![]() ARM was talking about CCIX, the new interconnect SemiAccurate told you about in May of 2016. You might recall we were enthusiastic about the technology and yesterday ARM went into detail on why it is really neat.
ARM was talking about CCIX, the new interconnect SemiAccurate told you about in May of 2016. You might recall we were enthusiastic about the technology and yesterday ARM went into detail on why it is really neat.
The basic idea behind CCIX, pronounced see-six, is to make a single coherent interconnect for CPUs, SoCs, racks, and accelerators, IE one bus to rule them all. Why is it cool? For starters it is a triply nested acronym, but it is the tech that really is interesting. Essentially you take PCIe, throw out the heavy parts, basically the transaction layer and above, and keep the good bits. Starting with the PCIe Data Link Layer and Physical Layer, you put a CHI based CCIX Transaction Layer on top, plus more. It looks like this.
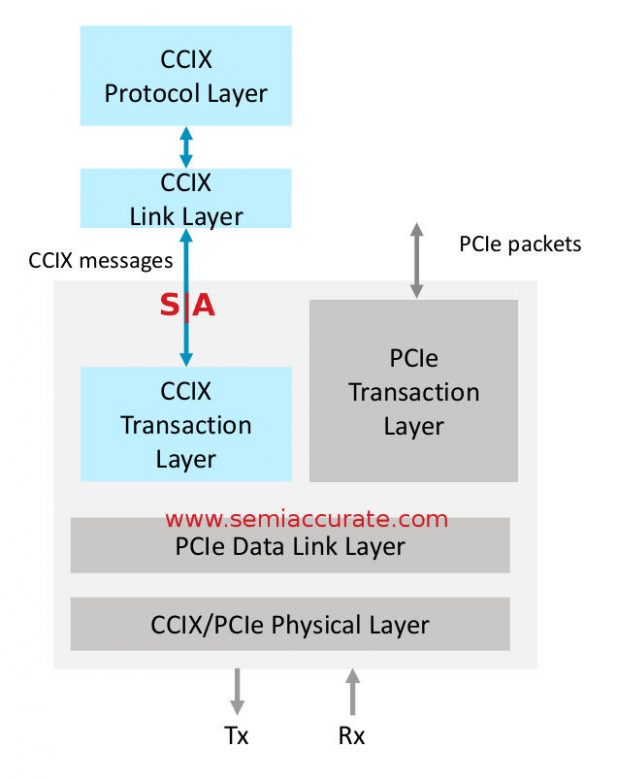
Layers but not a cake
The idea is twofold starting with re-using the PCIe physical layer where applicable. This allows you to use external bits like PCIe switches like the PLX/Avago devices. Since you are stripping out the PCIe transaction layer and replacing it with a CCIX version, you can redefine a lot. This redefinition is basically a stripping out the ‘heavy’ parts of the protocol and replaces it with, more or less, a subset of the ops plus a few more.
There are two sub-flavors of CCIX messaging, one meant to work over PCIe and one for CCIX only links, determined in the header. Some message types are completely eliminated, others like packing CCIX messages into a single PCIe packet added. The most interesting type of these is for request and snoop chaining. Since the accelerators are going to be memory mapped and likely have large areas walked through sequentially, the chaining allows you to read or write sequential areas without having to resend the address every packet. This drops bandwidth usage quite a bit. These kinds of optimizations and added lightness are all over CCIX.
On the physical side ARM was showing off a video of a 25Gbps phy, aka PCIe5, working with CCIX hardware. They also claimed a 56Gbps Phy, aka PCIe6, was quite doable too. Someday. This means the future is something between understood and bright. One problem is controllers in the 25+Gbps region, 16x controllers at those speeds are going to be a bit complex. CCIX gives us a way out with port aggregation. If you want a 32x link on PCIe you are out of luck, CCIX bakes this in to the spec. It may not seem all that important but if you look at where CPUs and accelerators are going, this function will be very useful for designers and storage architects.
Going down into the weeds a bit, CCIX starts out life on boot in UEFI. The firmware enumerates the devices and maps them as memory before the OS starts. This is similar to the way things are done now in some aspects, or at least the way they were supposed to be done but somehow turned into a big ball of annoying incompatibilities. With CCIX when the hypervisor or OS starts up, it should see memory and a bunch of memory mapped blocks which are in reality coherent accelerator ports on CCIX.
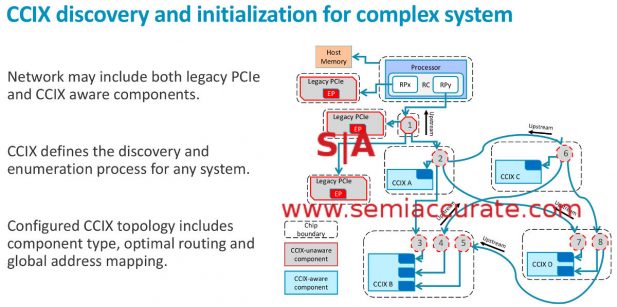
Easy and sane mapping
The first benefit here is that you don’t really need low level drivers. Interacting with the CCIX device is just reading and writing to a block of memory. Instead of low level languages or assembly, you can write your accelerator code in Python or Logo17 with memory access library extensions (Note: That is Logo bit is a joke but someone needs to do it just because). The bar to external hardware over CCIX is about as low as you can go.
Better yet on the OS side you don’t really need drivers. The OS doesn’t need to be aware of the CCIX device, it is just a memory region to use if a program wants to. For time to market reasons on Linux and other adult OSes, this is the killer feature, an OS kernel doesn’t need to be aware of the device at all, it is just a memory block. If an OS is aware of the CCIX device it can use a bunch of advanced features like error handling.
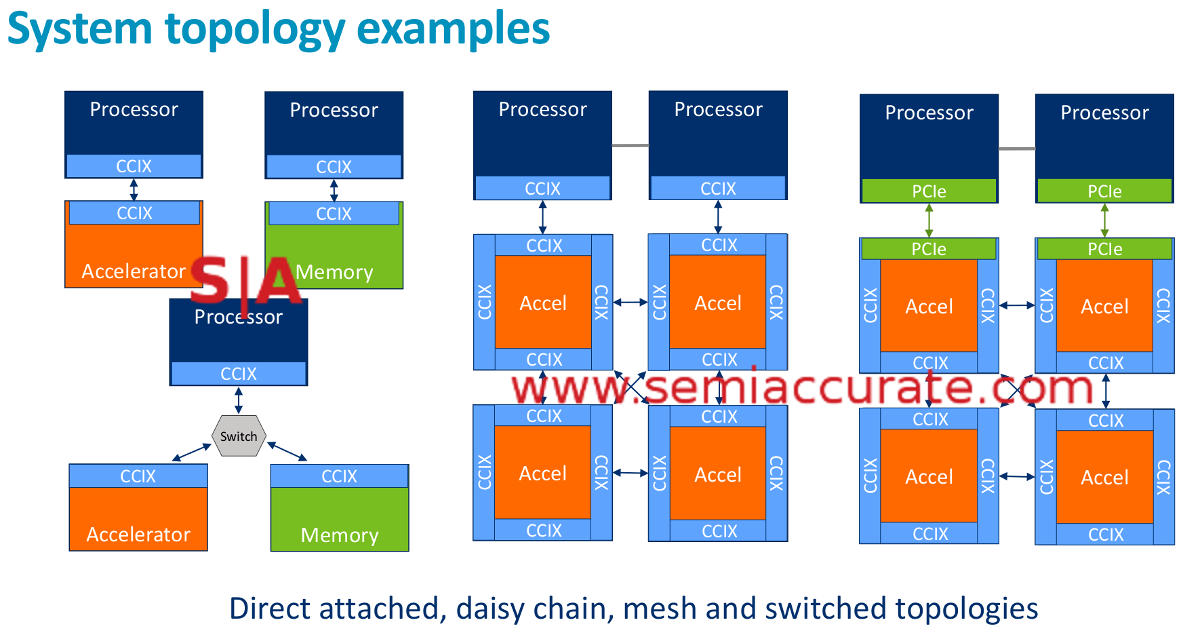
CCIX topologies, note the tight one
On the down side when you make something coherent, it can add massive traffic to your bus which slows useful data traffic and costs a fair bit of power. Both of these are ‘can’ not ‘will’ if done right may even be ‘won’t much’. Worse yet you can add latency, and a lot of it too. If an external device is mapped across a few external PCIe switches is accessed, it can take a lot of time to answer. The CPU/thread that requested that data stalls in the mean time. How this is handled depends on many things, and again ‘could’ hobble the main system. That said these are known issues and will probably be minimized in practice but being cynical we bring them up anyway.
So what do you end up with? A flexible architecture that simplifies the OS side of things, simplifies the driver/userspace side of things, and works with current OSes that aren’t aware of CCIX. It is coherent, light, and leverages existing PCIe hardware, and has few but potentially problematic down sides. Hardware should be out pretty soon and we will see the benefits first hand, or at least the big guys will first, by the time it trickles down to consumer parts it should be background ‘just works’ type stuff. And that is the way it should be, CCIX is going to be a big step forward.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024