 Last week Intel released their Cascade Lake Xeon x2xx series, the long awaited update to 2017’s Purley. Some see this as a minor bug fix, others see it as a new CPU, and SemiAccurate sees it as something in the middle.
Last week Intel released their Cascade Lake Xeon x2xx series, the long awaited update to 2017’s Purley. Some see this as a minor bug fix, others see it as a new CPU, and SemiAccurate sees it as something in the middle.
When Intel finally launched Purley it was seen as both late and missing a lot of promised features. Broadwell-EP was released in Q1 of 2015, Skylake-EP/Purley in mid-2017, a year later than the intended 18 month server release cadence. Several of the big features like Xpoint/Optane support and Speed Step were MIA as well. Now a bit more than 18 months after that we have the public launch of Cascade lake. All of those missing features are here and better yet there are four new ones.
If you look at the stack there appear to be 40-something SKUs but then there are the prefixes, mainly the memory based M and L variants available for seven models. Depending on how you view things this might add another 14 SKUs to the mix. Likewise the three -Y models with Speed Select on, are they new SKUs or just one bit not blown variants? Like with much of Cascade Lake it depends on how you look at things. What is important is that there are enough SKUs to fit everyone’s needs and a few more niches you didn’t know were needed, and that is before the off-list customer specific variants. Yup, there are a lot of SKUs for Cascade.

Don’t worry, there are really many more
Lets look at the overall picture rather than picking out each individual SKU. We will steer clear of pricing because that will be discussed in another article. In broad strokes Cascade Lake is priced similarly to Skylake and is a little faster, often a little cheaper, and basically a few percent more everything for replacing the x1xx with an x2xx. The interesting bits are in the new suffixes though.
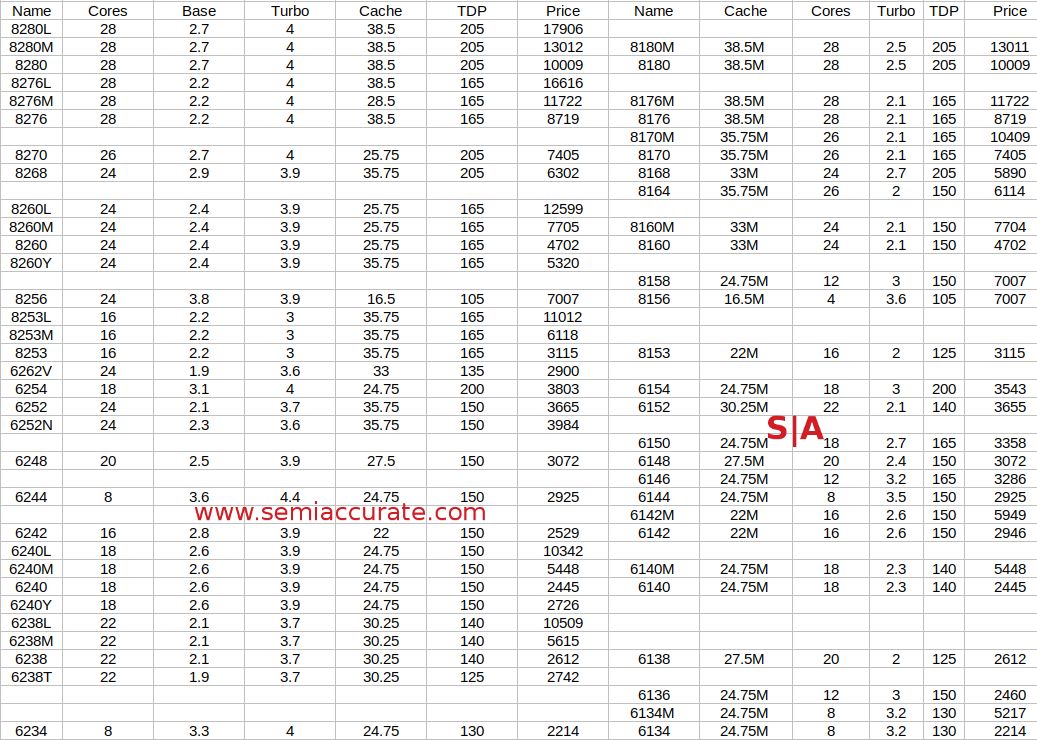
The details Part 1 (Note: You can click to enlarge)
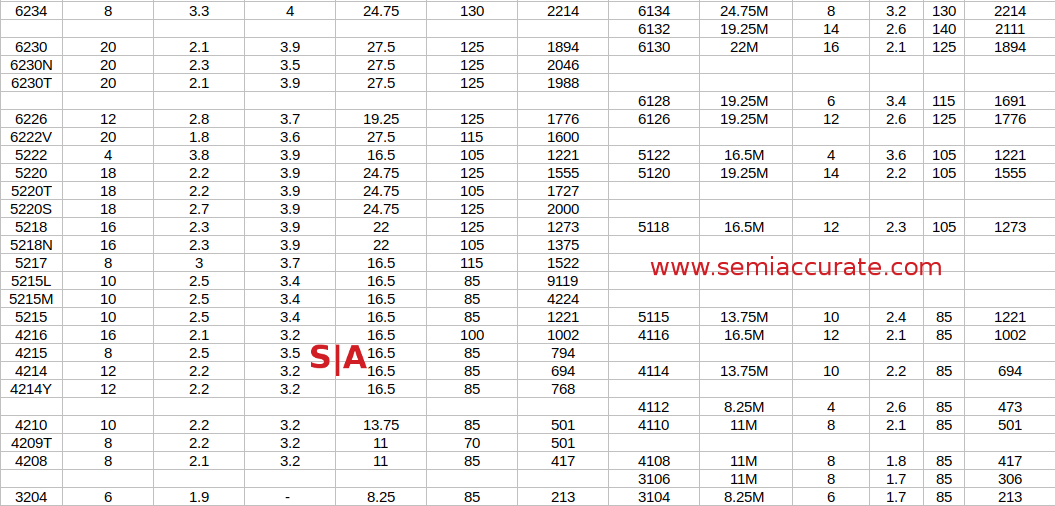
The details Part 2
When Intel announced Skylake-SP they had versions with a -M suffix. These parts were for large memory variants, Intel speak for >768GB of DRAM. For this they gouged users, that is the nicest term we can come up with, for an extra $3002. Our objection was not just a sheer price increase, 135% or so on the 6134/M, but what it said to customers.
At the time Intel stated that a tiny fraction of customers needed that capacity and the price of the memory dwarfed the memory tax, both of which are true. The problem is that it says, “you have a second class product” to all who don’t buy the ‘upgrade’, it makes the overwhelming majority of sales look worse. There is no up side to doing this, it seems to us to be a painful own goal on Intel’s part.
Luckily for Cascade, Intel didn’t pull the same stunt, instead they upped the cap to 1.5TB (Note: We know it has been reported as 1.5TB in other places but we were directly told 1TB by Intel last week), a good start. The problem is that there are now two memory suffixes, the -M for up to 2TB and -L for up to 4.5TB a socket. These upcharges for not blowing those fuses are $3003 for -M and $7897 for the -L meaning the lowest end 6238L would cost a hair more than 4x a 6238 without an L. Mumble mumble something indefensible price gouging mumble mumble.
Why is Intel doing this at a time when they have arguably the most vigorous competition in over a decade with AMD’s Rome coming, a swarm of ARM devices on the horizon, and likely more we don’t know about yet? Xpoint. Yes it is here and it is real, and if the claims that Intel made during our prebriefing hold up, all of our previous objections to the technology are have been overcome.
Those odd sounding memory caps are there for a reason which if you run the numbers make a lot of sense. Sky/Cascade has six memory channels with two DIMMs per channel. You need one rank of DRAM to cache the Xpoint so you can have six slots of NVM per socket. Xpoint comes in 128/256/512GB so six of each would be 768GB, 1.5TB, and 3TB of memory per socket respectively. While we do know there are some systems that support four DRAM and eight Xpoint DIMM configs we will ignore those for now.
The caps say to users that if you want more than 128GB Optane DIMMs you pay for an upgraded CPU. This allows the user to put in 16/32/64GB DRAM DIMMs to act as a memory buffer and be under the cap, so think of the -M as a 256GB Xpoint tax and -L as a 512GB Xpoint tax.
Monetary and fusing issues aside, the big deal is that Xpoint support is finally here if a bit later than originally intended. This was supposed to be a big selling point for Skylake-SP but didn’t make the timing cut for that chip. If your application needs massive memory sizes and/or ultra-low latency storage, then Xpoint/Optane might be a killer app for you. It is unquestionably cheaper than DRAM of the same size, a good bit slower, and has some caveats, but Optane is now available for real on Cascade Lake. You either need it or you don’t, there is little middle ground to be had but the technology is a big bang for Cascade either way.
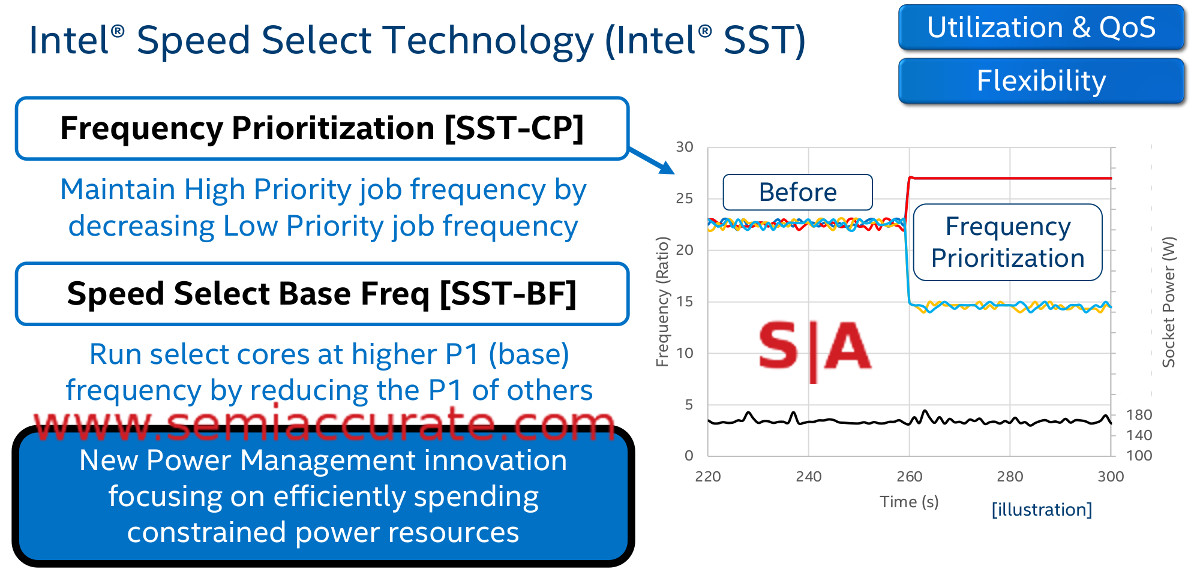
SST in one easy graph
The second of these big bangs is called Speed Step Technology (SST). The idea is easy enough to grasp, you can have a few cores running at a higher base (P1) clock by decreasing the P1 of the other cores in order to maintain the same TDP. The same also works for Turbo, pick some cores that will go higher than others while maintaining the same TDP. Each SKU with SST not fused off has five parameters that can be set in three profiles, Active Core Count, TDP, TjMax, Base (P1) Frequency, and All-Core Turbo (P0n) Frequency.
The idea is simple, many workloads have a single thread or part of the workload that bottlenecks performance with a serial task. The rest of the job can usually be done across multiple cores and/or often isn’t as compute intensive, basically Amdahl’s Law.
With SST, Intel is allowing two cores to speed up in order to churn through a bottleneck faster or to lower response latency. Jacking up clocks everywhere would do the same thing at a TDP cost which is far less palatable to some markets than you might think. All cores running faster also mean more wasted cycles on the non-loaded cores as well. If your app needs quick response times, SST is likely a very good thing if you are willing to put the time and effort into tuning it right.
There are two groups of suffixes with SST on, the -Y trio which just support the feature and the -N variants aimed at telco workloads. -Y SKUs are identical in every high level feature to the vanilla versions of their SKU, how it bins out is up to the buyer. Interestingly the -N SKUs are lower turbo frequency than their suffix free counterparts but have a higher base clock for the 6252N and 6230N while the 5218N takes the savings in TDP. It kind of goes without saying that for telcos, latency is king and SST will help quite a bit without blowing a hole in the power budget of your cell site. Once again this technology fits squarely into the category of, “If you need it, you need it, if you don’t, you don’t”, but it is new in Cascade and interesting.
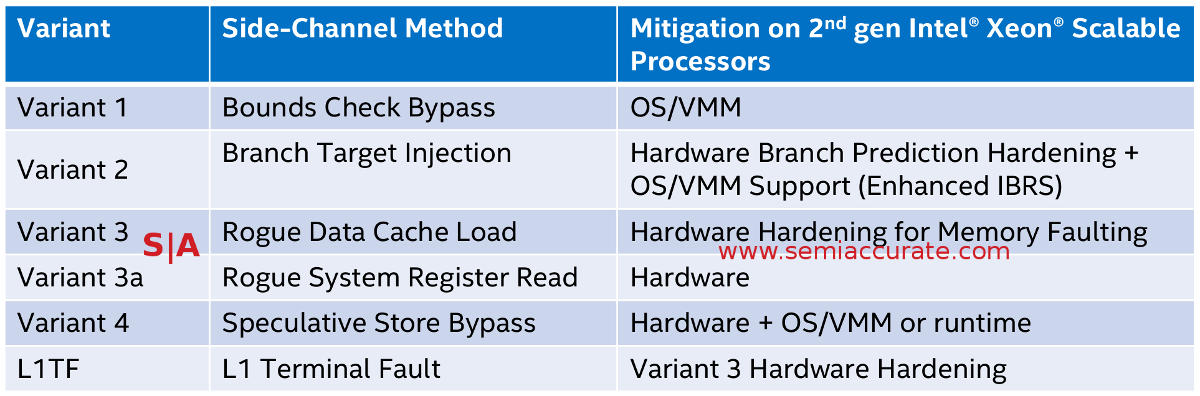
Some require software fixes, some don’t
Next up on the new items list are the Spectre/Meltdown fixes that have moved from software/firmware patches to hardware in some circumstances. There isn’t much to say where other than where hardware fixes were applicable, Intel has put them in. Some like Variant 1 and some of Variant 4 were software issues and still are, the rest are ‘solved’ for now, at least until someone comes up with new exploits.

Before and after a fix
One thing to think about here, hardware fixes are much faster than soft/firmware fixes but both take a speed hit versus an unpatched system. Hardware fixes don’t necessarily mean that the systems will be running as fast as a pre-exploit Skylake-SP box, just that they clawed some of the performance back. The exploits effectively target optimizations so to some degree the fixes are in de-optimizations.
Until there are architectures released who’s optimizations are not susceptible to such side channel hacks, a fix will mean lower performance to one degree or other. (Note: This is not a stab at Intel, it is true across every architecture, x86 or otherwise.) Hardware side channel exploit fixes are the first new feature in Cascade Lake that was not planned for Purley, mainly because these exploits had not been discovered when Purley was released.
The last of the four new features in Cascade is the big one, a new instruction set called VNNI. Intel calls this feature DL Boost but we refuse to use such abjectly stupid marketing names. At a basic level, VNNI is an INT8 MAC into an INT32 result. If you use a full 512b AVX vector to do this, you can process up to 128 8b values in one cycle using both units, a massive increase over the old way of doing things. Up to 3x the peak MACs per clock is achievable and there are also 16b versions of VNNI which have up to a 2x throughput increase.
If you are doing any type of AI or deep learning, this instruction set will be a big win for the user with little or no code modifications from a user perspective. Why? Because most of the low level loops that VNNI speeds up is done in libraries like CAFE an TensorFlow so if you just update those, VNNI should just work. Given the speed of change in the AI world, we think adoption of VNNI capable code will be both swift and ubiquitous.
One interesting technical note, when SemiAccurate first heard about VNNI we thought it was simply just a slight modification of existing data paths to support new widths. When we asked Intel architects about this theory, we were told that it was much more complex and doesn’t really reuse existing paths in the way we suspected. It is really new hardware built for purpose. When we asked about die area increases we were not given specifics, just told that the gains were very minor.
Other than those four big bangs there are a few minor updates to Cascade Lake like the highest supported memory clock is DDR4/2933 up from DDR4/2666. SKU to SKU things are updated as well with some retaining the same core counts while others went up but top line clocks generally got a bump everywhere. The Gold 5118 was a 12C CPU running at 2.3/3.2GHz base/turbo which cost $1273. The Gold 5218 is a 16C running at 2.3/3.9GHz for the same $1273. The 8180 vs the 8280 sees a clock bump from 2.5/3.8GHz to 2.7/4.0GHz for the same price but nothing more. In short depending on where you are shopping in the stack and where Intel is under pressure in the market from AMD, you might do a good bit better with Cascade or you might get almost nothing other than some of the new features. Since the prices are basically the same on the suffix neutral SKUs, there is no reason to stick with Skylake-SP at this point.
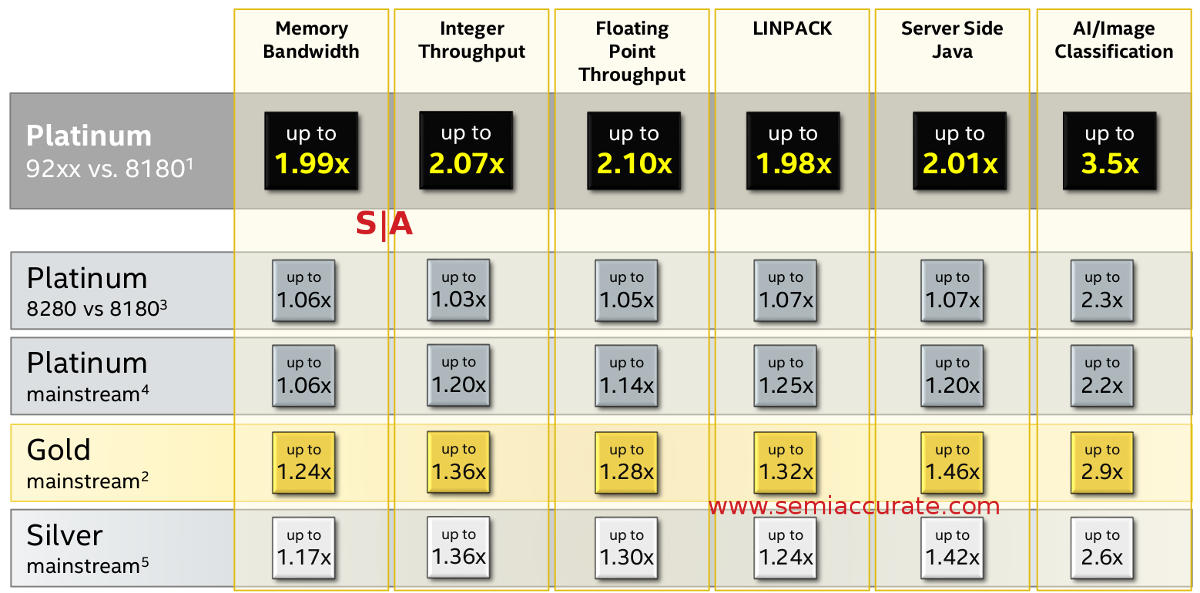
Top line is apples to apples
So how does Cascade Lake perform? Assuming you are a sane customer an applied all the Spectre/Meltdown patches, it is unquestionably better. Last August, SemiAccurate said Cascade would speed up, “6-8% on a per-socket basis“. If you look at the numbers Intel put out for performance, where you can compare same core counts to same core counts, it looks like we were right on the money. The up shot of this is better CPUs with more features for the same money, this is a clear win.
The problem for Intel is that in a vacuum, this is a clear win, with competition chomping at their heels it is not. 18+ months for a 6-8% performance increase is not a win in anyone’s book and is severely under the curve for expected increases from the company. The gap between Skylake-SP and Cascade Lake-SP is about the gap between Sky-SP and AMD’s current ‘Naples’ based Epyc CPU which are a fraction of the price.
Later this quarter AMD will release their ‘Rome’ based Epycs which the company has stated will double performance per socket over Naples. The same set of numbers which correctly called Cascade’s performance had Rome beating Cascade by 50%+. We can now reveal that those numbers had Rome coming in at ‘only’ a little more than 190% of Naples’ performance. The make or break thing for Cascade Lake is where AMD prices Rome, the rest is rounding error.
So on that foreboding note we come to the end of this piece about Intel’s new Cascade Lake family of CPUs. Depending on how you view the new features listed it is either a mild tweak or a handful of solid feature advances, the final call is yours. What is unquestionable is that Cascade Lake-SP is better in every way than Skylake-SP so unlike the Broadwell/Sky battle, there is no reason to stick with the older model. At worst you get a hair more performance for the same money with far fewer security patches to worry about, at best you get a decent bump in speed and cores for the same price. Cascade won’t change the world but how Intel wields it in a fight remains to be seen. It will be an interesting year on the server front.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Microsoft Throws Qualcomm Under The Bus Too - May 10, 2024
- Microsoft Absolutely Screws Intel and AMD Over AI PCs - May 8, 2024
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024