![]() AMD is finally talking about HBM today, and SemiAccurate thinks there is a lot of good in the details. Actually High Bandwidth Memory has a lot of good in the overall picture too so lets take a long look at both.
AMD is finally talking about HBM today, and SemiAccurate thinks there is a lot of good in the details. Actually High Bandwidth Memory has a lot of good in the overall picture too so lets take a long look at both.
To start out with, HBM is a long time in coming, partly for technical reasons, partly for non-technical ones. AMD claims to have started work on HBM over seven years ago, a number SemiAccurate doesn’t doubt at all. Why? We exclusively published the below picture of an AMD GPU with four HBM stacks on an interposer in 2011. Yes there were working prototypes quite a bit before then.

An oldie but a goodie about to break cover
This HBM memory was supposed to be part of a 2012 GPU called Tiran which SemiAccurate told you about in early 2012 and showed you the roadmap with the details a bit later. Before all the conspiracy theorists run wild, the reason for this cancellation were non-technical, by the 2012 launch date our understanding is that all the bugs for production had been worked out. AMD has been sitting on HBM and interposers for quite a while and we will finally see it on Fiji like we exclusively told you last August at the tail end of the schedules we also told you about last year.
But enough of that product based history lesson, AMD went out of their way today to not talk about products, just the HBM tech that will show up in a near future but unnamed product. That being the case we won’t talk about products so if you see us talking about a hypothetical future GPU with four 1GB HBM stacks for no reason, it is not about Fiji. Oops, sorry, not about an unnamed future product at all, and we just picked four stacks for no reason. A better BS excuse is that we picked it because the picture above has four stacks, yeah, that’s it, maybe readers will buy that one!
HBM is in some ways a vastly more complex device than anything that came before it, a stack of DRAMS with TSVs vertically stacked on a logic die. This logic die is placed on an interposer along with a few other stacks and a device which uses said memory. In this case we will assume the device is a GPU because we are very confident that is the first device you will see bearing HBM memory. The stack looks like this.
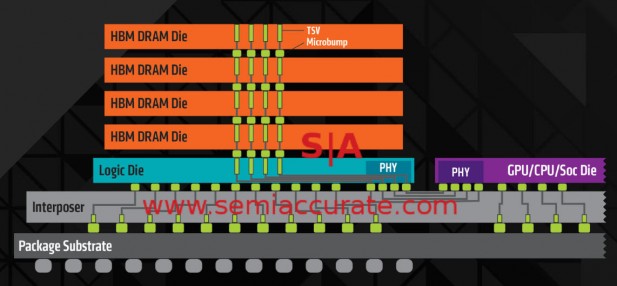
HBM stack diagram
The first interesting bit is that HBMs are massively wide, 1024 bits each so a hypothetical GPU bearing four stacks would have a 4096b wide memory bus. High end current devices tend to have a 384b or 512b wide GDDR5 bus with each GDDR5 device being 32b wide. To make up for this disparity GDDR5 runs at a very high-speed, up to 7Gbps vs 1Gbps for HBM. In short for a given width, GDDR5 is ~7x faster than HBM, so why use HBM? Power, memory cost, power, implementation cost, power, board cost, power, and the fact that you probably couldn’t actually make a single device with a 1024b wide GDDR5 interface for anything approaching a sane cost. Why? Lots of reasons. A 4096 bit wide GDDR5 device is borderline fantasy.
If you look at the diagram above you will notice two types of bumps and two types of traces. The bumps between the logic die and the interposer are significantly smaller than the bumps between the interposer and the package substrate. It is badly illustrated in this picture but the traces are also very different, the logic die <-> package substrate and GPU <-> package substrate traces are actually TSVs, they go through the interposer in a straight line.
The traces on the interposer that go between the logic die and the GPU die are not TSVs nor do they go through the interposer, they are traces printed on the interposer’s surface. For those of you not aware, the interposer is a piece of silicon background to a very thin sliver of silicon 100µ or so thick, something we went into detail about yesterday.
You can have either active or passive interposers, active have logic/transistors on them, passive have only metal layers. This is the long way of saying an active interposer is a very simple and large chip, a passive one skips the transistors and only prints metal layers aka wires. This again translates into active being fairly expensive and passive being very cheap. You can print as many metal layers as you want on an interposer but each layer dramatically ups the cost.
AMD went for passive interposers and did not say how many metal layers they used but SemiAccurate speculates they didn’t go above three if they even hit that many. They are made at UMC on an undisclosed process that was strongly hinted to be either a 40nm or 65nm process. In short it is on a very old and inexpensive process and has a very small number of steps at that. Interposers are dirt cheap per mm^2 of area compared to chips built on the same outdated process.
Since they can have features on the same scale as the logic they are connected to, the bumps they need to connect to the logic dies can be much smaller than those connecting to the PCBs. Better yet since an interposer is silicon it will have the same thermal expansion rate as the logic dies. PCBs like the package substrate obviously has a very different thermal expansion rate. This means you can make tiny bumps on the top of the interposer and not worry about hilarious thermal whoopsies like this one.
The bumps on the interposer to package interface need to be much larger for the same reason as before, they can be basically the same as those in use for just about every chip in the world today. Please keep in mind that both of these are significantly smaller than the ones found on the bottom of the package substrate that will be mounted to the card or motherboard itself which are yet again much larger.
The bump pitch on a HBM is 55µ and we will assume the GPU and top of the interposer are the same. Logic die to package substrate bumps tend to be about 3x as side center to center meaning about 9x less bump density on the bottom of the interposer, lets call it an order of magnitude. Package substrate to board bumps tend to be closer to 1mm ball pitches than you might expect, but lets again call it roughly an order of magnitude difference even though it is likely more.
With that in mind if you could put a hypothetical 10 bumps/mm^2 on the bottom of the package, on the top you could have 100/mm^2, and then 1000/mm^2 on the interposer to logic interface. This disparity allows you to do things that were previously impossible due to being pin/pad bound, interposers can make that limit vanish or at least become a non-issue for the next few years. If your old package had 1000 pinouts, interposers could make this a hypothetical 10,000. This all said we have no idea what bump density or pin counts AMD is using in that unnamed but near future product.
What this means is that AMD and the rest of the industry had their memory interfaces effectively limited by the number of bumps you could put on the bottom of the die. Bigger dies meant more bumps which meant wider memory interfaces. This all consumed much more power too, but we will ignore power for the time being.
Even if you could get enough bumps for a wider interface on the bottom of the die, you had another problem, getting signals to them. This is a really hard problem for many reasons, the simplest is how to you physically lay out thousands and thousands of traces that end up in the roughly 20*20mm area that is the bottom of a big GPU. Should you be able to, you also have to worry about signal integrity, timing, cross-talk, and all the rest of the headaches you may never have heard of before.
Modern package substrates have grown into a complex beast with at times 10+ layers just to route the signals of a 384b or 512b memory interface, and now AMD is (not yet) talking about going to 4096b? Doing this the old way, again power aside, would simply not be possible, you couldn’t put enough bumps down or physically make a complex enough package to do it all. Actually IBM got part of the way there with some of their Power CPUs, but they used an ~80 layer glass package but the result sold for roughly what many people pay for a car. Technically speaking getting a bit closer to a 4096b memory interfaces could be possible but not for anything in the consumer market.
Interposers change that, they up not only the bump density but also massively lower the width of the wires to them. On a PCB you can often see the traces with your eyes, on an interposer they can be on the order of tens of nm. Better yet you can do all sorts of tricks routing them if you want to pay for more metal layers on the interposer, but given the density disparity, you can get away with far fewer layers. The interposer may not be cheaper than a complex package but the disparity is not as great as you might think and you can do things that were previously not possible. With an interposer, you can do a 4096b memory interface on a product that a consumer can afford.
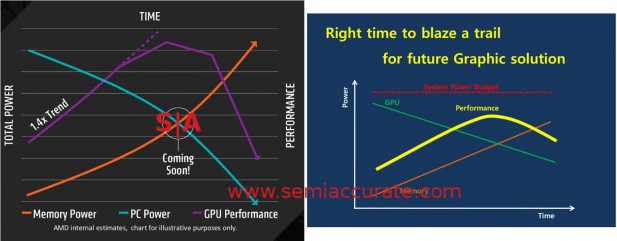
AMD 2015 vs Hynix 2011
That is one major hurdle aside, you can actually make a die with enough bumps and route them out in a sane way with interposers. That brings us to power, if you look at the above graph AMD presented to us, or the one AMD and Hynix showed in 2011 beside it, you can see the problem. Memory power is going up very quickly, high-speed signals are a real power hog, off die, through package, through card, and back onto a memory die high-speed signals become borderline silly as the graph shows. And it is getting worse.
In order to feed the beast that modern GPUs have become, you need as much more bandwidth as you can possibly engineer into the solution. GDDR5 helped a lot and bought us several years but going faster was going to be problematic. In 2011 Hynix said there were three paths forward from GDDR5, single ended GDDR5, differential GDDR5, or HBM. Single ended GDDR5 raised the bar from 7Gbps to 8Gbps at roughly the same power levels and differential went to 14Gbps. Unfortunately that used much more power to do so and, worse yet, it probably doubled the pin count so it was effectively the same as vanilla GDDR5 on a per-pin basis. Neither were good ways forward.
HBM on the other hand is massively wider so bandwidth problems are potentially solved, going from 32b wide devices to 1024b devices alone ups bandwidth by 32x. Unfortunately it also means something close to 32x the power consumed and, well, an inability to sanely scale memory capacity. More on that last bit later but the power problem can be solved in much the same way it is in the GPU itself, by parallelization.
If you overclock a chip it tends to draw power more than linearly to the increase in clock speeds. If you underclock it, to a point, the same is true but like everything else you hit diminishing returns soon enough. There is usually a sweet spot for every design that maximizes performance per Watt, and you can design devices to put that point more or less where you want it.
CPUs traditionally have a small number of cores clocked high for the maximum single threaded performance because that is what their workloads require. GPUs are just the opposite, their workloads are usually trivially parallelizable so they don’t need peak performance per shader/core, more can do the same job. GPUs can use many small units with clocks usually tunning at a fraction of where CPUs play at.
Simplified a lot, GPU shaders are pushed as far as they can go efficiently and then more performance is gained by putting many of them down. You could make a 1000+ core CPU and it would be painful to use and net slower in the real world for most use cases even though it is notably higher performance on paper. You could also make a 4-core massively out of order superscalar GPU that clocks at 4GHz and if it didn’t melt the silicon it was printed on, it would be painfully slow at games. There is a reason that neither path is seen in devices in the mainstream market.
This is the tradeoff that AMD and Hynix made with HBM in a way, instead of designing a fast and (relatively) narrow memory interface, they designed a wide and slow interface, trading per-pin performance for more pins. Looked at this way you might have asked why such a brilliant scheme wasn’t done before on memory interfaces but since you likely have read the bit about interposers and pins/bumps, you likely know the answer. If you just started reading at this paragraph for some reason, this is the Internet and odder things are fairly common, it is because you really couldn’t make it before interposers.
So the HBM stack ends up trading speed for width, it runs at a 500MHz clock, two bits per clock and 1024b width vs 1750MHz and four bits per clock and 32b wide for GDDR5. The end result is 7Gbps per bit or 28GBps per chip for GDDR5, 1Gbps per bit or 128GBps per stack for HBM, quite the massive difference on a device level. If you are going to make a GPU with a massive and expensive 512b GDDR5 interface however, that means you will need at least 16 GDDR5 chips and that puts the net bandwidth up to 448GBps for the GPU. Four HBM stacks will add up to 512GBps in total, not a massive amount higher than the ‘old way’, so why bother?
First up is power, you save quite a bit by running the HBM slow and wide, AMD claims about a 3.5x increase in performance per watt, specifically 10.66GBps/W for GDDR5, 35+GBps/W for HBM. Hynix claims a HBM is 42% more efficient than GDDR5 when measuring mW/Gbps/pin, a different metric but still very useful. In short for the same net bandwidth, HBM should use something in the ballpark of 1/3 the power of GDDR5. Hynix calls the power draw of HBM about 3.3W/128GBps or what one stack can push which compares well to the roughly 2W per high-end GDDR5 device. (Note: You obviously need 4-5 of those devices to equal the same bandwidth, and that 2W number is not from Hynix)
That brings us to capacity, something that traditionally has not been a big problem for GPUs. Higher end GPUs tend to need more memory and since capacity per die tends to be relatively fixed on each generation, you get more by going wider. Since higher end GPUs also tend to need more bandwidth, when you scale one with GDDR5, you scale the other. If you want even more you can use clamshell mode on GDDR5 to double the chip count and therefore capacity at the same bandwidth and pin count. In the current generation, HBM gets you 1GB stack, the end.
That means if you want to make a high-end modern GPU with at least 4GB on the card, you need four stacks even if you don’t need all the bandwidth. If you want to go to 8GB HBM graphics cards, sorry. That said a four stack GPU should have more than enough bandwidth and capacity to satisfy any modern game at 4K resolutions, by the time the second gen HBM GPUs come out, HBM will be on their second gen with 2-8GB per stack plus double the bandwidth. All the game devs SemiAccurate asked were pretty cynical about the abilities of those claiming to need more than 4GB cards. They also phrased their answers in far more eloquently using polite but scathing terms too.
In a nutshell, if you count the costs of the interposer, HBM is probably a bit more expensive than GDDR5 for approximately the same bandwidth, 448GBps vs 512GBps. That isn’t good. It also consumes about a third the power of GDDR5, that is good, very good but not a game changer in the world of 200-300W graphics cards. If this is true, why go with HBM now?
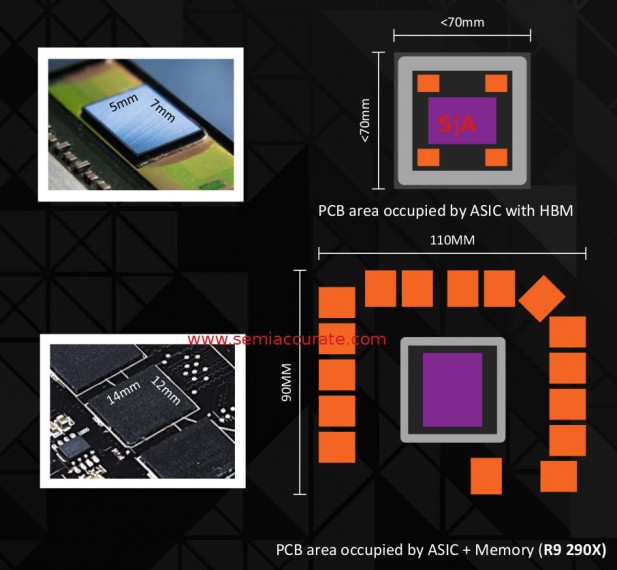
Board area comparison for memory
If you step out a bit from the GPU die itself, you will notice that the board area used by the GPU and memory is pretty large. AMD claims that 1GB of GDDR5 or four chips takes up takes up about 672mm^2, 1GB of HBM takes only 35mm^2. If you scale that out and take into account real world things like routing and chip placement, a 4GB (16 GDDR5 die) R9 290X needs ~9900mm^2 for GPU and memory, a 4GB (4 HBM stack) device only needs about half that. This means you can make a much smaller GPU card.
Why is this important? PCBs cost money, the smaller you can make them the less they cost. More interestingly and not mentioned by AMD is that a modern GPU’s pins are dominated by two classes of use, power/ground and memory. Power and ground are going to stay roughly the same because any power saved by HBM on a high-end part will go into higher clocks. Memory on the other hand stays on the top of the interposer in the metal layers, you don’t need to even route it to the package substrate much less onto the card PCB itself.
There goes a large percentage of your GPU package pins right there, and better yet they are the really touchy high-speed memory signals. Poof, gone. What do you think that does to the package layer count and therefore package complexity and cost? Serious savings there not to mention device design time. Since those same signals don’t need to be routed through the PCB either, it’s layer count can drop by a big number there too. Instead of 8-12 layer GPU cards you may see half that with the not-officially-Fiji-yet generation. That saves money too but both together are unlikely to fully defray the cost of the interposer on this generation.
That means the next generation of GPUs with HBM could not only be much smaller physically, everything other than the GPU+memory package can be much simpler and cheaper. Since you more or less only need to route PCIe in and video signals out, everything gets smaller, cheaper, and simpler. This is a win/win/win for almost everyone, and once volume comes up, it won’t cost any more than the ‘old way’.
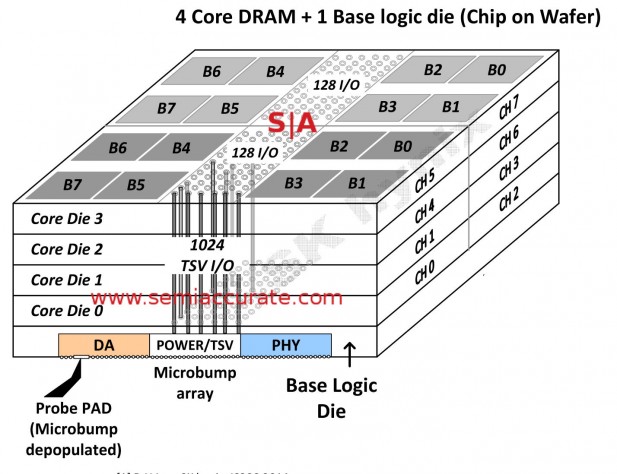
The stack itself in a bit more details
So with those macro details out of the way, lets look at some of the really interesting lower level bits. First is that the current HBM stack is comprised of four DRAMs on top of a three-part logic layer, Direct Access (DA) for testing, a middle power and TSV strip, and a PHY strip on the edge. All signals are routed through TSVs only vertically, there is essentially no horizontal movement of data other than to the cells themselves. This saves power and of course lowers latency.
Similarly with the PHY being along one edge you can place it right up against the logic/GPU device that it feeds keeping the data paths short and lowering power too. It also saves on interposer complexity a bit, you only need to route most signals a short distance and in a straight line. Hopefully. But it never works out that way in practice for some reason even though the theory is nice enough. Less theoretically there is a lot of both vertical and horizontal redundancy built into the HBM and interposer so yield and assembly losses should not be bad.
One of the reason that power is so low is because HBM doesn’t need termination, everything is point to point and low power. Lower frequencies mean far fewer tricks are needed to transfer a bit, and if you know anything about GDDR5 you know how many tricks are needed to get make it work well vs just work. Go back and look at the memory clocks, power, and efficiency of the first Nvidia GDDR5 implementations vs a contemporary AMD one for the importance of those tricks. You have to spend a lot of area to achieve that.
For that reason AMD is claiming that the memory controller and PHYs for a HBM based GPU are significantly smaller than those of a GDDR5 based GPU on the same process even considering the width increase. Unfortunately since they weren’t talking about product they would not comment on how much but we hear tens of percent. So even with a 4096b memory interface, HBM ends up using less precious and expensive die area than GDDR5. This again defrays a bit of interposer cost.
For the hardcore out there, HBM uses source synchronous clocking and doesn’t need the high power devices that pushing a GDDR5 signal off die required. If you know how big those drive transistors are, and how many you would need for a very wide GDDR5 interface, you can see where a bunch of the savings comes from. That is just the tip of the iceberg too, go look up the complexity of the GDDR5 protocol and think about what is not needed anymore.
Lastly is an interesting bit, the logic layer on the HBM itself. This is not something AMD makes, Hynix does the whole stack as a single device but we will talk about it anyway. This logic is made on a memory process, traditionally bad for transistor efficiency. Since it is a separate die with effectively no memory on board, it can be heavily tweaked for transistor performance and efficiency without the traditional costs or tradeoffs of doing it on a single die.
Since it is part of the memory device itself, the logic layer only really needs to run at frequencies close to the memory and therefore ones amenable to the process. Any added performance is gained from width, not clocks. That said the current generation of HBM is capable of running at twice the clock rate that AMD is using for its upcoming mystery product so headroom abounds even if raw capacity doesn’t.
In the end you have a large number of tradeoffs with HBM. It is wider, slower, less power-hungry, and more expensive than GDDR5. It is also quite limited in capacity but what AMD can do with four stacks is more than good enough for the time being. Those tradeoffs mean a smaller GPU die, a less costly and complex package, smaller, simpler, and cheaper boards, and many more savings. The Interposer on an HBM solution will end up being more expensive than the ‘old way’ but not by as much as a 1:1 comparison of memory costs would initially seem.
From here the future looks bright. This first generation HBM product is already ahead of a painfully expensive 512b wide GDDR5 solution and that lead can be doubled with ease. Capacity is a limiting factor right now but not a serious one for consumer uses, 8GB cards are really vanity items at the moment. By the time these few constraints become real limits, HBM2 will be here with 2x the bandwidth and up to 8x the capacity of current HBM devices. This train starts rolling soon even if AMD won’t say exactly when. Fiji, ha, said it again.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024