![]() LSI is talking about two new technologies in their Sandforce controllers that deal with space and error correction. One is really simple to explain while the other is a whole lot more complex in implementation and description.
LSI is talking about two new technologies in their Sandforce controllers that deal with space and error correction. One is really simple to explain while the other is a whole lot more complex in implementation and description.
The complex technology is an error correction scheme that LSI calls Shield. This is a five layer software LDPC (Low Density Parity Check) scheme among other related error correction, detection, and mitigation technologies that they claim can both prevent many errors and extend the life of low write lifetime flash quite a bit. Shield fits between the hardware wire speed but fixed LDPC implementations aka Hard LDPC or HLDPC and Raise, the LSI RAID-like scheme for flash chips. It all looks like this.
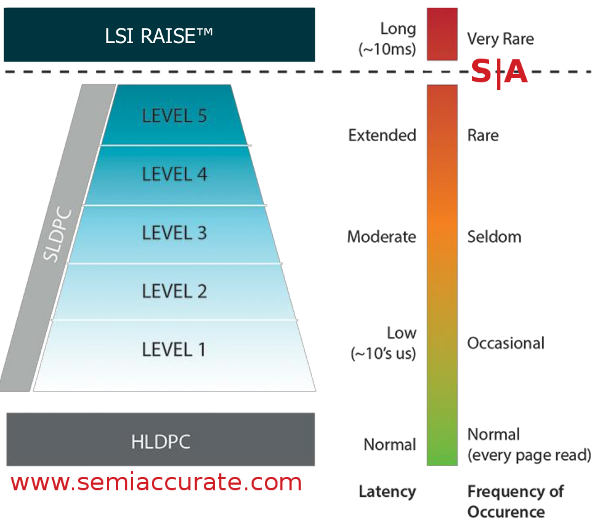
The pyramid of ever-increasing software LDPC
HLDPC is an always-on mechanism that is limited in what it can do but adds almost no latency. You also pay for the speed with flexibility, you can’t update the algorithm on die. If HLDPC catches an error and can correct it, that is where this path ends. If it can’t correct the issue then Shield steps in. As you can see above, when you climb the pyramid each level adds more latency from zero on HLDPC to 10ms for Raise. For those not versed in SSD minutia, slowing things down is not appreciated by the user in most tested scenarios. The same studies also show most users like puppies so it must be scientifically valid, we wouldn’t make this stuff up just for your amusement.
Shield differs from most Software LDPC (SLDPC) implementations in a few ways. First LSI was able to do more than the usual with software schemes because they were smart enough to hold onto the metadata from the first read in a cache. This allows them to avoid the rather large reread penalty from reloading whatever data the SLDPC needs to work with, that takes ages in SSD time frames. Second the Sandforce controller has the ability to use some of the analog data from the cell reads to run through DSP-esque algorithms that can do things digital parity and ECC simply can not.
Unfortunately the Sandforce guys would not go in to any detail about how this all works, they only said that the space for caching is extremely limited so it is judiciously used. Given the level of secret sauce in things like cache control, prefetching, and ECC this is understandable but still frustrating. In any case the end result is that the data for Shield is in theory already there if the HDLPC fails to work. From there how things are done, if the levels work in parallel, and all the other interesting details fell under the no-comment category.
From the user perspective it just looks like a drive is working right even if it is having problems. If Sandforce did their job right the user should never see any of these problems, the data should just be there and come back with consistent latencies. As the drive ages and the flash wears out, things may get progressively slower but that is normal SSD wear behavior. Other than simple error correction, Shield allows for one nifty additional trick.
This trick is all about the error correction space that all good SSDs have. They are over-provisioned so that errors can be mapped to spare blocks, essentially why you see 120GB SSDs instead of 128GB SSDs. This over-provisioning is used later in life as blocks start to wear and are mapped out, the usable space on the drive doesn’t decrease. If your error correction scheme is fixed a controller has to provision for the worst case scenario, in essence over-provisioning for the early life of the drive to make up for problems in late life.
If you can adapt your error correction schemes so that they are aware of the cumulative error/failure rate, a drive doesn’t need to over-provision at all it can just put aside the bare minimum needed to fix the first problem. Reality of course lies somewhere in the middle but the important thing is that you can use spare capacity for data until you need it for error mitigation. Any guesses as to where this is going?
Most hardcore techs will know that Windows is a bit behind the technological curve when it comes to dealing with drive capacity. (Note: And security, standards, reliability, user antagonism, price, uptake, usability, and this article is too short to list the rest.) The problem is that if you reconfigure a drive’s capacity on the fly, Windows pukes. While this should have been fixed in the mid-1990s, well no comment, you know who wrote that OS. Any other OS however will be fine and given Microsoft’s plummeting marketshare in servers, this looks to be a rapidly diminishing problem. For adult OSes, especially on the server-side, this feature can come in really handy.
Most enterprise class SSDs over-provision a lot more than consumer drives, where a consumer drive may have 10% or less space set aside for later life, enterprise drives may have many times that as spare capacity. Even with 100% spare space, using a large chunk of that won’t make a massive cost difference for enterprise deployments. That is where LSI’s new DuraWrite Virtual Capacity (DVC) comes in to play.
DVC is very interesting because once you allow for variable drive space there are other tricks you can pull. Sandforce controllers have had transparent compression built-in from day one to minimize write duplication and extend drive lifespans. For consumer devices this does little good, MPEGs an JPEGs, not to mention .TAR.GZs are already very well compressed so you gain little if anything on those files. On enterprise data, especially databases, compression/decompression latencies add unacceptable time to lookups so compression is right out. If the drive does this transparently with no added latency, that is another story.
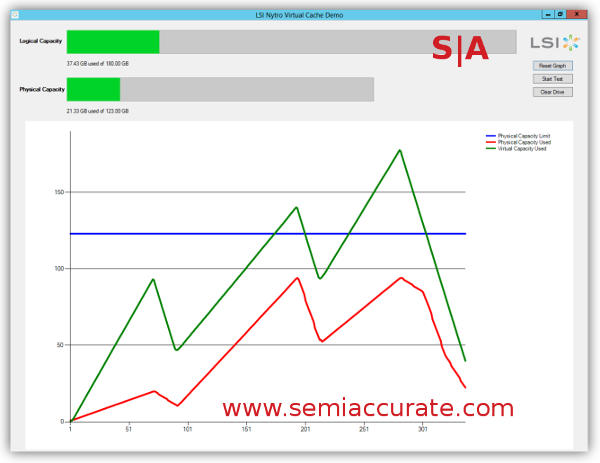
DVC in action on an Oracle database
Sandforce is claiming that DVC can increase available space in some databases by 3x or so, a more than believable number when you look at how sparse most databases are. Many also contain regular structures too so it all adds up to savings. Because it is adaptive you can fire and forget DVC, the normal drive space monitors you have should just work with this new feature. As long as you don’t use Windows that is, then you get the new brightly colored touchable screen of death. For enterprise users, this will very likely make SSDs a much more viable technology to implement, 3x the capacity for the same money is a good step change.
Shield and DVC may seem totally unrelated but one won’t work without the other. Even adaptive error correction is of far less value without the ability to utilize the added capacity it can free up. With the two together it is hard to argue that the usefulness of SSDs is not about to go way up especially on the enterprise side. While neither technology is implemented in the current generation silicon, expect much of it to come with the next controller revision in the near future.S|A
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024