![]() At AMD’s 2022 Financial Analyst Day, the company laid out a lot of future directions and code names. Some of these have been featured on SemiAccurate previously but the big picture they drew was quite interesting.
At AMD’s 2022 Financial Analyst Day, the company laid out a lot of future directions and code names. Some of these have been featured on SemiAccurate previously but the big picture they drew was quite interesting.
Lets take a look at what AMD said at FAD 2022 and try to answer the question of why more than what. There was a blizzard of code names, roadmaps, and processes, some important others less so. The direction AMD is taking however is quite clear, more of the same with better tech, smaller nodes, and more variety.
The big order of the day, it was aimed at financial analysts after all, were the twin acquisitions of Xilinx and Pensando. As SemiAccurate has stated before, we think the Xilinx deal is a really smart one. Yesterday AMD laid out plans for tight integration of Xilinx IP and FPGA blocks into various products, a faster and more granular mix than we had expected. If AMD can pull it off it will be in stark contrast to the way Intel has dealt with subsumed companies. On the Pensando side we are not as optimistic for all the reasons AMD claimed as wins, but that is a topic for a future article. In short Xilinx good, Pensando not so much.
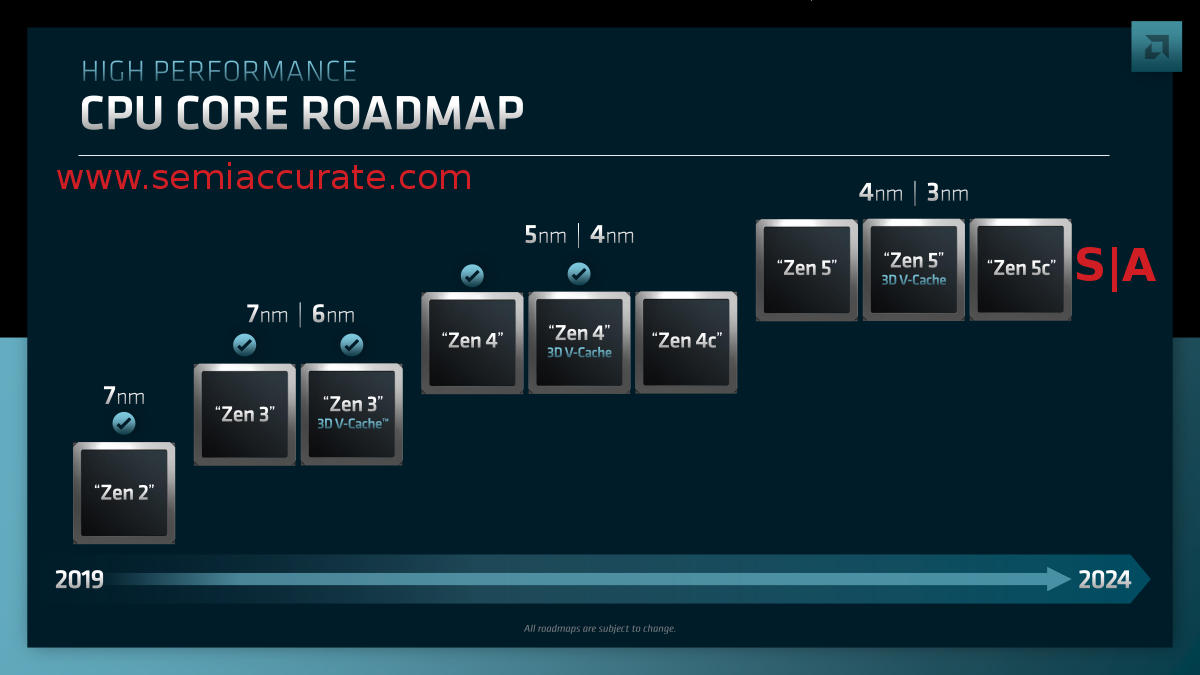
AMD’s current core roadmap
Mark Papermaster was the first to lay out new details with the above roadmap. During the end Q&A there were a lot of questions about what the various process nodes meant above the generational advances. The answer was that with chiplets you will see a mix of processes in each device so don’t read too much into the nodes listed. This is absolutely true but if those numbers encompass the chiplets on a package, the Zen4 family should be listed as 7nm/5nm/4nm because the IOD is 7nm on Genoa.
In short these are the processes the CCDs are likely to be on, but not exclusively bound to, especially if 3rd party IP is involved. The real important bit is how much flexibility AMD’s chiplet/CCD/IOD strategy gives them. By just spinning/modifying a new CCD, AMD can get three full CPU families out of a single IOD. With multiple IODs, AMD can multiply that count to cover consumer, datacenter, and telco as evidenced by the new Siena family. This is something Intel can’t match for the short and mid-term future.
AMD then went on to describe their advantages in power, area, and performance per Watt versus their most direct competition. We won’t repeat those numbers nor will we even agree with them, as we have repeatedly said, we don’t consider AMD to be honest with respect to testing and similar statements. That said some of the things like core area are factual, it is the performance parts we have issues with. Also do note that AMD is not claiming an outright performance lead, only things with modifiers. No points if you figure out why this is.
Then the dribble feed of Zen4 details dribbled on with a few more details. The ‘AI’ features last discussed at Computex were clarified to mean AVX-512 with VNNI but given the mess Intel has made of AVX-512 and it’s patchwork of features implemented or not in a seemingly random fashion, we can’t say for sure what Genoa/Zen4 supports. That said AMD can’t do a worse job than Intel did with Alder Lake, for years they said AVX-512 was a key performance differentiator versus AMD until they removed it for no sane reason. In any case AMD has a strong argument for making whatever version of AVX-512 they implement becoming the standard from here on out. Are the marketers trying to monetize fuses for profit and customer enmity at Intel listening?
One of the most striking data points was the 8-10% IPC increase for Zen4, something confirmed as 8% in Saeid Moshkelani’s presentation. In our analysis of the Computex presentation, SemiAccurate pointed to how weak the AMD numbers seemed. “If you take out at 10% clock uplift that >15% becomes a roughly >5% uplift, so lets say high single digit performance increases for the Zen4 core. This is way below the expected ~20% IPC increase number, not counting clocks.” Many observers scoffed at that analysis, especially those who’s income depends on clicks. They instead pointed to the big numbers in the demos and crowned a new king immediately.
While we think Zen4 beat current Intel offerings, we don’t think AMD’s new products will be anywhere near as performant as they would like you to believe. That is of course the point of PR and demos but it is also a great demonstration of why we say we don’t trust them. Similarly with the performance per Watt claims, vague though they may be. Genoa is a 96c part that needs ~400W versus Milan with 64c at 280W.
Advanced math simulations along with cloud based AI models (we used the Linux calculator app actually…) tells us that Genoa/Zen4 uses ~4.17W/core and Milan/Zen3 pulls 4.375W/core so about 5% better energy use per core. If that 15% or so performance uplift claimed at Computex holds, Genoa looks to be better than Milan for performance per Watt by a high teens percentage. This is nothing to be sneezed at but hardly a killer number. That said it obliterates anything Intel can offer for the datacenter for quite a while.
On the bandwidth front, 125% more per core sounds good, enough to feed 25% more performance. Since Genoa’s performance is unlikely to rise higher than that, AMD seems to be in a good place for memory. If you run the numbers, Milan has eight channels of DDR4/3200 and Genoa 12 channels of DDR5/4800. The 50% core count increase is mirrored by a 50% channel count increase so shouldn’t that 125% bandwidth bump actually be the ratio of DDR speeds, 3200:4800 or 150%? Typo or controller problem? We know AMD has some serious DDR5 issues but this number isn’t evidence in and of itself.

To Infinity (v4) and beyond!
The above slide has a lot to unpack and is far more dramatic than it really needs to be. AMD’s Infinity Architecture (IA) is an evolution of their Hypertransport protocol from the first Opteron era. It is far more advanced now and likely bears little resemblance to it’s forebearers but that is to be expected. One thing few pundits understand is that while it almost exclusively runs over PCIe now, it is completely physical layer agnostic in it’s current guise. More on the topic here if you are inclined to go into the weeds.
That part about enabling 2.5D and 3D chiplets is nothing more than a breathless statement that IA is indeed physical layer agnostic. Completely true but nothing that wasn’t revealed in 2017. The extensions for Xilinx and other IP is nothing more than a spin on the fact that CXL and UCIe will be a standard for such things in the future and AMD supports them. This was again widely known and publicly admitted to over a year ago.
The thorny part is the line on CXL2.0 and memory disaggregation. We covered AMD’s plans on CXL.mem in detail here. There is one big bit you should notice here, this slide is about 4th Gen IA, _NOT_ 4th Gen Zen/Genoa. The platform that supports Genoa will also support Turin and other CPUs, possibly an added generation later on too. They will all use 4th Gen IA and while Turin is slated to support CXL2.0, Genoa is unquestionably not going to. This slide is intentionally misleading in that AMD wants you to think Genoa will do CXL2.0 memory expansion. It will not. It will do a lot of the things CXL2.0 promises as we outlined in the article but while the fabric is ready, the CPU is not, don’t confuse the two issues as they hope you will.
Then there was talk abut 3rd party chiplets as described in the supporting features above. This is nothing new and is absolutely the path the entire industry is on. Intel seems to be way out in front on this wave of devices with their announcements over a year ago, AMD is lagging here. If you look at what Intel has coming in the near future for such devices, it is orders of magnitude more advanced than what AMD has planned. scaling that steep advanced packaging learning curve is hard and matters a lot, interfaces on slides less so.
Next up came David Wang who talked about GPUs. There were two main themes in the preamble, how good AMD’s software really was and how the company is actually in the lead for performance. One of the main reasons SemiAccurate doesn’t trust AMD is that the last time they offered us samples, at the last minute they put handcuffs on us saying that we could only test things with the software they wanted and ONLY the software they wanted. We explained to them how to place the sample in the orifice of our choosing and were promptly cut off. Does this tell you anything about the confidence they have in their software?
Back to the point we are now rapidly approaching the third decade of this author covering AMD/ATI. During that time the yearly refrain was simple, our new software initiative is great and this one is the real production ready version. Do read into that. The last time SemiAccurate checked up on the AMD GPU compute/software stack with people trying to use it in the field, we received diametrically opposing views to the official account. On the performance leadership claims, the same holds true.
On that happy note we come to the technical direction AMD is promising for future GPUs and it foreshadows some seismic changes. Up until now GPUs have been pretty good candidates for staying with monolithic construction. GPUs are large, slow, and can hide immense amounts of latency through execution width. The sheer count of shaders makes them almost defect immune and a few redundant structures means that the small number of dies that don’t make the cut can be sold as the next device down. On top of this, recent market insanity aside, they bring in low revenue per unit silicon area so the costs of advanced packaging bite harder here. If you have been wondering when the crossover to chiplets would occur, David Wang answered that one decisively.

AMD’s consumer GPU roadmap
RDNA3 is the successor to the current RDNA2, who could have imagined that from the name alone? A 50% increase in performance per Watt is promised from this new 5nm chiplet based architecture. One thing that was said in the commentary but not in the slides was that AMD is claiming a much higher clock rate on the new devices. That is an encouraging sign for those who like headlines but high clocks can also do wonders for latency as well. On the down side, some parts of the pipeline are not as amenable to the latency caused by traversing chiplets but we think AMD will be more than prescient enough to avoid such first order pitfalls in RDNA3.
That was followed by a vague roadmap promising 5nm RDNA3 at a time between 2019 and 2024 which is followed by an unspecified process node for RDNA4. If AMD actually delivers RDNA3 this year and RDNA4 in 2023 as intoned but not stated, their woeful lack of new GPU silicon will finally end.
Far more interesting is the promise for CDNA3, the compute variant of the AMD GPU lineup. Until now the main difference between the consumer RDNAx line and the datacenter CDNAx parts were drivers and boards. With CDNA3, AMD is promising to radically change that paradigm and you have chiplets to thank. The promise was to put x86 cores on the GPU itself along with Xilinx FPGAs. This is nothing less than a fundamental rethink of what a compute bound GPU is meant to be and you have to question whether it needs a host CPU/server anymore. If you have x86 cores, FPGAs, and GPU shaders, other than a boot ROM and I/O, what do you need those external CPUs for again?
The claims of much higher FP64 and mixed precision math performance than the original CDNA are easy to justify, AMD is actually paying attention to compute in hardware this time around. They also make broad claims against an Nvidia A100 accelerator but between our lack of faith in their numbers and the massive marketshare AMD seems to not be taking with the current product line, call us skeptical that these claims will translate to usable real world performance. In short we will believe it when people in the field use it, something that isn’t happening at the moment.
On the GPU side it is fair to say that the hardware will undergo a sea change in architecture. GPUs will move to chiplets for the first time and the compute variants will go even more toward a self-contained system with CPUs and FPGAs on platform. The same flexibility to serve differing markets with differing IP that benefits AMD on the CPU side will aid their GPU efforts from here on out. Someday maybe the software will catch up too.S|A
Note: Part 2 Tomorrow
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024