for the BAR or Base Address Register. This is key to the multi-device 49b addressing, it sets the space where the native memory blocks of the device and storage it owns reside allowing for a coherent memory space for the entire system.
A remote card can just access the Vega assets via RDMA or anything else, it just calls to the appropriate space and the HBCC likely does the rest. Internally Vega sees its memory space and storage as 0-xyz, externally it is presented as (BAR+(0+xyz)). I can’t wait until AMD gives out more details on how this works, it is going to allow some very impressive things at the system level. Think of the HBCC as a fine grained memory controller with direct access to anything RDMA-able be it on the system or off. GPUs are now capable of seeing a cluster directly, don’t underestimate this change.
All of this is nifty but poses a big problem, how do you move the data around? That is the job of the new Infinity Fabric we told you about on Instinct, more when we get the details. The important point is that Vega is now a mesh architecture rather than a more fixed path device like past GPUs. Once again these low-level details were not disclosed but the Vega architecture should scale well past 2900. (Note: You will get it or you won’t)
So that in a nutshell is what we know of Vega so far. It has new everything because of the HBCC and memory structure, higher clocks, and more. None of these things were possible with the older GCN architecture, it had brute force but it’s elegance waned with time. Vega represents the first new AMD architecture since the advent of GCN sometime in the mid-1970s if memory serves. I for one am willing to bet the details will be a lot cooler than high level features suggest.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024