![]() Now that you have had a brief overview of Vivante and their GPUs, it is time to dive in to the details. Lets look at the tech behind the GPU itself to see how it achieves its efficiency and performance.
Now that you have had a brief overview of Vivante and their GPUs, it is time to dive in to the details. Lets look at the tech behind the GPU itself to see how it achieves its efficiency and performance.
Note: This is Part 2 of a series, Part 1 can be found here.
Architectural Overview:
From the top-level view there are some immediate differences between the Vivante GPUs and a standard GPU, the most notable being a separate 2D, 3D, and Vector engine. This will be important later but the one thing to keep in mind about the Vivante architecture is that it is really modular. Most ‘full size’ GPUs are also modular but only to the extent of halving the big one to get the mid-range product, then chopping that to get the small one. As we mentioned in the earlier overview article, many of the changes Vivante made to their 2006 device were the removal of features to save area and power. This is done on a very granular level to an extent not possible with desktop GPUs. How? Read on.
The GPU layout you see below ‘full’ Vivante GPU but do keep in mind many implementations don’t have or need all those units. How much or how little gets implemented, and more importantly the way they are implemented is up to the silicon vendors. For example the Chromecast doesn’t need a fire breathing 3D engine but 2D is absolutely necessary as is the compositing engine, same for the OMAP 4470. The Marvell PXA988 in the Galaxy Tab 3 7″ needs 2D and 3D but probably not a hardware Vector engine, an i.MX6 for the automotive world needs the Vector pipe and possibly 2D but not much more.
On a macro scale that is pretty cool, use what you need and only pay the power and area penalties for the functionality used. This is very different from the CPU world where Intel for example fuses off things like AES-NI and Transactional Memory to extort money from customers. In the Intel case all the transistors are there and work, Intel just turns them off if you don’t pay up. In the Vivante case the transistors aren’t there period. While some of the big guys do actually remove features examples are few and far between. In the Vivante architecture each of the sub-units like 2D, 3D, and Vector are independently scalable as well.
Where things get really interesting is how granular the removal can be. One Vivante 3D core can have between 1-4 GPU cores, each GPU core can have between 1-16 Shader Cores, and each of those Shader Unit Quantums (SUQ) can have up to five math pipes. Those pipes in the SUQ are 64-bits wide in the full configuration but can go lower if less precision is needed. If you want the full 4/16 configuration with full precision, great. If you want 3 GPU Cores with 9 Shader Cores each and half-precision SUQs, fine by Viviante. When we talk about modularity, it is on a completely different level than what you are used to on desktop GPUs and CPUs.
The top of the architectural diagram is dominated by the memory controller and bus structures, a GPU that can’t talk to anything is of little good. The busses present are AHB and AXI, the two ARM busses that you would expect to see in anything aimed at the mobile space, both connected to the Host Interface unit. This does exactly what you would expect and talks to the outside world in the language of ARM. The most notable bit here is that the Host Interface can be clocked independently of the main GPU allowing for frequency scaling on both sides. This is a must in any modern SoC for power savings reasons, you wouldn’t get very far trying to sell IP without it.
Thanks for the memories:
Below that is the memory controller, another must for any modern GPU with pretension of compute capabilities even if it is somewhat of a misnomer. The functions that a person thinks of as a memory controller happen on the CPU be it ARM, MIPS, or any other architecture you use in that capacity. A second full memory controller would only lead to lots of confusion and hilarity in the form of inconsistencies so as is the norm, the Vivante GPU memory controller is subservient to the CPU memory controller.
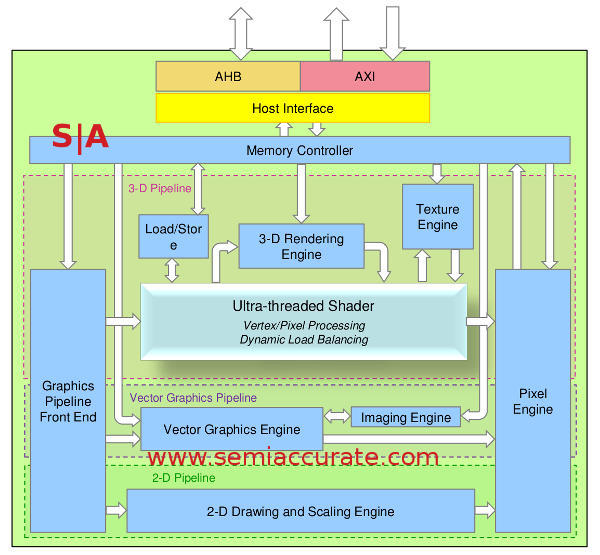
Architectural overview of a Vivante GPU
What the GPU memory controller mainly does is aggregate requests from the various units and shaders then arbitrates I/O requests. It mimics the ARM MMU as far as the GPU units are concerned and mainly prevents the hundreds of GPU functional blocks from stepping on each other’s toes. The aggregation side means a more efficient and lower energy use of the bus, I/Os, and memory. Why make two inefficient calls when you can make one? Lastly the GPU MMU has fully programmable page sizes, a must for widely differing CPUs or use cases, and fully supports the ARM security model. This essentially means that if a page the GPU used came from a secure memory area, the MMU can notify the system of that correctly.
One addition to the MMU that is technically part of the 3D pipeline is the Load/Store unit. This is the block Vivante had to add to the original 2006 chip to meet OpenCL 1.1 specs years later. It allows 3D shaders to have direct memory access for compute reasons, necessary for any of the modern complex shader and texture twiddling that is all the rage. OpenCL, Renderscript/Shaderscript, and DirectCompute all require such a unit.
Front ends and control:
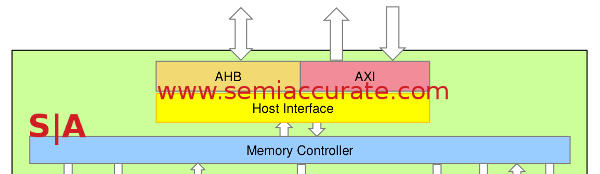
Vivante Bus and MMU diagram
After the memory and I/O system is passed through the next logical step is the Graphics Pipeline Front End (GPFE). This is something akin to a corporate mail room, it takes high level primitives and commands and puts them in the correct pipeline. You may notice that it is associated with the three pipelines, 2D, 3D, and Vector because it controls all three. If you put a triangle down the pipe it goes to 3D, a vector object to Vector etc.
This isn’t to say it is a dumb unit, it has full DMA capabilities and can access the CPU command buffer through the AXI bus. On top of that it does format conversions and process scheduling as well. There is a lot to juggle here and as you might expect, this type of unit is where many architectures become bottlenecked. The easiest way to alleviate that problem is to put in more independent schedulers in parallel like AMD did in the SI -> CI architecture transition and Microsoft implemented in the XBox One’s GPU.
Vivante took a different route and it is one that seems to be fairly common in mobile and low power architectures, they put more cores in. If your single GPFE can handle the throughput needed by one of your cores and a client needs more shaders, what do you do? Just adding more shaders will mean the front end is the bottleneck and the rest of the units go idle. If you add more performance to the Front End, complexity and therefore power use can grow almost exponentially. In a mobile GPU this is not a good thing.
Remember when we said the Vivante architecture can have four cores with 1-16 Shader Cores in each and a variable number shaders in each SUQ? If you know your workload is going to be bottlenecked by the complexity that the Front End has to deal with, two GPU Cores with 8 Shader Cores each is a much better choice than one GPU Core with 16 Shader Cores. While many mobile cores offer this flexibility, a similar type of granularity is only just creeping in to the desktop space. When we keep talking about foresight bear in mind that this is an architecture that debuted in 2006.S|A
Note: This is Part 2 of this article, the next installment will look in to the 3D unit itself.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024