![]() Meta is announcing their new AITemplate framework for GPUs. If the numbers are correct, and SemiAccurate believes they are, this could change the balance of power in the GPU world.
Meta is announcing their new AITemplate framework for GPUs. If the numbers are correct, and SemiAccurate believes they are, this could change the balance of power in the GPU world.
AITemplate (AIT) is a two part Python framework for AI models that transforms them into much faster C++ code. It has a front end that optimizes models through graph transformations and optimizations. That is then spat out to the back end which converts the model into straight C++ GPU code. As most of you will realize, C++ is a whole lot faster than interpreted languages, usually, and AIT is no different. How much faster you ask?
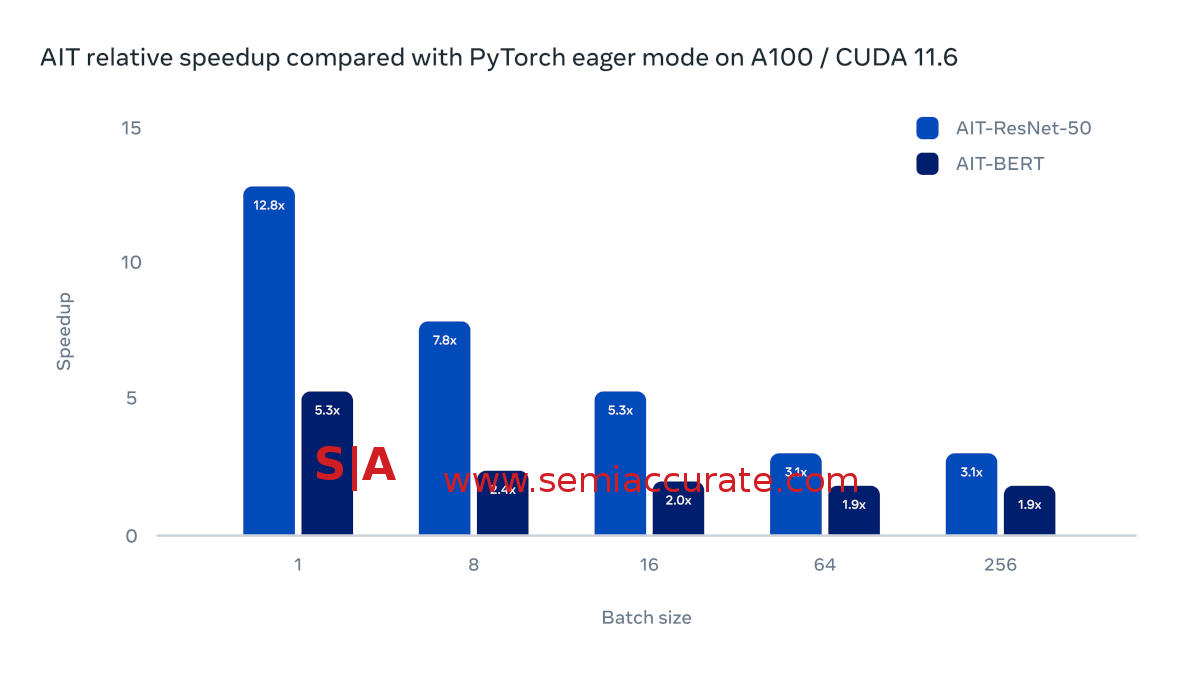
Nvidia A100 performance with AIT
Running BERT and ResNet-50 on Nvidia A100 hardware with Cuda 11.6, Meta AIT delivers between a 3-12x speedup in ResNet-50 and a 2-5x speedup on BERT. Given the larger batch sizes have lower speedups, SemiAccurate thinks the lower performance bound is the much more achievable figure in the real world but double the performance is still a major gain. If you think about it, this potentially cuts Meta’s investments in GPU systems in half, not to mention power and cooling costs.
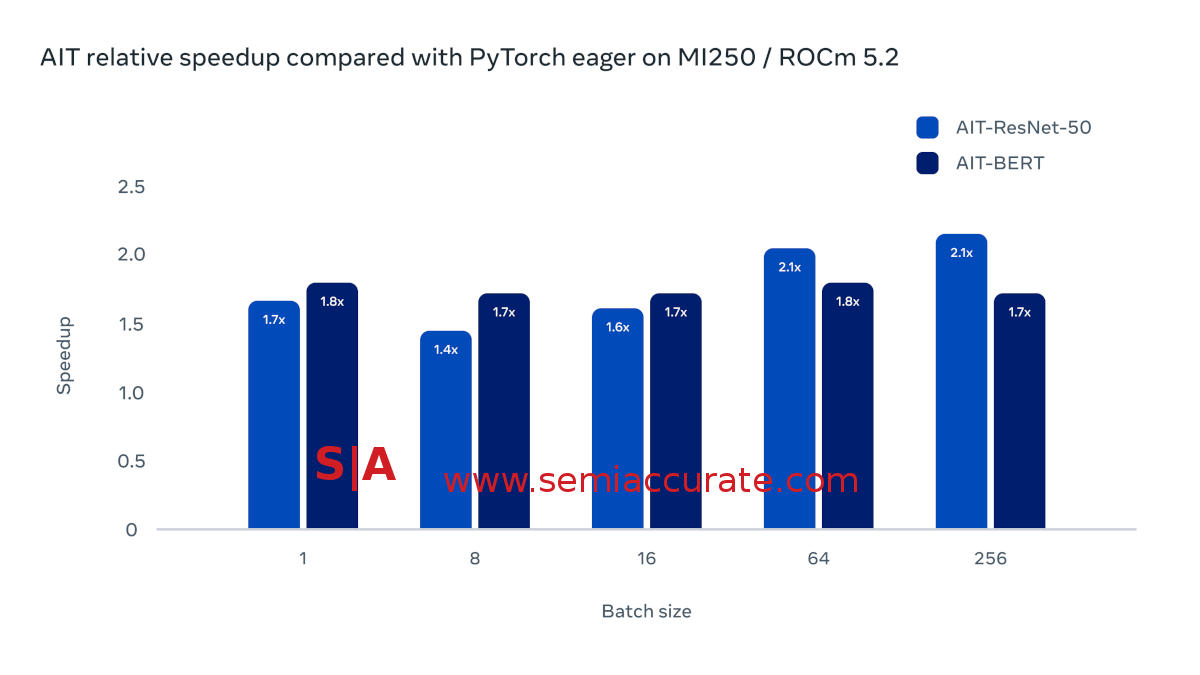
AMD MI250 performance with AIT
On the AMD side the picture is a lot less rosy, sort of. Using ROCm 5.2 and MI250 accelerators, the speedups are in the 1.5-2x range for both ResNet-50 and BERT. More interestingly the performance uplift is pretty consistent regardless of batch size, something that is a bit counter-intuitive. In any case a 1.5x uplift is nothing to be overlooked, especially when you buy hardware in the quantities Meta does.
Both of these numbers are relative to the performance of the same cards with native frameworks, a good thing but one that does little to influence purchasing decisions. What really matters is how the cards do against each other on the same workloads. Luckily Meta included that data too.
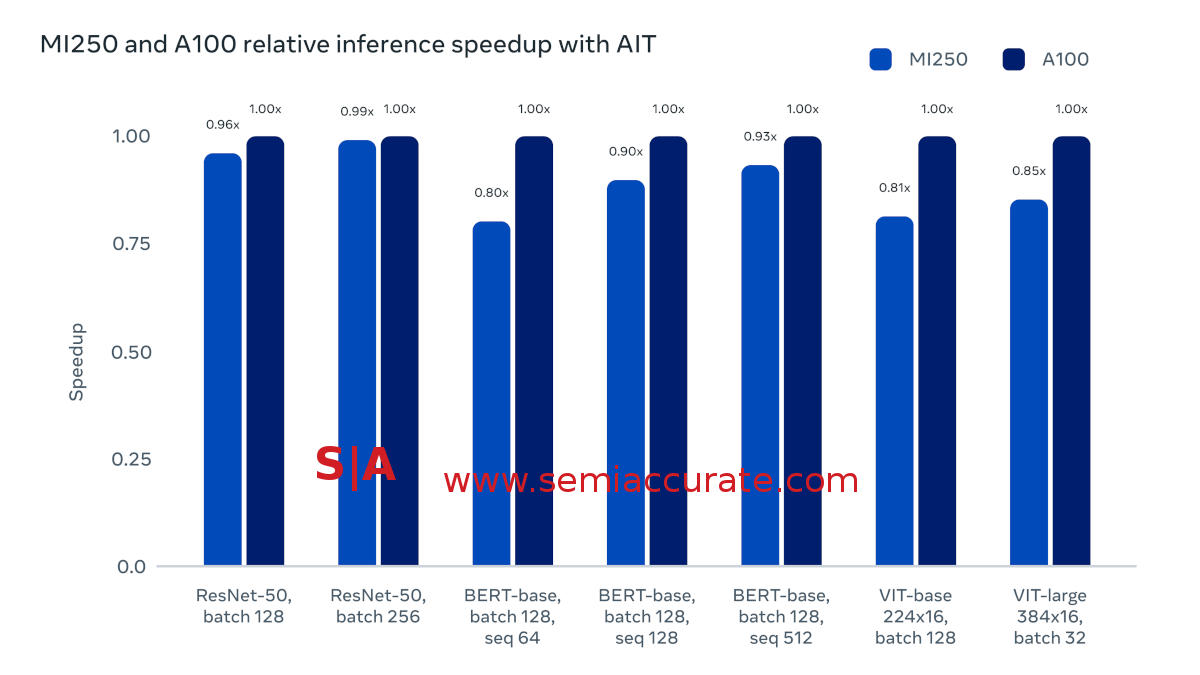
AMD vs Nvidia AIT performance
As you can see, Nvidia’s A100 is still a bit ahead, call it 10% give or take a little, of AMD’s MI250 cards. On ResNet-50 the two are tied, BERT sees Nvidia lead by 15% or so, and VIT has Nvidia extend it’s lead to nearly 20%. Unfortunately there are almost no MSRPs for this class of GPU so it is hard to compare values directly. Anecdotally however, AMD is said to be willing to deal and Nvidia isn’t so this performance delta is probably reversed in the real world when it comes to TCO.
That brings up the next point, real world performance. Showing benchmarks, ones that are heavily optimized for as well, is one thing, heavy workloads are another. Once again Meta provided a useful bit of data to help us out. On BERT-base long sequence (4096) tests, the results show an interesting picture.
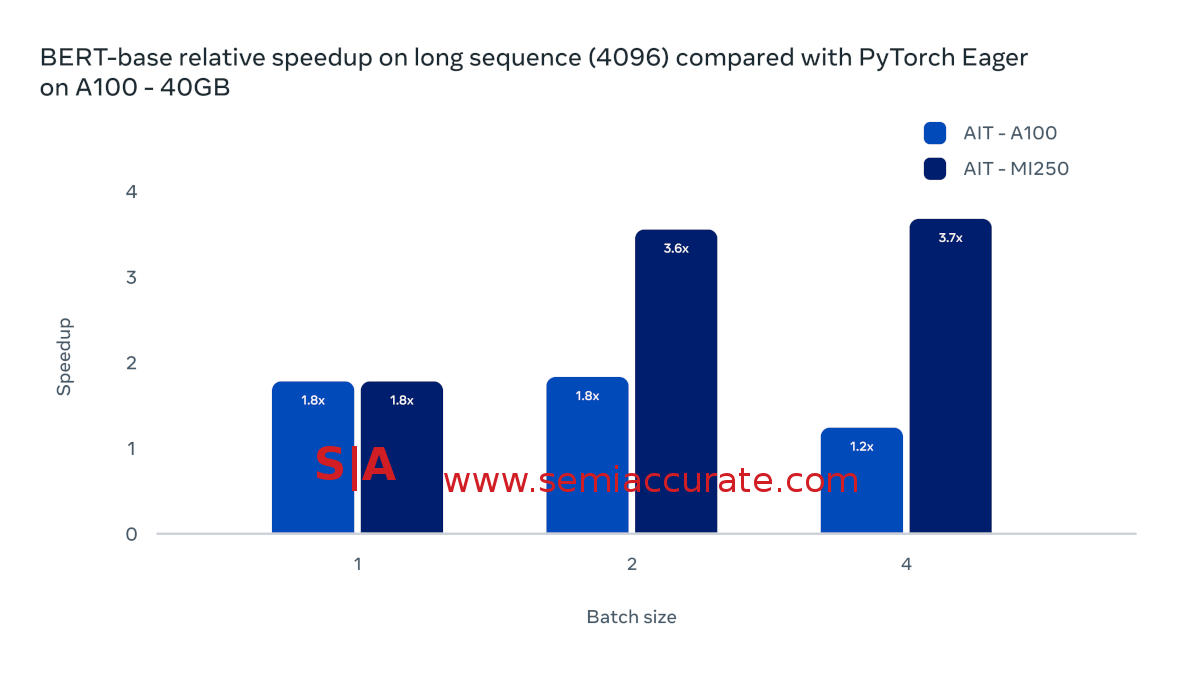
AMD MI250 performance with AIT on large data
Sure it is only a single framework and Nvidia’s A100 sees a financially significant speedup, but AMD’s MI250 gets quite a bit more. At a batch size of one, both cards are 80% faster with AIT than their native frameworks, that is good. As batch size grows, Nvidia’s performance drops off and AMD’s grows. AMD’s MI250 ends up at 2-3x the performance of Nvidia’s A100 on AIT running BERT in this configuration. If you think about that in dollar terms, it is a pretty stunning number when applied to the hyperscaler set.
We are saving the best part for last, Meta is fully opening up AITemplate code, you can download it here. It is meant to be easy to use, self-contained, and very fast. From the looks of things it achieves those goals quite nicely. For the bits that don’t do what a user wants, the code is open and free under the Apache 2.0 license so you can hack away at your leisure.
While SemiAccurate is hesitant to say this is a game changer, mainly because we don’t live in the AI world enough to understand the subtle nuances, the top line numbers are quite significant. If they apply to the general case as they appear to do, this could have profound implications for Nvidia’s sales and the balance of power in the GPU world. Somehow this doesn’t seem like an accidental effect.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024