 Today AMD is teasing their Ryzen 5000 line of CPUs which should beat Intel at everything all the time. SemiAccurate is exaggerating a bit but realistically at this point there are only corner cases where Intel has a chance of a slim victory.
Today AMD is teasing their Ryzen 5000 line of CPUs which should beat Intel at everything all the time. SemiAccurate is exaggerating a bit but realistically at this point there are only corner cases where Intel has a chance of a slim victory.
Lets start out with the bad, AMD is once again snatching defeat from the jaws of victory by half-announcing a new line of chips with enough headline spoilers to make the actual launch barely worth covering. It isn’t as bad as Intel’s Tiger Lake debacle from a few weeks ago but it is an unnecessary self inflicted wound for the third time in a row. Coupled with less than a day to cover the news and you get low level regurgitation of the shiny bits with no time to do the right thing on a product that would be much better showcased that way. Sorry to our readers, this idiocy isn’t our fault.
Now back to the good news, AMD is launching four Ryzen 5000 series parts today with availability in November 5th. They are the Ryzen 5 5600X, 7 5700X, 9 5900X, and 9 5950X with 6, 8, 12, and 16 cores respectively. While the specs for three SKUs are below, the biggest news is that the Zen 3 core has a claimed 19% IPC uplift over the already front-running Zen 2 core in the Ryzen 3000 line. Do remember this is only architectural uplift, process gains come on top of this.

3/4 of the Ryzen 5000 line
The 5950X is obviously not on the slide above but it runs at 3.4/4.9GHz base/turbo, 105W TDP, and costs a mere $799. L3 cache is 64MB, we will ignore AMD’s misleading 72GB number that adds L2 + L3 for a bigger number, stop this silliness people, really, you are better than that. Similarly we will not parrot back AMD’s performance numbers because they refuse to properly disclose their testing specifications once again, Intel may quasi-legally bury theirs but at least the information is actually available. Usually. Once again, do the right thing AMD, there is no reason not to.

AMD Zen 3 CCD layout
On the technical front, the big bang is that the two 4C CCX arrangement on each CCD in Zen 2 is now banished and all 8C per die are one logical unit. Better yet the two slices of 16MB L3 are now one large 32MB L3 which should result in a significant uplift for cache friendly workloads. This will also pay huge dividends in the upcoming Milan server CPU, it will be more effective there.
What is more interesting is that one of the few ‘glass jaws’ of the Ryzen 3000/Epyc 7002 devices was cache and memory latency. It wasn’t a huge problem, the CPUs were ahead of Intel at almost everything but the blue team did win on merit in several real world benchmarks. Having to go off-chip and then back on chip to talk to a neighbor meant four hops, not exactly ideal for a cache snoop for instance. On top of the latency hit you have lots of traffic on each of those die to die links which costs power and if loaded, can add even more latency. That is now gone on the one CCD Ryzen 5s specifically the 5600X and 5700X, and cut to a fraction of what it was on the two CCD SKUs. This should result in significant performance gains for the new Ryzens.
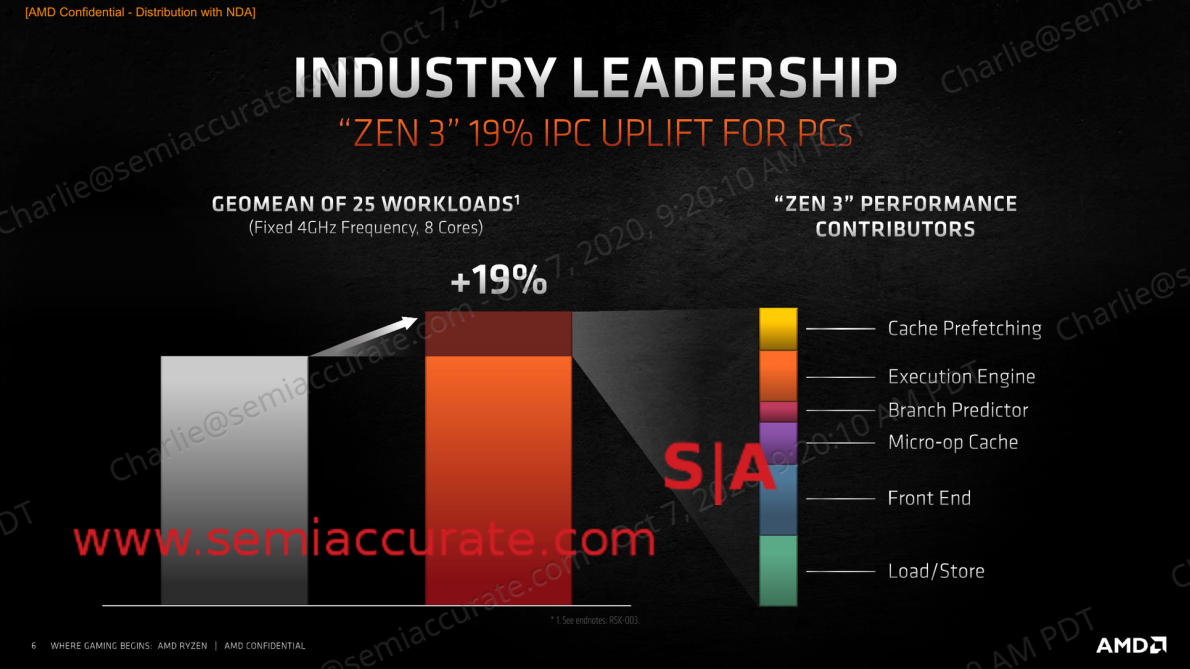
AMD Zen 3 IPC improvements
As you can see from the numbers above, the gains in IPC are across the board, a little here and a little there. This incremental advance is the new normal for CPU generations but the magnitude of it is larger than many expected. Before you point out that Intel’s solid Ice Lake core got an 18% rise, do recall that that number compares to the two generation older 14nm cores, if Cannon Lake was included that number would not be nearly so impressive. To put it another way, in just over a year, AMD’s IPC gains beat out Intel’s 2015-2020 IPC advances. They are giddy for a reason.
Moving on to the process that the Ryzen 5000 is fabbed on, things get a little muddy. They are fabbed on TSMC’s 7nm process but not the same 7nm process as the 3000 chips. They are also not built on an EUV process which was called 7+ but may now have been renamed 6nm since TSMC is also talking about another 7+ which is not the same as the EUV 7+ of old, nor is it the same as the one AMD’s uses for R5K. Confused? Take it up with TSMC, we don’t like it either.
Once you add process improvements in to the 19% IPC increase you get a 24% uplift when moving from an R3K chip to an R5K chip. This is a drop in replacement on the same motherboard, you just need AGESA 10.8.0 or higher to boot, already in the market for 500-series chipsets, 11.0.0 on November 5 for the full experience. 400-series boards will have BIOSes that support R5K trickling out in January but rest assured, they will happen.
That 24% uplift means 5% or so comes from process improvements, less than expected but still welcome. As a whole, AMD is claiming a 20% gain in power efficiency over R3K and a 2.8x lead over Intel’s i9-10900K for the 5900X. This is a devastating advantage for a product priced $20 more than the Intel offering. Speaking of which, for the lower three SKUs, AMD is pricing their parts at the same level (5600X) or higher (5700X and 5900X) as Intel’s equivalents which is quite significant. Intel has nothing to compete against the 5950X and won’t for a long time.
The last big point is one of the most interesting, up until now we have been talking about the gains from the cores and caches, all of which are contained on the CCD die(s). They are connected to the I/O Die (IOD) which has memory controllers, PCIe, and the rest of the uncore. This IOD is the same as the one in the R3K line, and by the same we mean no changes, 12nm, same features, same everything. If you recall the old talk about Rome Phase 1 and Rome Phase 2, you have a pretty good insight as to what Milan is going to be. This is the financial and time to market advantages of chiplets, and AMD is using it very effectively.
So in the end what do we have? A massive performance gain for AMD in an area where they were leading in the majority of benchmarks already. Intel had a little lead in a few places mainly due to the glass jaws of R3K but those appear to have been eradicated. AMD should win at everything now and Intel has no response but we won’t parrot back AMD’s numbers because they don’t properly document their testing systems. We would also love to tell you more about the tech but AMD’s noxious disclosure timelines and strategy preclude that too. What should have been a day to go in depth about the new top end chip on the market once again becomes an exercise in needless annoyance. Please stop.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024