![]() Cavium has come out with a new generation of their Octeon MIPS CPU line called Octeon III. This new version is faster, more efficient, and has a bunch of interesting accelerators under the hood.
Cavium has come out with a new generation of their Octeon MIPS CPU line called Octeon III. This new version is faster, more efficient, and has a bunch of interesting accelerators under the hood.
The basic Octeon family ranges from 1-48 64-bit MIPS cores that are custom Cavium designs, not licensed cores. Since the mainstay of Cavium’s business is high-end switches and routers, this is all connected by a very complex and high-speed bus. With each new iteration of the Octeon line there are more and wider busses, faster I/O, and more complex and powerful accelerators tacked on to the SoC. Lets take a look at the new 1-4 core version of the Octeon III family called CN70xx.
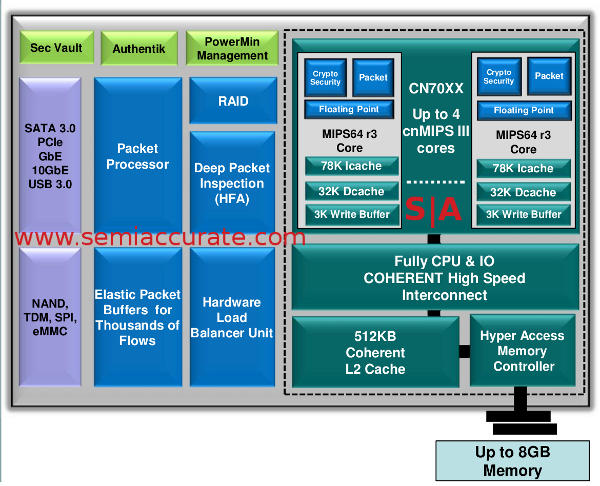
The diagram of the SoC block by block
Even at the high level overview provided there are some very interesting features visible on this chip. For CPU cores there are between one and four MIPS64 r3 cores with 78K of Icache and 32K of Dcache plus a 3K write buffer. This Icache is doubled in size from the Octeon II as is its associativity. More importantly the cores now have a full FP unit that the previous generations all lacked. This may seem like an important addition but most of what these cores do is bit shuffling and pattern matching, all things firmly rooted in the integer world. Both the L1 and 512K L2 run at full core speed, and the L2 is fully coherent.
From there all the data goes out to the bus and this is where things stand out from normal CPUs and SoCs. This bus is not just full width it also runs at full core clocks. If you think about what these SoCs are designed to do, this is not an optional extra it is the heart of the system and it has to be fast. To support this the memory controller is all new as well and notably faster than before. It now supports up to 8GB of external RAM, Cavium did not specify the types though. Overall the core is a claimed 25% faster than that in the Octeon II clock for clock.
Stepping outside the cores and related caches, the first thing to take note of is the Elastic Packet Buffer. These are more complex than they sound and are also far more than mere buffers. The EPB has it’s own MMU and can allocate buffers like a CPU can. This allows full DMAs from just about anywhere without CPU intervention. If you know how CPUs work and how much time it takes to service an interrupt, this can be the difference between smooth low latency packet flows and choking on slow streams.
Right next to this is another key feature that can mean the difference between flows and congestion, a hardware load balancer. This may not seem all that important until you consider the overhead involved with servicing thousands of streams all crying out for the attention of a CPU or accelerator. This little block likely more than makes up for any die area used by increasing system performance. It also allows for some very granular QoS options and virtualization.
The packet processor and RAID blocks are just what they seem, TCP/IP offload and packet processing for network oriented versions of the CN70xx chips and hardware RAID for NAS oriented versions. Both are improved over the older versions and while indispensable are not exactly new or exciting. Think of these as functional necessities for any SoC in this class. Also do note that each MIPS core has it’s own dedicated packet processing block in addition to the SoC version.
Last but by no means least is the Deep Packet Inspection (DPI) hardware block, something that is new to SemiAccurate and quite unexpected in this class of device. DPI is exactly what it sounds like, it lets you look in to packet at a far higher level of the OSI stack, potentially all the way up to layer 7 if you want to spend the CPU power that way. DPI is often used for great evil by entities like cable providers and the copyright MAFIAA but is becoming more and more necessary in the security field. Some types of attacks almost mandate DPI to catch, the more you can cloak the malware the deeper you have to look to find it. While it is possible to use DPI for user antagonistic functions, in this class of device it is unlikely to be used that way.
The crypto accelerators in the cores and uncore both are better than before with more protocols supported and all the usual claims. That isn’t to make light of these blocks, Cavium claims they can encrypt and decrypt packets at full wire speeds. This may be a bit tough with a 10GbE line coming in to the box but the 1.7Gbps needed for two 802.11ac plus one 802.11n module is quite believable. In any case a few 802.11ac radios pulling encrypted traffic in, decrypting it, scanning the contents, and then re-encrypting the results before sending them on their way should be eminently doable. In a corporate setting both encryption and scanning are becoming mandatory and the level of hardware needed to pull this off without undue latency or throttling throughput has risen accordingly.
One last thing to note about the SoC is that this version is fully virtualized with full KVM, Linux Containers, and LibVirt support. It may seem odd to have a router or NAS SoC running a full-blown VM but it makes sense for two reasons. First is to hard separate processes from multiple tenants, a necessity in many markets like telecom equipment. Their customers tend to demand hard separation so the telcos demand it from their vendors. Another good use for this feature is to have a second copy of the OS and software running in a separate VM for very quick failover. Once again in the carrier space and some infrastructure settings, this kind of fast failover is almost mandatory. On top of these two there is always a need for a remote management partition, a nice thing to have but mostly unnecessary if the primary OS is well-behaved.
This level of performance and features usually requires quite a bit of energy to pull off, and Cavium claims to be an exception to this rule. They take power management seriously eve claiming the Octeon III can change frequency on a clock cycle basis, something we find a bit pointless even if it is technically possible. This does not involve voltage changes but it is still impressive.
The CN70xx Octeon III chips are built on a 28nm process, as good as you can get for the time being. Cavium claims the entire SoC will pull between 2.5W and 7W for one core at 800MHz and four cores at 1.6GHz respectively. If you have one core at a given TDP, each additional core will only add .5W at the maximum clock of 1.6GHz. This is a pretty nice performance per watt figure and also shows you how much of the work is being done by the core vs the uncore of the Octeon III SoC. As a technical side note the cores will run up to 2.5GHz with ease but the current packaging limits it to 1.6GHz for thermal dissipation reasons. If you want to buy a lot of Octeon IIIs at a clock higher than 1.6GHz, Cavium can very likely accommodate that request should your checks clear in a timely fashion.
All of this means that the same 3-7W envelope that the previous 65nm CN60xx Octeon II SoC could run two cores at 1GHz in allows the CN70xx have four cores at 1.6GHz. Cavium claims more than 3x the performance at the same TDP or 1/3 the energy use at the same performance as the Octeon II. This may seem like a pedantic number to be arguing over but many of the intended markets have wattage limits defined by POE and that means a very tight wattage window for the silicon.
So now that you have a decent idea of what an Octeon III is, you might be wondering why you would want one of these chips. Cavium has a bunch of scenarios where this added power and DPI capabilities make a lot of sense, real use cases not some made up corner case. Most of them involve the so called edge switches, essentially the last thing on the network before an end-user device. With Wi-Fi spreading rapidly and BYOD becoming more common in corporate settings, security is paramount. The old way of centralizing security scanning doesn’t cut it when there are dozens of paths deep inside the network for threats to pop up on. Decentralized initial security is an absolute necessity.
Without getting in to a long discussion on security or lack thereof, lets just say the modern threat landscape is more varied than it has ever been. BYOD multiplies this by another large factor, OSes, software versions, and various patch levels make life far tougher still. DPI and edge scanning are the only way to have a semblance of security in a BYOD world and all this has to be done at wire speeds. And within the POE wattage limits. This is not an easy job to do at 1.7Gbps 802.11ac transfer rates.
Cavium is targeting enterprise gateways, service provider gateways, NAS boxes, and some security appliances with the Octeon III. To make life easy for a potential OEM, the company has a complete top to bottom software stack that includes things like MonteVista Carrier Grade Edition Linux, source included. They offer turnkey solutions for all of the categories above, all an OEM or customer needs to do is customize it to their liking if they so choose. If not they can just slap a logo on it and off you go.
Since most of the offering are based on a standard Linux platform and are fully open, it couldn’t be any easier. This comprehensive software stack, from NASes to carrier grade solutions, is what separates Cavium from the rest of the herd. If you have ever looked at the cost figures associated with rolling your own software suite, the cost of Cavium silicon pales in comparison. The toolkits and app dev kits are just bonuses, quite valuable bonuses in fact.

No points if you figure out who the OEM is for this device
At Computex Cavium was showing off a enterprise wireless router reference design. The board above is a pre-silicon dev platform with an Octeon II mounted on a pin-compatible interposer board. Since the Octeon II and III are fully software compatible any potential customers can get their dev work started long before actual silicon comes back from the fabs. Coupled with a Cavium controlled and provided software and tools suite, this should make porting to the Octeon III once hardware becomes available about as simple as possible. It is probably just a simple compiler switch change.
With power use levels firmly in the POE envelope and performance sufficient for more than two 801.11AC streams at wire speeds, the Octeon III seems to be a good solution for complex edge routing and security needs. CN70xx silicon is sampling widely this quarter and full production follows in Q4. With luck you can probably get an Octeon III based device by CES for all your post-holiday wireless edge DPI needs.S|A
Have you signed up for our newsletter yet?
Did you know that you can access all our past subscription-only articles with a simple Student Membership for 100 USD per year? If you want in-depth analysis and exclusive exclusives, we don’t make the news, we just report it so there is no guarantee when exclusives are added to the Professional level but that’s where you’ll find the deep dive analysis.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Qualcomm Is Cheating On Their Snapdragon X Elite/Pro Benchmarks - Apr 24, 2024
- What is Qualcomm’s Purwa/X Pro SoC? - Apr 19, 2024
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024